
英文文档地址:http://jmeter.apache.org/usermanual/component_reference.html
目录:
18 导言
少数测试元件使用JMeter属性来控制它们的行为。这些属性通常在类被加载时解析。这通常发生在测试计划执行前,所以不能通过__setProperty()函数来改变设置。
18.1 取样器
取样器执行JMeter实际的工作。每个取样器( 测试活动 除外)生成一个或多个样本结果。样本结果具有各种属性(成功/失败,经过时间,数据大小等),并且可以在各种监听器中查看。
FTP请求
此控制器允许您将FTP“检索文件”或“上传文件”的请求发送到FTP服务器。如果要将多个请求发送到同一FTP服务器,请考虑使用FTP默认请求配置元件,这样您就不必为每个FTP请求生成控制器输入同样的信息。下载文件时,它可以存储在磁盘(本地文件)或响应数据中,或两者都存储。
延迟设置为登录所需的时间。
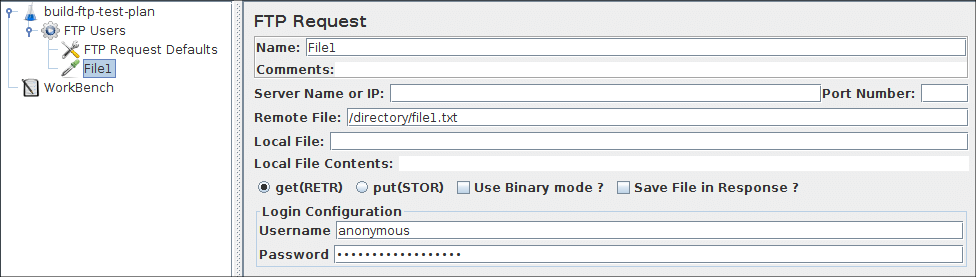
FTP请求控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 服务器名称或IP | FTP服务器的域名或IP地址。 | 是 |
| 端口 | 使用的端口。如果此值>0,则使用此特定端口,否则JMeter使用默认FTP端口。 |
否 |
| 远程文件 | 要检索的文件或要上传的目标文件的名称。 | 是 |
| 本地文件 | 要上传的或下载的目标文件(默认为远程文件名)。 | 是,如果上传 |
| 本地文件内容 | 提供上传内容,覆盖本地文件属性。 | 是,如果上传 |
| get(RETR) / put(STOR) | 是否检索或上传文件。 | 是 |
| 使用二进制模式? | 选中此项以使用二进制模式(默认ASCII) | 是 |
| 保存文件响应? | 是否将检索到的文件的内容存储在响应数据中。如果模式为ASCII,则内容将在查看结果树中可见。 | 是,如果下载 |
| 用户名 | FTP帐户用户名。 | 通常是 |
| 密码 | FTP帐户密码。注意这在测试计划中是可见的。 | 通常是 |
另请参阅:
HTTP请求
此取样器允许您将HTTP/HTTPS请求发送到Web服务器。它还允许您控制JMeter解析HTML文件是否包含图像和其他内含的资源,并发送HTTP请求以检索它们。以下类型的内含的资源将被检索:
- 图片
- 小程序
- 样式表(CSS)和从这些文件引用的资源
- 外部脚本
- frames,iframes
- 背景图像(body,table,TD,TR)
- 背景声音
默认解析器是org.apache.jmeter.protocol.http.parser.LagartoBasedHtmlParser。可以通过“ htmlparser.className” 属性来变更 - 详细信息请参阅jmeter.properties。
如果要将多个请求发送到同一Web服务器,请考虑使用HTTP请求默认值配置元件,这样您就不必为每个HTTP请求输入相同的信息。
或者,您可能希望使用JMeter的HTTP代理服务器来创建它们,而不是手动添加HTTP请求。如果您有大量或者包含许多参数的HTTP请求,这可以节省您的时间。
有两种不同的测试元件用于定义取样器:
AJP/1.3 取样器
使用Tomcat mod_jk协议(在AJP模式下不需要Apache httpd就可以测试Tomcat)。AJP取样器不支持多文件上传;只有第一个文件会被上传。
HTTP请求
这有一个实现下拉框,它选择要使用的HTTP协议实现:
Java
使用JVM提供的HTTP实现。与HttpClient实现相比,它有一些限制 - 见下文。
HTTPClient4
使用Apache HttpComponents HttpClient 4.x。
- 空值
不设置HTTP取样器的实现方式,所以依赖于HTTP请求默认值(如果存在)或根据jmeter.properties中定义的jmeter.httpsampler属性。
Java HTTP实现有一些限制:
- 无法控制连接的重用方式。当JMeter释放连接时,它可能会也可能不会被同一个线程重用。
- 此API最适合单线程使用 - 各种设置通过系统属性来定义,因此适用于所有连接。
- 不支持Kerberos身份验证。
- 不支持使用Keystore Config进行基于客户端的证书测试。
- 重试机制更方便控制。
- 不支持虚拟主机。
- 仅支持以下方法:
GET,POST,HEAD,OPTIONS,PUT,DELETE和TRACE。 - 通过DNS缓存管理器能够更好地控制DNS缓存
注意:
FILE协议仅用于测试目的。无论使用哪个HTTP取样器,它都由相同的代码处理。
如果请求需要服务器或代理登录授权(即浏览器将创建弹出对话框),则还必须添加HTTP授权管理器配置元件。对于正常登录(即用户在表单中输入登录信息),您需要确定表单提交按钮的作用,并使用适当的方法(通常是POST)和表单定义中的相应的参数创建HTTP请求。如果页面使用HTTP,则可以使用JMeter代理捕获登录序列。
每个线程使用单独的SSL上下文。如果要共用一个SSL上下文(不是浏览器的标准行为),请设置JMeter属性:
https.sessioncontext.shared=true
默认情况下,从5.0版开始,SSL线程在线程组迭代期间保留,并在每次测试迭代时重置。如果在您的测试计划中同一个用户迭代多次,那么您应该将其设置为false。
httpclient.reset_state_on_thread_group_iteration=true
注意:这不适用于Java HTTP实现。
JMeter默认SSL协议级别为TLS。如果服务器需要不同的级别,例如SSLv3,可以修改JMeter属性,例如:
https.default.protocol=SSLv3
JMeter还允许修改https.socket.protocols属性来启用其他协议。
如果请求使用cookies,那么您还需要一个HTTP Cookie管理器。您可以将这些元件添加到线程组或HTTP请求下。如果您有多个需要授权或使用cookies的HTTP请求,请将元件添加到线程组下。这样,所有HTTP请求控制器将共享相同的授权管理器和Cookie管理器。
如果请求使用“URL重写”技术来保持会话,请参阅 6.1使用URL重写处理用户会话获取其他配置步骤。
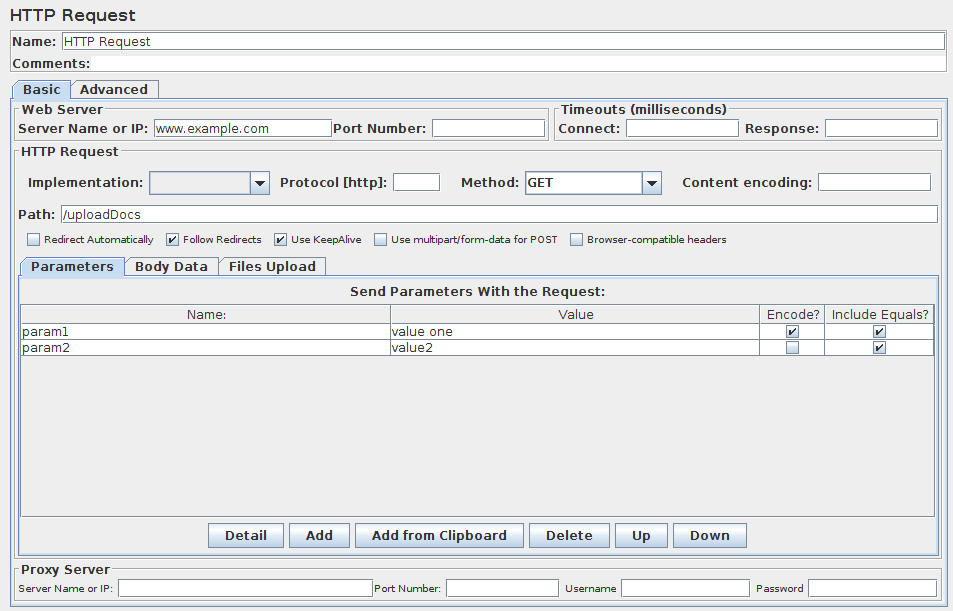
HTTP请求控制面板的截图
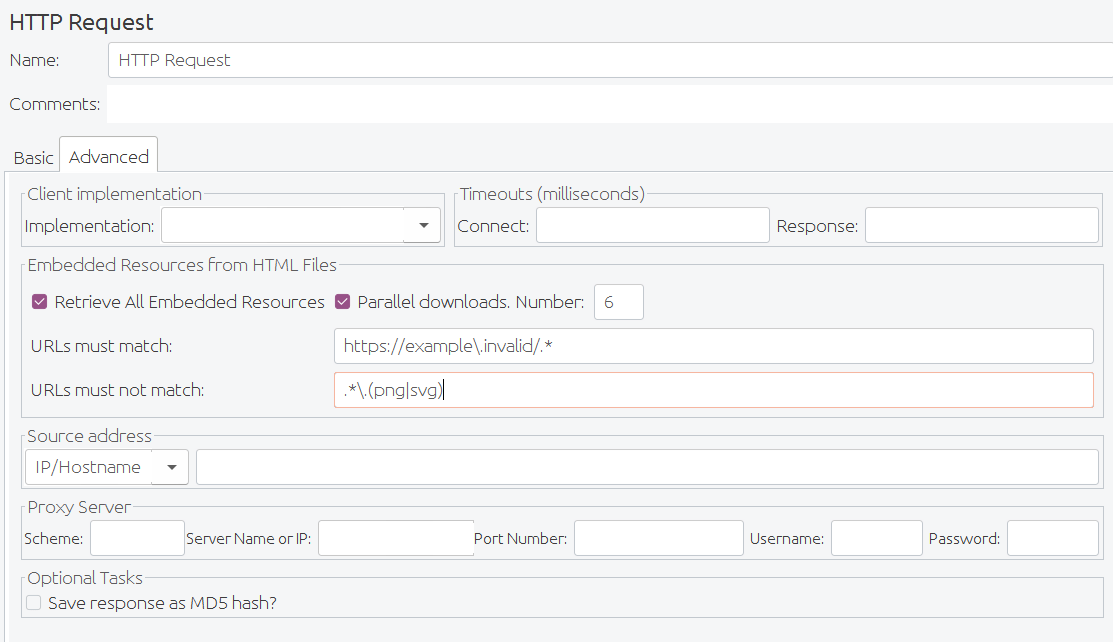
HTTP请求高级配置字段
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 服务器名称或IP | web服务器的域名或IP地址,例如www.example.com。【不要包含http://前缀。】注意:如果在信息头管理器中定义了“Host”信息头,则将其用作虚拟主机名。服务器是必需的,除非: |
否 |
| 端口 | Web服务器监听的端口号。默认为:80 |
否 |
| 连接超时 | 连接超时。等待连接开启的毫秒数。 | 否 |
| 响应超时 | 响应超时。等待响应的毫秒数。请注意,这适用于每次等待响应。如果服务器响应以多个块发送,则总体经过的时间可能比超时时间长。 断言持续时间可以用于检测需要很长时间才能完成的响应。 |
否 |
| 服务器(代理) | 要执行请求的代理服务器的主机名或IP地址。【不要包含http://前缀。】 |
否 |
| 端口 | 代理服务器监听的端口。 | 否,除非指定了代理主机名 |
| 用户名 | (可选)代理服务器的用户名。 | 否 |
| 密码 | (可选)代理服务器的密码。(注意,它在测试计划中是没有加密存储的) | 否 |
| 实现 | Java,HttpClient4。如果没有指定(也没有通过HTTP请求默认值来定义),则默认值取决于JMeterjmeter.httpsampler属性。如果还取不到值,则使用HttpClient4实现。 |
否 |
| 协议 | HTTP,HTTPS 或FILE。默认值:HTTP。 |
否 |
| 方法 | GET,POST,HEAD,TRACE,OPTIONS,PUT,DELETE,PATCH(不支持 JAVA实现)。使用HttpClient4时,还允许以下与WebDav相关的方法:COPY,LOCK,MKCOL,MOVE, PROPFIND,PROPPATCH,UNLOCK,REPORT,MKCALENDAR, SEARCH。可以使用JMeter httpsampler.user_defined_methods属性为HttpClient4预定义更多方法 。 |
是 |
| 内容编码 | 要使用的内容编码(用于POST,PUT,PATCH和FILE)。这是要使用的字符编码,与HTTP的Content-Encoding信息头无关。 |
否 |
| 自动重定向 | 将基础http协议处理程序设置为自动遵循重定向,因此JMeter看不到它们,也不会显示为样本。应该只用于GET和HEAD请求。HttpClient取样器将拒绝将其用于POST或PUT的尝试。警告:有关cookie和信息头的处理,请参阅下文。 |
否 |
| 跟随重定向 | 这仅在未启用“ 自动重定向 ”时有效。如果设置,JMeter取样器将检查响应是否为重定向,如果是,则遵循它。初始重定向和进一步响应将显示为额外的样本。父样本的URL和数据字段将从最终(非重定向)样本中获取,但是父样本的字节统计和已用时间包含所有样本。延迟时间从初始响应获取。请注意,HttpClient取样器可能会记录以下消息:JMeter将在绝对和相对重定向URL中折叠“ /../segment ”形式的路径。例如,http://host/one/../two将折叠为http://host/two。如有必要,可以通过设置JMeter属性httpsampler.redirect.removeslashdotdot=false来抑制该行为。 |
否 |
| 使用KeepAlive | JMeter设置连接:keep-alive信息头。这在默认的HTTP实现下无法正常工作,因为连接重用不在用户控制之下。它在Apache HttpComponents HttpClient实现下有效。 |
否 |
| 对POST使用multipart/form-data | 使用multipart/form-data或application/x-www-form-urlencoded 的post请求 |
否 |
| 与浏览器兼容的信息头 | 使用multipart/form-data时,会抑制Content-Type和 Content-Transfer-Encoding信息头; 仅发送Content-Disposition信息头。 |
否 |
| 路径 | 资源的路径(例如,/servlets/myServlet)。如果资源需要查询字符串参数,请将参数添加到“同请求一起发送参数”部分中。作为特殊情况,如果路径以“在这种情况下,服务器,端口和协议字段将被忽略; GET和DELETE方法下也会忽略参数。另外要注意的是,路径没有编码 - 除了用%20替换空格 - 因此可能需要对不安全的字符进行编码以避免诸如URISyntaxException之类的错误。 |
是 |
| 同请求一起发送参数 | 查询字符串将从您提供的参数列表中生成。每个参数都有一个名称和 值,还有对参数进行编码的选项,以及包含或排除等号的选项(某些应用程序在值为空字符串时不希望出现等号)。查询字符串将以正确的方式生成,具体取决于您所选择的“方法”(即,如果您选择GET或DELETE,查询字符串将附加到URL上,如果是POST或PUT,则将单独发送)。同样的,如果使用multipart形式发送文件,则将使用multipart形式规范创建查询字符串。有关参数处理的更多信息,请参见下文。此外,您可以指定是否对每个参数进行URL编码。如果您不确定这意味着什么,最好选择它。如果您的值包含如下字符,则通常需要编码:
|
否 |
| 文件名称 | 要发送的文件的名称。如果留空,JMeter将不发送文件,如果填写,JMeter会自动将请求作为multipart形式的请求发送。 如果是 POST或PUT或PATCH请求,并且只有一个文件其“参数名称”属性(见下文)被省略,则该文件将作为请求的整个消息体发送,即不添加任何封装器。这允许发送任意消息体。此功能适用于POST请求,也适用于PUT请求。 有关参数处理的更多信息,请参见下文。 |
否 |
| 参数名称 | Web请求参数“ name ”的值。 |
否 |
| MIME类型 | MIME类型(例如,text/plain)。如果它是POST或PUT或PATCH请求,并且省略了' name '属性(见下文)或者仅从参数值构造了消息体,那么该字段的值将作为content-type信息头的值。 |
否 |
| 从HTML文件获取所有内含的资源 | 告诉JMeter解析HTML文件并发送文件中引用的所有图像,Java小程序,JavaScript文件,CSS等的HTTP/HTTPS请求。请参阅下面获得更多细节。 | 否 |
| 保存响应为MD5哈希 | 如果选中此选项,则响应不会存储在样本结果中。相反,计算并存储响应数据的32位MD5哈希值。这用于测试大量数据。 | 否 |
| 网址必须匹配: | 如果选中,则必须填入正则表达式,用于与找到的所有内含的URL匹配。因此,如果您只想从http://example.com/下载内含的资源,请使用以下表达式: http://example\.com/.* |
否 |
| 并行下载 | 使用并发连接来获取内含的资源。 | 否 |
| 数量 | 用于获取内含的资源的并发连接池大小。 | 否 |
| 源地址类型 | 【仅适用于HTTPClient实现的HTTP请求】 要区分源地址值,请选择以下类型:
|
否 |
| 源地址字段 | 【仅适用于HTTPClient实现的HTTP请求】 此属性用于启用IP欺骗。它会覆盖此样本的默认本地IP地址。JMeter主机必须具有多个IP地址(即IP别名,网络接口,设备)。该值可以是主机名,IP地址或网络接口设备,例如“ eth0”或“lo”或“wlan0”。如果定义了属性 httpclient.localaddress,则用于所有HttpClient请求。 |
否 |
使用自动重定向时,仅对初始URL发送cookies。这可能会导致重定向到本地服务器的网站出现意外行为。例如,如果
www.example.com重定向到www.example.co.uk。在这种情况下,服务器可能会返回两个URL的cookies,但JMeter只会接收最后一个主机的cookies,即www.example.co.uk。如果测试计划中的下一个请求使用www.example.com,而不是www.example.co.uk,它将无法获得正确的cookies。同样的,只对初始请求发送信息头,对于重定向则不发送。通常只是手动创建的测试计划会出现这个问题,因为使用记录器创建的测试计划将从重定向的URL继续下去。
参数处理:
对于POST和PUT方法,如果没有要发送的文件,并且省略了参数的名称,则通过连接参数的所有值来创建消息体。注意这些值的连接不会添加任何行尾字符。在值字段中可以使用__char()函数来添加它们。这允许发送任意消息体。如果设置了编码标志,则对值进行编码。另请参阅上面的MIME类型,了解如何控制请求的content-type信息头。
对于其他方法,如果缺少参数的名称,则忽略该参数。这允许使用由变量定义的可选参数。
当请求只有未命名的参数(或根本没有参数)时,您可以选择切换到消息体数据选项卡。此选项在以下情况(以及其他情况)中很有用:
- GWT RPC HTTP请求
- JSON REST HTTP请求
- XML REST HTTP请求
- SOAP HTTP请求
注意一旦离开树节点,除非清除
消息体数据标签下的数据,否则无法切换回参数标签。
在消息体数据模式下,除了最后一行之外,每行发送时都将附加CRLF。要在最后一行数据之后发送CRLF,只需确保其后面有空行。(空行虽然看不到,但是可以通过观察光标是否可以放在后续行上看出。)
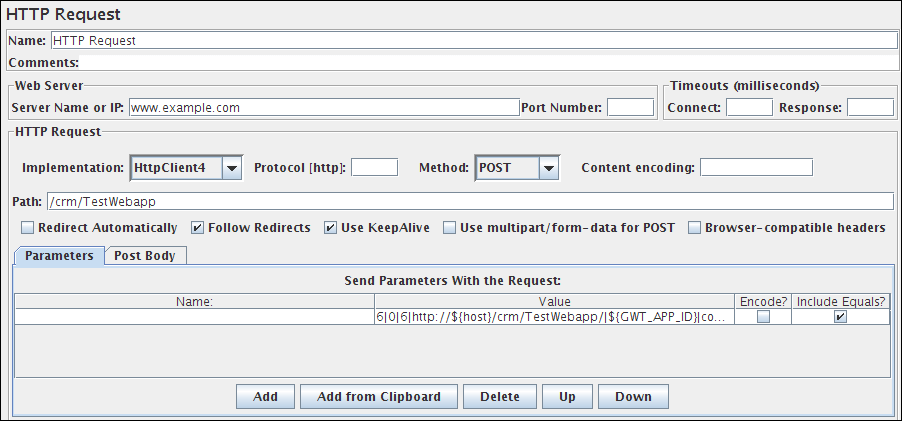
图1 - 带有一个未命名参数的HTTP请求
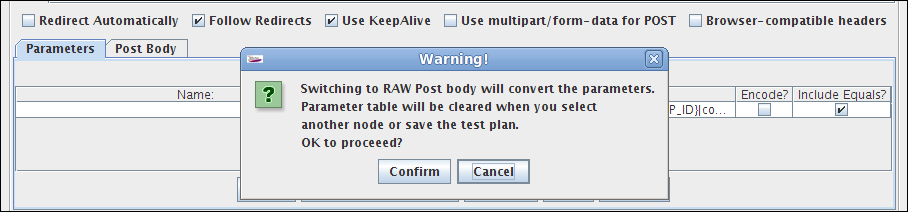
图2 - 确认要切换的对话框
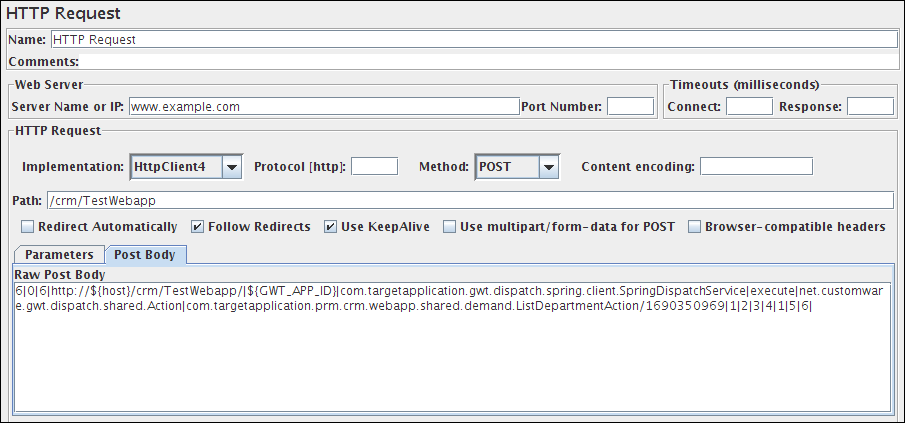
图3 - 使用消息体数据的HTTP请求
方法的处理:
GET,DELETE,POST,PUT和PATCH请求方法的工作方式类似,除了3.1版本外,只有POST方法支持multipart请求或文件上传。PUT和PATCH方法的消息体必须提供以下之一:
- 将消息体定义为具有空参数名称字段的文件;在这种情况下,MIME类型用作Content-Type
- 将消息体定义为没有名称的参数值
- 使用“
消息体数据”标签
GET,DELETE和POST方法有一种额外的参数传递方式,就是通过使用参数标签。 GET,DELETE,PUT和PATCH需要Content-Type。如果不使用文件,添加一个信息头管理器到取样器并在那里定义Content-Type。
JMeter扫描内含资源的响应。它使用HTTPResponse.parsers属性,它是一个解析器的ID列表,例如htmlParser,cssParser和wmlParser。对于找到的每个id,JMeter会检查另外两个属性:
id.types- 内容类型列表id.className- 用于提取内含资源的解析器
有关设置的详细信息,请参阅jmeter.properties文件。如果未设置HTTPResponse.parser属性,则JMeter将恢复为先前的行为,即仅扫描text/html响应。
模拟慢速连接:
HttpClient4和Java 取样器支持慢速连接的模拟;请参阅jmeter.properties中的以下条目:
# Define characters per second > 0 to emulate slow connections
#httpclient.socket.http.cps=0
#httpclient.socket.https.cps=0
然而Java取样器仅支持慢速HTTPS连接。
响应大小计算
Java实现不包括传输的开销,例如在响应消息体中的信息头部分。
HttpClient4实现包含整个响应消息体的开销,所以该值可能比在响应内容中包含的字节数更大。
重试处理
默认情况下,HttpClient4和Java实现的重试设置为0,这意味着不会尝试重试。
对于HttpClient4,可以通过设置相关的JMeter属性来设置重试次数,例如:
httpclient4.retrycount=3
使用HC4实现,默认情况下将在幂等的Http方法上进行重试。如果要重试所有方法,请设置属性
java httpclient4.request_sent_retry_enabled=true
注意Java实现在默认情况下也不会重试,您可以通过设置更改它
http.java.sampler.retries=3
注意:证书不符合算法约束
如果您在具有SSL证书(本身或其信任链中的 SSL 证书)的网站上运行HTTPS请求,该证书使用MD2的签名算法(例如md2WithRSAEncryption)或大小小于1024位,您可能会遇到以下错误:java.security.cert.CertificateException: Certificates does not conform to algorithm constraints 。
此错误与Java 8中增强的安全性有关。
要允许您执行HTTPS请求,可以通过编辑Java的jdk.certpath.disabledAlgorithms属性来降低Java安装的安全性等级。根据您的情况,删除MD2值或取消大小约束。
此属性在此文件中:
JAVA_HOME/jre/lib/security/java.security
有关详细信息,请参阅 Bug56357。
另请参阅:
- 断言
- 构建Web测试计划
- 构建高级Web测试计划
- HTTP授权管理器
- HTTP Cookie管理器
- HTTP信息头管理器
- HTML链接解析器
- HTTP代理服务器
- HTTP请求默认值
- HTTP请求和会话ID:URL重写
JDBC请求
此取样器允许您将JDBC请求(SQL查询)发送到数据库。
在使用之前,您需要设置JDBC Connection Configuration配置元件。
如果提供了“变量名称”列表,则对于Select语句返回的每一行,将使用相应列和对应的行数的值设置变量(如果提供变量名称)。例如,如果Select语句返回2行3列,并且变量列表是A,,C,则将设置以下变量:
A_#=2(行数)
A_1=第1列,第1行
A_2=第1列,第2行
C_#=2(行数)
C_1=第3列,第1行
C_2=第3列,第2行
如果Select语句返回零行,则A_#和C_#变量将设置为0,并且不会设置其他变量。
必要时清除旧变量 - 例如,如果第一个select检索到6行而第二个select仅返回3行,则额外的第4行,第5行和第6行的变量将被删除。
延迟时间设置为获取连接所花费的时间。
JDBC请求控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| name | 树中显示的此取样器的描述性名称。 | 否 |
| Variable Name of Pool declared in JDBC Connection Configuration | 连接池绑定的JMeter变量的名称。这必须与JDBC Connection Configuration的“ Variable Name ”字段一致。 |
是 |
| Query Type | 根据语句类型设置:
|
是 |
| SQL Query | SQL查询语句。不要输入语句结束的分号。通常不需要使用 {和}来封装Callable语句; 但是,如果数据库使用非标准语法,可以使用它们。如果语句封装在例如:
|
是 |
| Parameter values | 以逗号分隔的参数值列表。使用]NULL[表示NULL参数。(如果需要,可以通过定义属性"jdbcsampler.nullmarker"来更改空字符串。) 如果任何值包含逗号或双引号,则列表必须用双引号括起来,并且任何内含的的双引号都必须加倍,例如: 即使您的参数是 |
是,如果prepared或callable语句含有参数 |
| Parameter types | 以逗号分隔的SQL参数类型列表(例如INTEGER,DATE,VARCHAR,DOUBLE)或常量的整数值。当您使用驱动程序提供的自定义数据库类型时,可以使用这些整数值(例如OracleTypes.CURSOR可以用其整数值-10来表示)。这些被定义为 java.sql.Types类中的字段,参见示例:java.sql.Types的Javadoc。注意:JMeter将使用运行时JVM定义的任何类型,因此如果您在不同的JVM上运行,请务必查阅相应的文档如果callable语句具有 INOUT或OUT参数,则必须为相应的参数类型添加前缀来指示这些参数,例如,使用"INOUT INTEGER"而不是"INTEGER"。如果未指定,则假定为“ IN”,即“DATE”与“IN DATE” 相同。 如果类型不在 java.sql.Types中,JMeter也接受相应的整数,例如,由于OracleTypes.CURSOR == -10,所以您可以使用“INOUT -10”。 类型必须同语句中的占位符一样多。 |
是,如果prepared或callable语句含有参数 |
| Variable Names | 以逗号分隔的变量名列表,用于保存Select语句,Prepared Select语句或Callable语句的返回值。注意当与Callable语句使用时,变量列表必须与调用返回的OUT参数的顺序相同。如果变量名称少于OUT参数,则只有和提供变量名称相同数目的结果会存储在线程上下文变量中。如果提供比OUT参数更多的变量名称,多余的变量将被忽略。 |
否 |
| Result Variable Name | 如果指定,这将创建一个包含行映射列表的对象变量。每个映射都以列名作为键,列数据作为值。用法: |
否 |
| Query timeout(s) | 设置查询的超时秒数,空值表示0,为无限。-1表示不设置用例可能需要的任何查询超时,或者某些驱动程序不支持超时。默认值为0。 |
否 |
| Handle ResultSet | 定义如何处理从可调用语句返回的ResultSet:
|
否 |
另请参阅:
当前版本的JMeter使用UTF-8作为字符编码。以前使用平台默认值。
确保变量名称在测试计划中是唯一的。
Java请求
此取样器允许您控制实现org.apache.jmeter.protocol.java.sampler.JavaSamplerClient接口的java类 。通过编写您自己的此接口实现,您可以用JMeter来控制多个线程,输入参数控制和数据收集。
下拉菜单提供了JMeter在其classpath中找到的所有此类实现的列表。可以在下面的表中指定参数 - 由您的实现定义。JMeter提供了两个简单示例(JavaTest和SleepTest)。
JavaTest示例取样器对检查测试计划非常有用,因为它允许在几乎所有的字段设置值。这些可以被断言等使用。这些字段允许使用变量,因此可以很容易地看到这些变量的值。
Java 请求的控制面板的截图
如果
teardownTest方法未被AbstractJavaSamplerClient的子类覆盖,则不会调用其teardownTest方法。这降低了JMeter内存要求。不会对现有的测试计划产生任何影响。添加/删除按钮目前不起任何作用。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 类名称 | 要取样的JavaSamplerClient接口的具体实现。 | 是 |
| 发送带参数的请求 | 将传递给取样类的参数列表。所有参数都以字符串形式发送。请参阅下面的具体设置。 | 否 |
以下参数适用于SleepTest和JavaTest实现:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| Sleep_time | 睡眠时间(ms) | 是 |
| Sleep_mask | 添加多少“随机性”: 睡眠时间计算如下: |
是 |
以下参数适用于JavaTest实现:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| Label | 要使用的标签。如果提供,则覆盖名称 |
否 |
| ResponseCode | 如果提供,则设置SampleResult ResponseCode。 | 否 |
| ResponseMessage | 如果提供,则设置SampleResult ResponseMessage。 | 否 |
| Status | 如果提供,则设置SampleResult Status。如果它等于“OK ”(忽略大小写),则状态设置为成功,否则样本被标记为失败。 |
否 |
| SamplerData | 如果提供,则设置SampleResult SamplerData。 | 否 |
| ResultData | 如果提供,则设置SampleResult ResultData。 | 否 |
LDAP请求
此取样器允许您向LDAP服务器发送不同的LDAP请求(添加,修改,删除和搜索)。
如果要将多个请求发送到同一LDAP服务器,请考虑使用LDAP默认请求配置元件,这样您就不必为每个LDAP请求输入相同的信息。
登录配置元件也使用同样的方法发送用户名和密码。
LDAP请求控制面板的屏截图
创建测试LDAP服务器的测试用例有两种方法。
- 内置测试用例。
- 用户定义的测试用例。
测试LDAP有四种测试方案。测试方案如下:
-
添加测试
-
内置测试:
这将在LDAP服务器中添加预定义的条目并计算执行时间。执行测试后,将从LDAP服务器中删除创建的条目。
-
用户定义的测试:
这将在LDAP服务器中添加条目。用户必须输入表中的所有属性。从表中收集条目以进行添加。计算执行时间。测试后不会删除创建的条目。
-
-
修改测试
-
内置测试:
这将首先创建预定义的条目,然后修改LDAP服务器中创建的条目。并计算执行时间。执行测试后,将从LDAP服务器中删除创建的条目。
-
用户定义的测试:
这将修改LDAP服务器中的条目。用户必须输入表中的所有属性。从表中收集条目以进行修改。计算执行时间。该条目不会从LDAP服务器中删除。
-
-
搜索测试
-
内置测试:
这将首先创建条目,如果属性可用则执行搜索。计算搜索查询的执行时间。在执行结束时,将从LDAP服务器中删除创建的条目。
-
用户定义的测试:
这将搜索搜索库(同样,由用户定义)中的用户定义条目(搜索过滤)。这些条目应该在LDAP服务器中可用。计算执行时间。
-
-
删除测试
-
内置测试:
这将首先创建预定义的条目,然后将从LDAP服务器中删除。计算执行时间。
-
用户定义的测试:
这将删除LDAP服务器中的用户定义条目。这些条目应该在LDAP服务器中可用。计算执行时间。
-
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 服务器名称或IP | LDAP服务器的域名或IP地址。JMeter假定LDAP服务器正在监听默认端口(389)。 |
是 |
| 端口 | 要连接的端口(默认为389)。 |
是 |
| 根DN | 用于LDAP操作的基本DN | 是 |
| 用户名 | LDAP服务器用户名。 | 通常是 |
| 密码 | LDAP服务器密码。(注意,这在测试计划中没有加密存储) | 通常是 |
| DN入口 | 要创建或修改的上下文的名称;可能不为空。您必须自己设置对象的正确属性。因此,如果要添加 |
是,如果选择了用户定义的测试和添加测试或修改测试 |
| 删除 | 要删除的上下文的名称;可能不为空 | 是,如果选择了用户定义的测试和删除测试 |
| Search base | 要搜索的上下文或对象的名称 | 是,如果选择了用户定义的测试和搜索测试 |
| 搜索过滤器 | 用于搜索的过滤器表达式;可能不为空 | 是,如果选择了用户定义的测试和搜索测试 |
| 添加测试 | 使用name,value键值对在给定上下文中创建新对象 |
是,如果选择了用户定义的测试和添加测试 |
| 修改测试 | 使用name,value键值对来修改给定的上下文对象 |
是,如果选择了用户定义的测试和修改测试 |
另请参阅:
LDAP扩展请求
此取样器可以将所有8个不同的LDAP请求发送到LDAP服务器。它是LDAP取样器的扩展版本,因此配置起来比较困难,但可以更接近真实的LDAP会话。
如果要将多个请求发送到同一LDAP服务器,请考虑使用LDAP扩展请求默认值配置元件,这样您就不必为每个LDAP请求输入相同的信息。
LDAP扩展请求控制面板的截图
定义了九个测试操作。这些操作如下:
线程绑定
任何LDAP请求都是LDAP会话的一部分,因此首先要做的是启动与LDAP服务器的会话。使用线程绑定启动此会话,这相当于LDAP的“bind”操作。要求用户提供username(专有名称)和password,用于启动会话。如果未指定密码或密码错误,则会启动匿名会话。注意,省略密码不会使此测试失败,错误密码才会。(注意,它在测试计划中是没有加密存储的)
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 服务器名称 | LDAP服务器的名称(或IP地址)。 | 是 |
| 端口 | LDAP服务器监听的端口号。如果省略,则JMeter假定LDAP服务器正在监听默认端口(389)。 |
否 |
| DN | 用于任何后续操作的基本对象的可分辨名称。它可以用作所有操作的起点。您无法在比此DN更高的级别上启动任何操作! | 否 |
| Username | 要绑定的用户的完整可分辨名称。 | 否 |
| Password | 上述用户的密码。如果省略,将导致匿名绑定。如果不正确,则取样器将返回错误并恢复为匿名绑定。(注意,这在测试计划中是没有加密存储的) | 否 |
| Connection timeout (in milliseconds) | 连接超时时间,如果超时连接将中止 | 否 |
| Use Secure LDAP Protocol | 使用ldaps://方案而不是ldap:// |
否 |
| Trust All Certificates | 信任所有证书,仅在选中Use Secure LDAP Protocol时使用 |
否 |
线程解绑
这只是结束会话的操作。它等于LDAP“unbind”操作。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
单绑定/解绑
这是LDAP“bind”和“unbind”操作的组合。它可用于任何用户的身份认证请求/密码检查。它将打开一个新会话,只是为了检查用户/密码组合的有效性,并再次结束会话。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| Username | 要绑定的用户的完整可分辨名称。 | 是 |
| Password | 上述用户的密码。如果省略,将导致匿名绑定。如果不正确,则取样器将返回错误。(注意,这在测试计划中是没有加密存储的) | 否 |
重命名条目
这是LDAP“moddn”操作。它可用于重命名条目,也可用于将条目或完整子树移动到LDAP树中的其他位置。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| Old entry name | 相对于线程绑定操作中给定的DN,要重命名或移动的对象的当前可分辨名称。 | 是 |
| New distinguished name | 相对于线程绑定操作中给定的DN,要重命名或移动的对象的新的可分辨名称。 | 是 |
添加测试
这是LDAP“add”操作。它可用于将任何类型的对象添加到LDAP服务器。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| DN入口 | 相对于线程绑定操作中的给定DN,要添加的对象的可分辨名称。 | 是 |
| 添加测试 | 要用于对象的属性及其值的列表。如果需要添加多值属性,则需要将相同的属性及其各自的值多次添加到列表中。 | 是 |
删除测试
这是LDAP“delete”操作,它可用于从LDAP树中删除对象。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 删除 | 相对于线程绑定操作中的给定DN,要删除的对象的可分辨名称。 | 是 |
搜索测试
这是LDAP“search”操作,用于定义搜索。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| Search base | 相对于线程绑定操作中的给定DN,您希望搜索查找的子树的可分辨名称。 | 否 |
| Search Filter | 搜索过滤必须在LDAP语法中指定。 | 是 |
| Scope | 使用0代表baseobject,1为onelevel和2为subtree的搜索。(默认=0) |
否 |
| 大小限制 | 指定要从服务器返回的最大结果数。(默认值=0,表示没有限制)当取样器达到最大结果数时,它将失败并返回错误代码4 |
否 |
| Time Limit | 指定服务器在搜索上花费的最大(cpu)时间(以毫秒为单位)。注意这不是响应时间。(默认为0,表示没有限制) |
否 |
| 属性 | 指定要返回的属性,以分号分隔。空值将返回所有属性 | 否 |
| Return object | 返回(true)或不返回(false)对象。默认=false |
否 |
| 废弃的别名 | 如果为true,它将废弃别名,如果为false,则不会废弃(默认值=false) |
否 |
| Parse the search results? | 如果为true,则搜索结果将添加到响应数据中。如果为false,则将标记 - 无论结果是否找到 - 添加到响应数据中。 |
否 |
修改测试
这是LDAP“modify”操作。它可以用于修改对象。也可用于添加,删除或替换属性的值。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| DN入口 | 相对于线程绑定操作中的给定DN,要修改的对象的可分辨名称 | 是 |
| 修改测试 | 属性-值-opCode三角。opCode可以是任何有效的LDAP operationCode(add,delete/remove或replace)。如果未指定delete操作的值,则将删除给定属性的所有值。如果指定了delete操作的值,则仅删除给定值。如果该值不存在,取样器返回失败。 |
是 |
比较
这是LDAP“compare”操作。它可用于将给定属性的值与某个已知值进行比较。实际上,这主要用于检查某个人是否是某个组的成员。在这种情况下,您可以将用户的DN作为给定值与groupOfNames对象的“member”属性中的值进行比较。如果比较操作失败,则测试失败并返回错误代码49。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| DN入口 | 相对于线程绑定操作中的给定DN,要比较属性的对象的当前可分辨名称。 | 是 |
| 比较过滤器 | 格式为"attribute=value" |
是 |
另请参阅:
Access Log Sampler
AccessLogSampler旨在读取访问日志并生成http请求。对于那些不熟悉访问日志的人来说,它是Web服务器记录它接受的每个请求的日志。这意味着所有图像,CSS文件,JavaScript文件,html文件,......
Tomcat的访问日志使用通用格式。这意味着使用通用日志格式的任何Web服务器都可以使用AccessLogSampler。使用通用日志格式的服务器包括:Tomcat,Resin,Weblogic和SunOne。常见的日志格式如下所示:
127.0.0.1 - - [21/Oct/2003:05:37:21 -0500] "GET /index.jsp?%2Findex.jsp= HTTP/1.1" 200 8343
解析器的当前实现仅查看包含HTTP协议方法的引号内的文本(
GET,PUT,POST,DELETE,...)。其他所有都被剥离并忽略。例如,解析器完全忽略响应代码。
对于将来,过滤出响应代码不是200的条目可能会更好。扩展取样器应该相当简单。您必须实现两个接口:
org.apache.jmeter.protocol.http.util.accesslog.LogParserorg.apache.jmeter.protocol.http.util.accesslog.Generator
AccessLogSampler的当前实现使用生成器来创建新的HTTP取样器。服务器名称,端口和获取图像由AccessLogSampler设置。然后,使用整数1调用解析器,告诉它解析1个条目。之后,调用HTTPSampler.sample()来发出请求。
samp = (HTTPSampler) GENERATOR.generateRequest();
samp.setDomain(this.getDomain());
samp.setPort(this.getPort());
samp.setImageParser(this.isImageParser());
PARSER.parse(1);
res = samp.sample();
res.setSampleLabel(samp.toString());
LogParser中所需的方法是:
setGenerator(Generator)parse(int)
实现Generator接口的类应该为所有方法提供具体的实现。有关如何实现任一接口的示例,请参阅 StandardGenerator和TCLogParser。
Access Log Sampler控制面板的截图
(Beta代码)
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| Server | Web服务器的域名或IP地址。 | 是 |
| Protocol | 方案 | 否(默认为http) |
| Port | Web服务器监听的端口。 | 否(默认为80) |
| Log parser class | 负责解析日志的日志解析器类。 | 是(默认提供) |
| Filter | 用于过滤掉某些行的过滤器类。 | 否 |
| Location of log file | 访问日志文件的位置。 | 是 |
TCLogParser为每个线程独立处理访问日志。SharedTCLogParser和OrderPreservingLogParser共享访问文件,即每个线程获取日志中的下一个条目。
SessionFilter旨在跨线程处理cookies。它不会过滤掉任何条目,但会修改cookie管理器,以便一次一个线程处理给定IP的cookies。如果两个线程尝试处理来自相同客户端IP地址的样本,则将强制一个线程等待直到另一个线程完成。
LogFilter旨在允许通过文件名和正则表达式来过滤访问日志条目,以及允许替换文件扩展名。但是,目前无法通过GUI进行配置,因此无法真正使用它。
BeanShell取样器
此取样器允许您使用BeanShell脚本语言编写取样器。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223 Sampler+Groovy以提高性能,支持新的Java功能且减少BeanShell库的维护。
测试元件支持ThreadListener和TestListener接口方法。这些必须在初始化文件中定义。有关定义的示例,请参阅文件BeanShellListeners.bshrc。
BeanShell取样器还支持Interruptible接口。interrupt()方法可以在脚本或初始化文件中定义。
BeanShell 取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。该名称存储在脚本变量Label中 |
否 |
| 每次调用前重置bsh.Interpreter | 如果选中此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。这适用于脚本文件;对于GUI中定义的脚本,您可以在脚本本身中使用所需的任何变量和函数引用。参数存储在以下变量中:Parameters:包含参数的字符串,作为单个变量bsh.args:包含参数的字符串数组,在空格处分割 |
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。文件名存储在脚本变量FileName中 |
否 |
| 脚本 | 要运行的BeanShell脚本。返回值(如果不为null)存储为取样器结果。 |
是(除非提供脚本文件) |
注意每个取样器实例都有自己的BeanShell解释器,而取样器只能被单个线程调用
如果定义了“beanshell.sampler.init”属性,则将其作为源文件的名称传递给解析器。这可以用于定义常用方法和变量。bin目录中有一个示例init文件:BeanShellSampler.bshrc。
如果提供了脚本文件,将使用该脚本文件,否则将使用脚本。
在将脚本字段传递给解释器之前,JMeter处理函数和变量的引用,因此引用只会被解析一次。脚本文件中的变量和函数引用将逐字传递给解释器,这可能会导致语法错误。为了使用运行时变量,请使用适当的props方法,例如
props.get("START.HMS");props.put("PROP1","1234");
BeanShell目前不支持Java 5语法,例如泛型和增强的for循环。
在调用脚本之前,BeanShell解释器会设置一些变量:
参数字段的内容放入变量“Parameters”中。该字符串也使用单个空格作为分隔符拆分为单独的标记,并将结果列表存储在字符串数组bsh.args中。
可设置的BeanShell变量的完整列表如下:
-
log- 日志记录器 -
Label- 取样器标签 -
FileName- 文件名(如果有) -
Parameters- 参数字段中的文本 -
bsh.args- 参数,按上面描述的拆分 -
SampleResult- 指向当前SampleResult的指针 -
ResponseCode- 默认为200 -
ResponseMessage- 默认为“OK” -
IsSuccess- 默认为true -
ctx- JMeter上下文 -
vars- JMeter变量 - 例如:vars.get("VAR1"); vars.put("VAR2","value"); vars.remove("VAR3"); vars.putObject("OBJ1",new Object());
-
props- JMeter属性(java.util.Properties类) - 例如:props.get("START.HMS"); props.put("PROP1","1234");
脚本完成后,控制权返回给取样器,并将以下脚本变量的内容复制到SampleResult中的相应变量中:
ResponseCode- 例如200ResponseMessage- 例如“OK”IsSuccess-true或false
SampleResult和ResponseData根据脚本的返回值来设置。如果脚本返回null,则可以使用方法SampleResult.setResponseData(data)直接设置响应,其中data是String或byte数组。data类型默认为“text”,但可以通过SampleResult.setDataType(SampleResult.BINARY)方法设置为二进制值 。
SampleResult变量给予脚本对SampleResult内所有字段和方法完全的访问权限。例如,脚本可以访问setStopThread(boolean)和setStopTest(boolean)方法。这是一个简单的(不是很有用)示例脚本:
if (bsh.args[0].equalsIgnoreCase("StopThread")) {
log.info("Stop Thread detected!");
SampleResult.setStopThread(true);
}
return "Data from sample with Label "+Label;
//or
SampleResult.setResponseData("My data");
return null;
另一个例子:
确保在jmeter.properties中定义属性beanshell.sampler.init=BeanShellSampler.bshrc。以下脚本将显示ResponseData字段中所有变量的值:
return getVariables();
有关各种类可用方法的详细信息(JMeterVariables,SampleResult等),请查阅Javadoc或源代码。但要注意,滥用任何方法都可能导致难以发现的细微错误。
JRS223取样器
JSR223取样器允许使用JSR223脚本代码来执行一个样本或创建/更新变量所需的一些计算。
如果您不想在运行此取样器时生成SampleResult,请调用以下方法:
SampleResult.setIgnore();
JSR223测试元件具有可以显著提高性能的功能(编译)。要利用这个特性,请:
-
使用脚本文件而不是内联它们。如果ScriptEngine上有此功能,JMeter将编译并缓存它们。
-
或者使用脚本文本并检查
Cache compiled script if available属性。使用此功能时,请确保您的脚本代码不直接在代码中使用JMeter变量而是使用脚本参数,因为缓存只会缓存第一次替换。
要从缓存和编译中受益,用于脚本编写的语言引擎必须实现JSR223Compilable接口(Groovy就是其中之一,java,beanshell和javascript都不是)
当使用Groovy作为脚本语言并且不检查
Cache compiled script if available时(建议使用缓存),由于版本2.4.6中的Groovy内存泄漏问题,您应该设置JVM属性-Dgroovy.use.classvalue=true,请参阅:
缓存大小由以下JMeter属性(jmeter.properties)控制:
jsr223.compiled_scripts_cache_size=100
与BeanShell取样器不同,解释器不会在调用之间保存。
如果脚本引擎支持此功能,使用脚本文件或脚本文本+检查
Cache compiled script if available的JSR223测试元件将执行编译,这可以实现性能的显著提升。
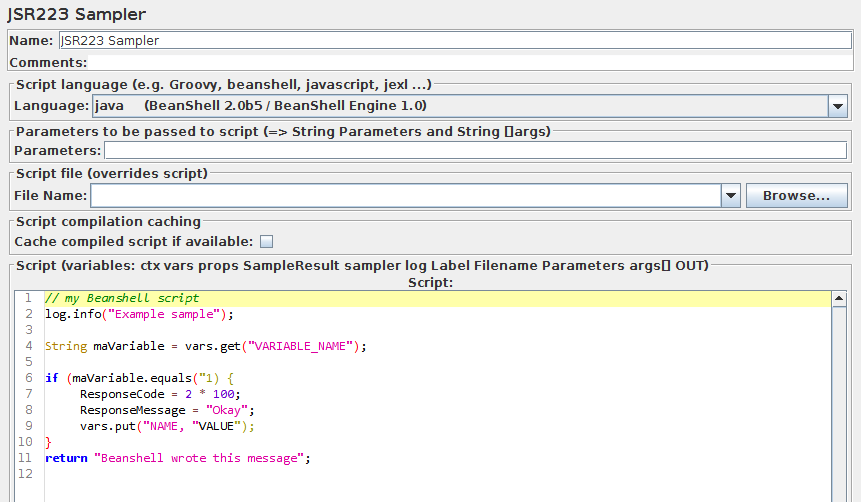
JSR223取样器控制面板的截图
在将脚本字段传递给解释器之前,JMeter处理函数和变量的引用,因此引用只会被解析一次。脚本文件中的变量和函数引用将逐字传递给解释器,这可能会导致语法错误。为了使用运行时变量,请使用适当的props方法,例如
props.get("START.HMS"); props.put("PROP1","1234");
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 脚本语言 | 要使用的JSR223脚本语言的名称。支持的语言比下拉列表中显示的要多。如果在JMeter lib目录中安装了相应的jar,则可使用相应的语言。 |
是 |
| 脚本文件 | 要用作JSR223脚本的文件的名称,如果使用文件的相对路径,则它将使用相对于系统属性“user.dir” 所引用的目录 |
否 |
| 参数 | 要传递给脚本文件或脚本的参数列表。 | 否 |
| 缓存编译脚本(如果可用) | 如果选中(建议)并且使用的语言支持Compilable接口(Groovy就是其中之一,java,beanshell和javascript都不是),JMeter将编译并缓存脚本,且使用它的MD5哈希值作为唯一缓存密钥 | 否 |
| 脚本 | 要传递给JSR223语言的脚本 | 是(除非提供脚本文件) |
如果提供了脚本文件,则使用该脚本文件,否则使用脚本。
在调用脚本之前,会设置一些变量。请注意,这些是JSR223变量 - 即它们可以直接在脚本中使用。
-
log- 日志记录器 -
Label- 取样器标签 -
FileName- 文件名(如果有) -
Parameters- 参数字段中的文本 -
args- 参数,按照上面描述的拆分 -
SampleResult- 指向当前SampleResult的指针 -
sampler- (Sampler) - 指向当前取样器的指针 -
ctx- JMeter上下文 -
vars- JMeter变量 - 例如:vars.get("VAR1"); vars.put("VAR2","value"); vars.remove("VAR3"); vars.putObject("OBJ1",new Object());
-
props- JMeter属性(java.util.Properties类) - 例如:props.get("START.HMS"); props.put("PROP1","1234");
-
OUT- System.out - 例如OUT.println("message")
SampleResult和ResponseData根据脚本的返回值来设置。如果脚本返回null,则可以使用SampleResult.setResponseData(data)方法直接设置响应 ,其中data是String或byte数组。data类型默认为“text”,但可以通过SampleResult.setDataType(SampleResult.BINARY)方法设置为二进制值 。
SampleResult变量给予脚本对SampleResult内所有字段和方法完全的访问权限。例如,脚本可以访问setStopThread(boolean)和setStopTest(boolean)方法。
与BeanShell取样器不同,JSR223取样器不通过脚本变量设置ResponseCode,ResponseMessage和样本status。目前改变这些的唯一方法是通过SampleResult方法:
SampleResult.setSuccessful(true/false)SampleResult.setResponseCode("code")SampleResult.setResponseMessage("message")
TCP取样器
TCP取样器打开与指定服务器的TCP/IP连接。然后发送文本,并等待响应。
如果选中“Re-use connection”,则在同一线程中的取样器之间共享连接,前提是使用完全相同的主机名称和端口。不同的主机/端口组合将使用不同的连接,不同的线程也是如此。如果同时选中“ Re-use connection ”和“Close connection”,则运行取样器后将关闭套接字。在下一个取样器上,将创建另一个套接字。您可能希望在每个线程循环结束时关闭套接字。
如果检测到错误 - 或未选中“Re-use connection” - 则关闭套接字。下一个样本将打开另一个套接字。
以下属性可用于控制其操作:
-
tcp.status.prefix状态码之前的文本
-
tcp.status.suffix状态码之后的文本
-
tcp.status.properties用于将状态代码转换为消息的属性文件的名称
-
tcp.handlerTCP Handler类的名称(默认
TCPClientImpl) - 仅在GUI上未指定时使用
处理连接的类由GUI定义,如果未定义,取tcp.handler属性的值。如果还是取不到,则在
org.apache.jmeter.protocol.tcp.sampler包中搜索该类。
用户可以提供自己的实现。该类必须扩展org.apache.jmeter.protocol.tcp.sampler.TCPClient。
目前提供以下实现。
TCPClientImplBinaryTCPClientImplLengthPrefixedBinaryTCPClientImpl
实现的行为如下:
-
TCPClientImpl这种实现是相当基础的。读取响应时,如果配置了
tcp.eolByte属性,则读取直到行字节结束,否则直到输入流结束。您可以通过设置tcp.charset来控制字符集编码,默认为平台默认编码。 -
BinaryTCPClientImpl此实现将GUI输入(必须是十六进制编码的字符串)转换为二进制,并在读取响应时执行相反的操作。读取响应时,如果配置了
tcp.BinaryTCPClient.eomByte属性,则读取直到消息字节结束,否则直到输入流结束。 -
LengthPrefixedBinaryTCPClientImpl此实现通过在二进制消息数据前加二进制长度字节来扩展BinaryTCPClientImpl。长度前缀默认为2个字节。可以通过设置属性
tcp.binarylength.prefix.length来变更。 -
超时处理
如果设置了超时,则读取将在超时后终止。因此,如果您使用的是
eolByte/eomByte,请确保超时设置的足够长,否则将过早终止读取。 -
响应处理
如果定义了
tcp.status.prefix,则会在响应消息中从此开始搜索文本,直到后缀结束。如果找到任何此类文本,则用于设置响应代码。然后从属性文件(如果提供)中获取响应消息。使用前缀(prefix)和后缀(suffix)
例如,如果prefix = “[“和suffix =“]”,则下面的响应:[J28] XI123,23,GBP,CR
将获取到响应代码为
J28。“
400”-“499”和“500”-“599” 范围内的响应代码目前被视为失败; 其他的视为成功。【这需要进行配置!】
提供的TCP实现不使用登录名/密码。
在测试运行结束时断开套接字。
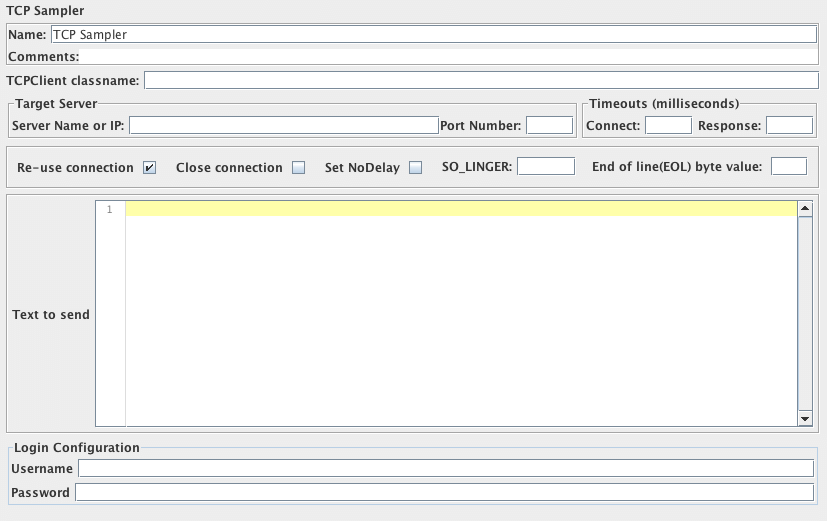
TCP取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器元件的描述性名称。 | 否 |
| TCPClient classname | TCPClient类的名称。默认取属性tcp.handler,若取不到则取TCPClientImpl。 |
否 |
| 服务器名称或IP | TCP服务器的名称或IP | 是 |
| 端口号 | 使用的端口 | 是 |
| Re-use connection | 如果选中,则连接保持打开状态。否则,数据读取完将关闭。 | 是 |
| 关闭连接 | 如果选中,取样器执行完毕将关闭连接。 | 是 |
| SO_LINGER | 创建套接字时通过启用/禁用SO_LINGER指定延迟时间(以秒为单位)。如果将“SO_LINGER”值设置为0,可以防止大量套接字处于TIME_WAIT状态。 |
否 |
| 行尾(EOL)字节值 | 行尾的字节值,将其设置为-128到+127范围之外的值以跳过eol检查。您可以在jmeter.properties文件中设置eolByte属性也可以在此处设置。如果在TCP取样器配置和jmeter.properties文件中同时设置此项,将使用TCP取样器配置中设置的值。 |
否 |
| 连接超时 | 连接超时时间(毫秒,0为禁用)。 |
否 |
| 响应超时 | 响应超时时间(毫秒,0为禁用)。 |
否 |
| 设置无延迟 | 请参阅java.net.Socket.setTcpNoDelay()。如果选中,则将禁用Nagle算法,否则将使用Nagle算法。 |
是 |
| 要发送的文本 | 要发送的文本 | 是 |
| 登录用户 | 用户名 - 默认实现不使用 | 否 |
| 密码 | 密码 - 默认实现不使用(注意,它在测试计划中是没有加密存储的) | 否 |
JMS发布
JMS发布将消息发布到给定目标(主题/队列)。对于那些不熟悉JMS的人来说,它是用于消息传递的J2EE规范。市场上有许多JMS服务器,还有一些是开源的。
JMeter不包含任何JMS实现jar;必须从JMS提供方下载并放入lib目录
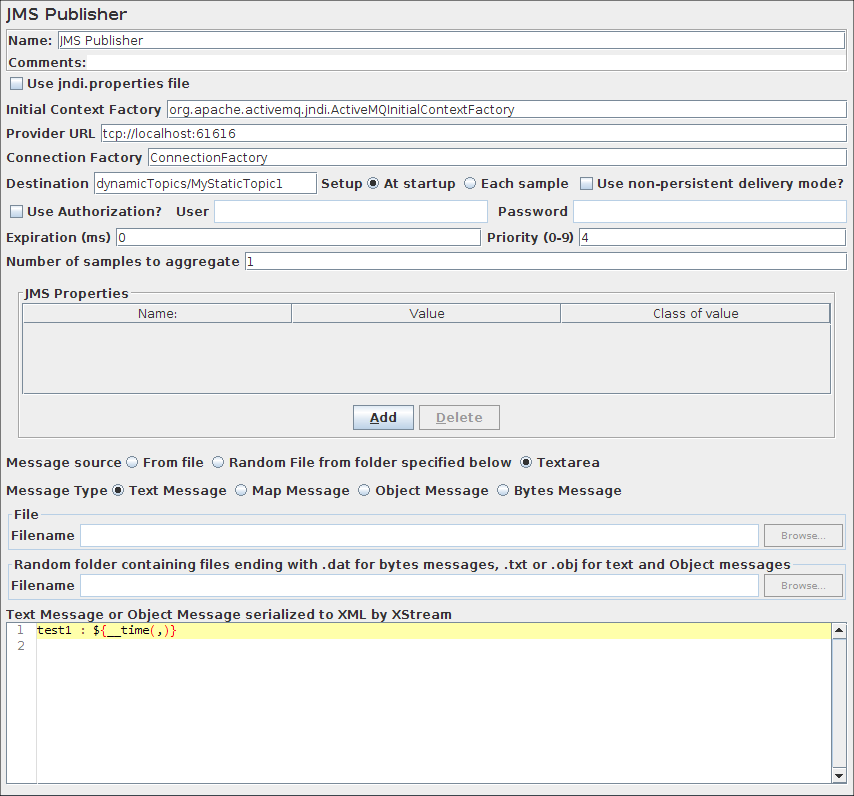
JMS发布控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| use JNDI properties file | 使用jndi.properties。注意该文件必须在classpath中 - 例如,通过更新JMeteruser.classpath属性。如果未选中此项,JMeter将使用“JNDI Initial Context Factory”和“Provider URL”字段来创建连接。 |
是 |
| JNDI Initial Context Factory | 上下文工厂的名称 | 否 |
| Provider URL | JMS提供方的URL | 是,除非使用jndi.properties |
| Destination | 消息目标(主题或队列名称) | 是 |
| Setup | 目标设置类型。设置为At startup时,目标名称是静态的(即在测试期间名称始终是一致的),设置为Each sample时,目标名称是动态的,并在每个样本被评估(即,目标名称是可变的) |
是 |
| Authentication | JMS提供方的身份验证要求 | 是 |
| User | 用户名 | 否 |
| Password | 密码(注意,它在测试计划中是没有加密存储的) | 否 |
| Expiration | 消息过期时间(以毫秒为单位)。如果未指定过期时间,则默认值为0(永不过期)。 |
否 |
| Priority | 消息的优先级。从0(最低)到9(最高)共10个优先级。如果未指定优先级,则默认级别为4。 |
否 |
| Reconnect on error codes (regex) | 强制重新连接的JMSException错误代码的正则表达式。如果为空则不会重新连接 | 否 |
| Number of samples to aggregate | 要聚合的样本数 | 是 |
| Message source | 获取消息来源:
|
是 |
| Message type | 文本,字典,对象消息或字节消息 | 是 |
| Content encoding | 指定用于读取消息源文件的编码:
|
是 |
| Use non-persistent delivery mode? | 是否设置DeliveryMode.NON_PERSISTENT(默认为false) |
否 |
| JMS Properties | JMS属性是特定于底层消息传递系统的属性。您可以设置值的名称,值和类(类型)。默认类型为String。例如:对于WebSphere 5.1 Web服务,您需要设置JMS Property targetService来通过JMS测试Web服务。 |
否 |
对于MapMessage类型,JMeter将源文件读取为文本行。每行必须有3个字段,用逗号分隔。这些字段是:
- 条目名称
- 对象类名,例如“
String”(如果未指定,则假定为java.lang包) - 对象字符串值
valueOf(String)
name,String,Example
size,Integer,1234
对象消息的实现和工作方式如下:
- 将包含对象及其依赖项的JAR放在
jmeter_home/lib/文件夹中- 使用XStream将对象序列化为XML
- 将结果放在以
.txt或.obj为后缀的文件中,或将XML内容直接放在文本区域中请注意,如果消息位于文件中,则在使用文本区域时将不会替换属性。
下表显示了在配置JMS时可能有用的一些值:
| Apache ActiveMQ | 值 | 备注 |
|---|---|---|
| 上下文工厂 | org.apache.activemq.jndi.ActiveMQInitialContextFactory | . |
| 提供者URL | vm://localhost | |
| 提供者URL | vm:(broker:(vm://localhost)?persistent=false) | 禁用持久性 |
| 队列参考 | dynamicQueues/QUEUENAME | 动态定义QUEUENAME到JNDI |
| 主题参考 | dynamicTopics/TOPICNAME | 动态定义TOPICNAME到JNDI |
JMS订阅
JMS订阅将订阅给定目标(主题或队列)中的消息。对于那些不熟悉JMS的人来说,它是用于消息传递的J2EE规范。市场上有许多JMS服务器,还有一些是开源的。
JMeter不包含任何JMS实现jar;必须从JMS提供方下载并放入lib目录
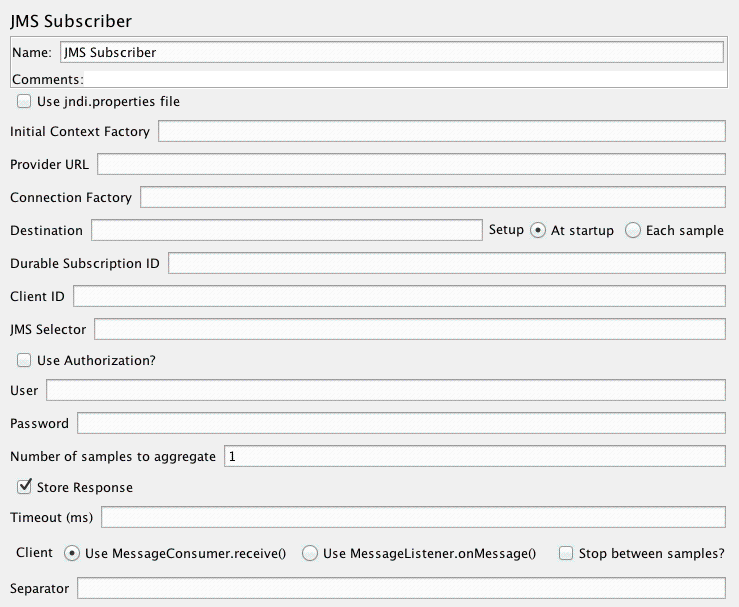
JMS订阅控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| use JNDI properties file | 使用jndi.properties。注意该文件必须在classpath中 - 例如,通过更新JMeteruser.classpath属性。如果未选中此项,JMeter将使用“JNDI Initial Context Factory”和“Provider URL”字段来创建连接。 |
是 |
| JNDI Initial Context Factory | 上下文工厂的名称 | 否 |
| Provider URL | JMS提供方的URL | 否 |
| Destination | 消息目标(主题或队列名称) | 是 |
| Durable Subscription ID | 用于持久订阅的ID。首次使用时,相应的队列若不存在,则会由JMS提供方自动生成。 | 否 |
| Client ID | 持久订阅时使用的客户端ID。当你有多个线程时,一定要添加一个像${__threadNum}这样的变量。 |
否 |
| JMS Selector | 由JMS规范定义的消息选择器,仅提取与选择器条件相关的消息。语法使用SQL 92的子部分。 | 否 |
| Setup | 目标设置类型。设置为At startup时,目标名称是静态的(即在测试期间名称始终是一致的),设置为Each sample时,目标名称是动态的,并在每个样本被评估(即,目标名称是可变的) |
是 |
| Authentication | JMS提供方的身份验证要求 | 是 |
| User | 用户名 | 否 |
| Password | 密码(注意,它在测试计划中是没有加密存储的) | 否 |
| Number of samples to aggregate | 要聚合的样本数 | 是 |
| Save response | 取样器是否存储响应。如果否,则仅返回响应长度。 | 是 |
| Timeout | 指定的超时时间,以毫秒为单位。0=none。这是整体聚合超时,而不是每个样本的超时。 |
是 |
| Client | 使用哪个客户端实现。它们都创建了可以读取消息的连接。但是,他们使用不同的策略,如下所述:
|
是 |
| Stop between samples? | 如果选中,则JMeter在每个样本的末尾调用Connection.stop()(并在每个样本之前调用start())。在多个样本/线程与同一队列连接的某些情况下,这可能很有用。如果未选中,JMeter将在线程的开始调用Connection.start(),并且在线程结束之后调用stop()。 |
是 |
| Separator | 分隔符用于在有多个消息时分隔消息(与设置要聚合的样本数相关)。注意\n,\r,\t都可以。 |
否 |
| Reconnect on error codes (regex) | 强制重新连接的JMSException错误代码的正则表达式。如果为空则不会重新连接 | 否 |
| Pause between errors (ms) | 发生错误时,订阅服务器的暂停时间,以毫秒为单位 | 否 |
JMS点到点
此取样器通过点到点连接(队列)发送并可选地接收JMS消息。与发布/订阅消息不同,它通常用于处理事务。
request_only通常用于对JMS系统产生负载。
request_reply这个模式将等待此服务发送的回复队列的响应,所以可以用于测试处理发送到请求队列消息的JMS服务的响应时间。
browse返回当前队列深度,即队列中的消息数。
read从队列中读取消息(如果有的话)。
clear清除队列,即从队列中删除所有消息。
JMeter在创建队列连接时使用java.naming.security.[principal|credentials]属性 - 如果存在。如果不需要此行为,请设置JMeter属性JMSSampler.useSecurity.properties=false
JMeter不包含任何JMS实现jar;必须从JMS提供方下载并放入lib目录
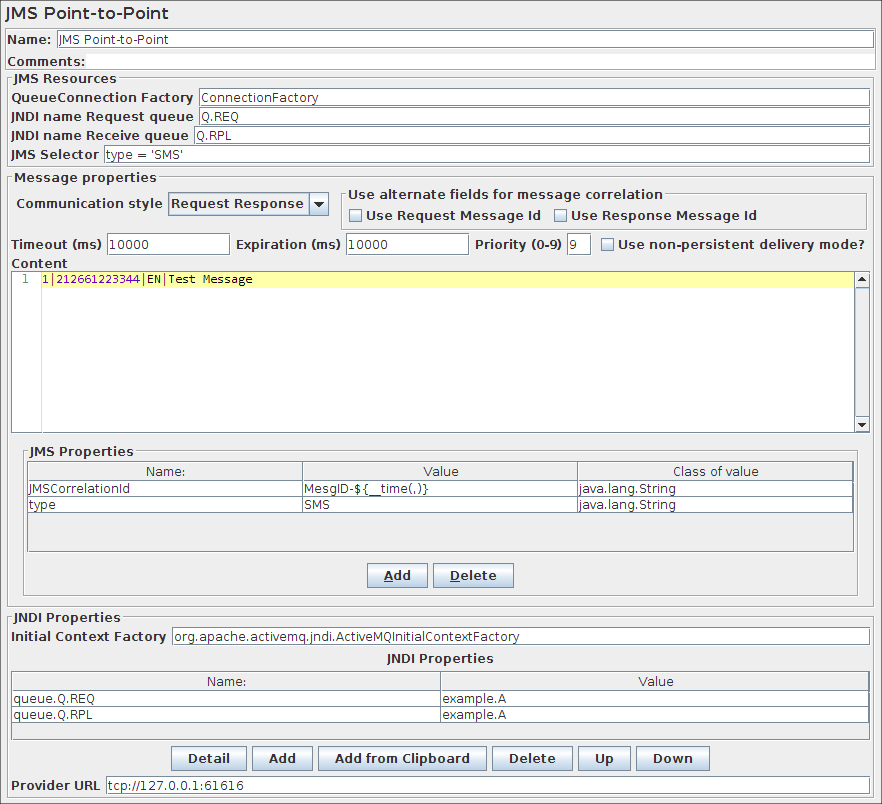
JMS点到点控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| QueueConnection Factory | 用于连接到消息传递系统的队列连接工厂的JNDI名称。 | 是 |
| JNDI Name Request queue | 这是发送消息的队列的JNDI名称。 | 是 |
| JNDI Name Reply queue | 接收队列的JNDI名称。如果此处提供了值并且通信模式为“Request Response”, 则将监视此队列以获得发送请求的响应。 |
否 |
| Number of samples to aggregate | 要聚合的样本数。仅适用于read通讯模式。 | 是 |
| JMS Selector | 由JMS规范定义的消息选择器,仅提取与选择器条件相关的消息。语法使用SQL 92的子部分。 | 否 |
| Communication style | 通信模式可以是Request Only(也称为Fire and Forget),Request Response,Read,Browse,Clear:
|
是 |
| Use alternate fields for message correlation | 这些复选框选择用于将响应消息与原始请求进行匹配的字段。
如果使用相同的队列发送和接收消息,则响应消息将与请求消息相同。在这种情况下,要么提供相关ID并清除两个复选框; 或选中两个复选框以使用消息Id进行关联。这对于检查原始JMS吞吐量非常有用。 |
是 |
| Timeout | 回复消息的超时时间(以毫秒为单位)。如果在指定时间内未收到回复,则特定测试用例将失败,并且将丢弃超时后收到的特定回复消息。默认为2000毫秒。0表示不设超时。 |
是 |
| Expiration | 消息过期时间(以毫秒为单位)。如果未指定,则默认值为0(永不过期)。 |
否 |
| Priority | 消息的优先级。从0(最低)到9(最高)有10个优先级。如果未指定优先级,则默认级别为4。 |
否 |
| Use non-persistent delivery mode? | 是否设置DeliveryMode.NON_PERSISTENT。 |
是 |
| Content | 消息的内容。 | 否 |
| JMS Properties | JMS属性是特定于底层消息传递系统的属性。您可以设置值的名称,值和类(类型)。默认类型为String。例如:对于WebSphere 5.1 Web服务,您需要设置JMS Property targetService来通过JMS测试Web服务。 |
否 |
| Initial Context Factory | Initial Context Factory是用于查找JMS资源的工厂。 | 否 |
| JNDI properties | JNDI属性是底层JNDI实现的特定属性。 | 否 |
| Provider URL | JMS提供方的URL。 | 否 |
JUnit请求
当前实现支持标准JUnit约定和扩展。它还包括oneTimeSetUp和oneTimeTearDown等扩展。取样器的工作方式与Java请求类似,但 存在一些差异。
- 与使用JMeter的测试接口不同,它会扫描jar文件以寻找扩展JUnit
TestCase类的类。这包括任何类或子类。 - JUnit测试jar文件应该放在
jmeter/lib/junit而不是/lib目录中。您还可以使用“user.classpath”属性指定查找TestCase类的位置。 - JUnit取样器不像Java请求那样使用名称/值对进行配置。取样器假定
setUp和tearDown将正确配置测试。 - 取样器仅测量测试方法的经过时间,不包括
setUp和tearDown。 - 每次调用测试方法时,JMeter都会将结果传递给监听器。
- 支持
oneTimeSetUp和oneTimeTearDown作为方法完成。由于JMeter是多线程的,我们不能像Maven那样调用oneTimeSetUp/oneTimeTearDown。 - 取样器将意外异常报告为错误。标准JUnit测试运行与JMeter实现之间存在一些重要差异。JMeter不是为每个测试创建一个新的类实例,而是为每个取样器创建一个实例并重用它。这可以通过复选框“
Create a new instance per sample”进行更改。
取样器的当前实现将尝试首先使用字符串构造函数创建实例。如果测试类没有声明字符串构造函数,则取样器将查找空构造函数。示例如下:
JUnit构造函数
空构造函数:public class myTestCase { public myTestCase() {} }字符串构造函数:
public class myTestCase { public myTestCase(String text) { super(text); } }
默认情况下,JMeter将为成功/失败代码和消息提供一些默认值。用户应定义一组唯一的成功和失败代码,并在所有测试中统一使用它们。
一般准则
如果使用
setUp和tearDown,请确保将方法声明为public。如果不这样做,测试可能无法正常运行。
以下是编写JUnit测试的一般准则,能使它们在JMeter下运行良好。由于JMeter运行多线程,因此记住某些事情非常重要。
- 编写的
setUp和tearDown方法应是线程安全的。这通常意味着避免使用静态成员。- 使测试方法成为离散的工作单元,而不是长的动作序列。通过将测试方法保持为离散操作,可以更轻松地组合测试方法以创建新的测试计划。
- 避免使测试方法相互依赖。由于JMeter允许对测试方法进行任意排序,因此运行行为与默认的JUnit行为不同。
- 如果测试方法是可配置的,请注意存储属性的位置。建议从Jar文件中读取属性。
- 每个取样器都会创建一个测试类的实例,因此编写测试时,应在
oneTimeSetUp和oneTimeTearDown中进行初始化等配置。
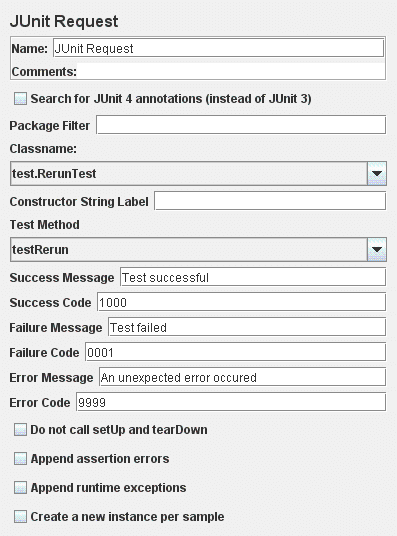
JUnit请求控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Search for JUnit4 annotations | 选择此项以搜索JUnit4测试(@Test注释) |
是 |
| Package filter | 以逗号分隔的要显示的包列表。例如,org.apache.jmeter,junit.framework。 |
否 |
| Class name | JUnit测试类的完全限定名称。 | 是 |
| Constructor string | 传递给字符串构造函数的字符串。如果设置了字符串,则取样器将使用字符串构造函数而不是空构造函数。 | 否 |
| Test method | 测试方法。 | 是 |
| Success message | 测试成功的描述性信息。 | 否 |
| Success code | 表示测试成功的唯一代码。 | 否 |
| Failure message | 测试失败的描述性信息。 | 否 |
| Failure code | 表示测试失败的唯一代码。 | 否 |
| Error message | 错误描述。 | 否 |
| Error code | 一些错误代码。不需要唯一。 | 否 |
| Do not call setUp and tearDown | 设置取样器不要调用setUp和tearDown。默认情况下,会调用setUp和tearDown。不调用这些方法可能会影响测试并使其不准确。此选项应仅与调用oneTimeSetUp和oneTimeTearDown一起使用。如果所选方法是oneTimeSetUp或oneTimeTearDown,则应检查此选项。 |
是 |
| Append assertion errors | 是否在响应消息中附加断言错误。 | 是 |
| Append runtime exceptions | 是否将运行时异常附加到响应消息。仅在未选择“Append assertion errors”时适用。 |
是 |
| Create a new Instance per sample | 是否为每个样本创建新的JUnit实例。默认为false,表示创建一个JUnitTestCase并重复使用。 |
是 |
识别以下JUnit4注释:
@Test
用于查找测试方法和类。支持“expected”和“timeout”属性。
@Before
在JUnit3中当做setUp()对待
@After
在JUnit3中当做tearDown()对待
@BeforeClass,@AfterClass
作为测试方法处理,因此可以根据需要独立运行
注意,当前版本JMeter直接运行测试方法,而不是将其留给JUnit。这是为了可以从采样时间中排除
setUp/tearDown方法。因此,取样器时间排除了调用setUp/tearDown方法及基于其注释的替代方法所花费的时间。
邮件阅读者取样器
邮件阅读者取样器可以使用POP3(S)或IMAP(S)协议读取(可选删除)邮件消息。
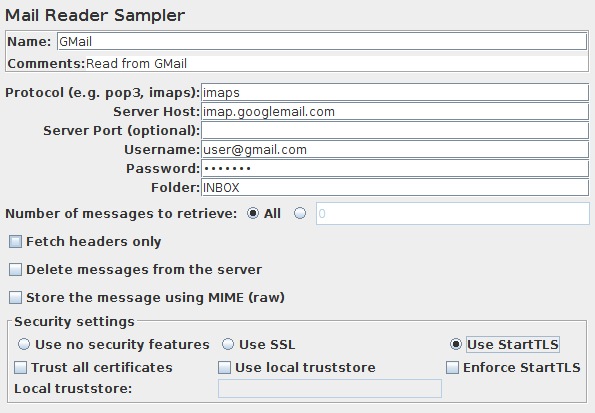
邮件阅读者取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Server Type | 提供者使用的协议:例如pop3,pop3s,imap,imaps。或其他表示服务器协议的字符串。例如file用于只读邮件文件提供者。POP3和IMAP的实际提供者名称是pop3和imap |
是 |
| Server | 服务器的主机名或IP地址。请参阅下面的file协议。 |
是 |
| Port | 用于连接服务器的端口号(可选) | 否 |
| Username | 用户登录名 | 否 |
| Password | 用户登录密码(注意,它在测试计划中是没有加密存储的) | 否 |
| Folder | 要使用的IMAP(S)文件夹。请参阅下面的file协议。 |
是,如果使用IMAP(S) |
| Number of messages to retrieve | 设置此项以检索所有或部分消息 | 是 |
| Fetch headers only | 如果选中,则仅检索邮件信息头。 | 是 |
| Delete messages from the server | 如果设置,将在检索后删除邮件 | 是 |
| Store the message using MIME | 是否将邮件存储为MIME。如果选中,则整个原始消息存储在响应数据中;信息头不会存储,因为它们在数据中可用。如果未选中,则将邮件信息头存储为响应信息头。部分信息头(Date,To,From,Subject)存储在消息体中。 |
是 |
| Use no security features | 表示与服务器的连接不使用任何安全协议。 | 否 |
| Use SSL | 表示与服务器的连接必须使用SSL协议。 | 否 |
| Use StartTLS | 表示与服务器的连接应尝试启动TLS协议。 | 否 |
| Enforce StartTLS | 如果服务器未启动TLS协议,则终止连接。 | 否 |
| Trust All Certificates | 选择后,它将接受独立于CA的所有证书。 | 否 |
| Use local truststore | 选择后,它只接受本地信任的证书。 | 否 |
| Local truststore | 包含受信任证书的文件路径。是针对当前目录的相对路径。 如果查找证书失败,则到包含测试脚本(JMX文件)的目录中寻找。 |
否 |
您可以通过向user.properties添加此处描述的任何属性来传递与邮件相关的环境属性。
消息存储为主取样器的子样本。多部分消息按部分存储为消息的子样本。
关于file协议的特殊处理:
JavaMail中file提供者可用于从文件中读取原始邮件。server字段用于指定路径的父folder。应使用名称n.msg存储单个消息文件,其中n为消息编号。或者,server字段可以是包含单个消息的文件的名称。此实现非常基础,主要用于调试目的。
测试活动(Flow Control Action)
测试活动取样器是一个适用于条件控制器的取样器。测试元件不是生成样本,而是暂停或停止所选目标。
此取样器也可以与事务控制器结合使用,因为它允许包含暂停而无需生成样本。对于可变延迟,将暂停时间设置为零,并将定时器添加为子级。
完成正在进行的任何样本后 ,“stop”操作将停止线程或测试。“Stop Now”操作将停止测试,而无需等待样本完成; 它会中断任何活动样本。如果某些线程未能在5秒的时间限制内停止,则将在GUI模式下显示一条消息。您可以使用Stop命令尝试停止线程,如果不能停止,可以手动退出JMeter。在CLI模式下,如果某些线程未能在5秒的时间限制内停止,JMeter将退出。
可以使用JMeter属性
jmeterengine.threadstop.wait更改等待时间。以毫秒为单位。
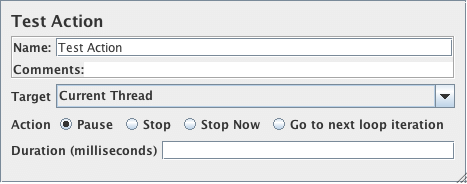
测试活动控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Target | Current Thread/All Threads( Pause 和 Go to next loop iteration时忽略) |
是 |
| Action | Pause/Stop/Stop Now/Go to next loop iteration |
是 |
| Duration | 暂停多长时间(毫秒) | 是,如果选中暂停 |
SMTP取样器
SMTP取样器可以使用SMTP/SMTPS协议发送邮件。可以为连接(SSL和TLS)以及用户身份认证设置安全协议。如果使用安全协议,则将对服务器证书进行验证。
有两种方法可以处理此验证:
Trust all certificates
这将忽略证书链验证
Use a local truststore
使用此选项,将根据本地信任库文件验证证书链。
SMTP取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Server | 服务器的主机名或IP地址。请参阅下面的file协议。 |
是 |
| Port | 用于连接服务器的端口号。默认值为:SMTP=25,SSL=465,StartTLS=587 | 否 |
| Connection timeout | 连接超时时间,以毫秒为单位(套接字级别)。默认不设超时。 | 否 |
| Read timeout | 读取超时时间(以毫秒为单位)(套接字级别)。默认不设超时。 | 否 |
| Address From | 将出现在电子邮件中的发件人地址 | 是 |
| Address To | 目标电子邮件地址(多个值以“;” 分隔) |
是,除非指定了CC或BCC |
| Address To CC | 抄送目标电子邮件地址(多个值以“;” 分隔) |
否 |
| Address To BCC | 密送目标电子邮件地址(多个值以“;” 分隔) |
否 |
| Address Reply-To | 备用回复地址(多个值以“;” 分隔) |
否 |
| Use Auth | 指示SMTP服务器是否需要户身份验证 | 否 |
| Username | 用户登录名 | 否 |
| Password | 用户登录密码(注意,它在测试计划中是没有加密存储的) | 否 |
| Use no security features | 表示与SMTP服务器的连接不使用任何安全协议。 | 否 |
| Use SSL | 表示与SMTP服务器的连接必须使用SSL协议。 | 否 |
| Use StartTLS | 表示与SMTP服务器的连接应尝试启动TLS协议。 | 否 |
| Enforce StartTLS | 如果服务器未启动TLS协议,则终止连接。 | 否 |
| Trust All Certificates | 选择后,它将接受独立于CA的所有证书。 | 否 |
| Use local truststore | 选择后,它只接受本地信任的证书。 | 否 |
| Local truststore | 包含受信任证书的文件路径。是针对当前目录的相对路径。 如果查找证书失败,则到包含测试脚本(JMX文件)的目录中寻找。 |
否 |
| Override System SSL/TLS Protocols | 在握手时使用的自定义SSL/TLS协议,它是以空格分隔的列表,例如TLSv1 TLSv1.1 TLSv1.2。默认为所有支持的协议。 |
否 |
| Subject | 电子邮件主题。 | 否 |
| Suppress Subject Header | 如果选中,则从发送的邮件中省略“Subject:”邮件头。这与发送空的“ Subject:”邮件头不同,尽管某些电子邮件客户端可能会以相同的方式显示它。 |
否 |
| Include timestamp in subject | 包含主题行中的System.currentTimemillis()。 |
否 |
| Add Header | 可以使用此按钮定义其他邮件头。 | 否 |
| Message | 消息体。 | 否 |
| Send plain body (i.e. not multipart/mixed) | 如果选中,则将主体作为简单消息发送,即不是multipart/mixed,如果可能的话。如果消息正文为空并且只有一个文件,则将文件内容作为消息体发送。注意:如果邮件正文不为空,并且至少有一个附加文件,则消息体将使用 |
否 |
| Attach files | 要附加到邮件的文件 | 否 |
| Send .eml | 如果设置,将发送.eml文件而不是Subject,Message和Attach file(s)字段中的条目 |
否 |
| Calculate message size | 计算消息大小并将其存储在样本结果中。 | 否 |
| Enable debug logging? | 如果设置,则“mail.debug”属性设置为“true” |
否 |
OS进程取样器
OS进程取样器是一个可用于在本地计算机上执行命令的取样器。
它应该允许执行可以从命令行运行的任何命令。
可以启用返回代码的验证,并可以指定预期的返回代码。
注意OS shell通常提供命令行解析。这在操作系统之间有所不同,但通常shell会按照空格拆分参数。一些shell扩展了通配符文件名;另一些没有。操作系统之间的引用机制也各不相同。取样器故意不进行任何解析或引用处理。必须以可执行文件期望的形式提供命令及其参数。这意味着取样器设置将无法在操作系统之间移植。
许多操作系统都有一些内置命令,这些命令不作为单独的可执行文件提供。例如,WindowsDIR命令是命令解释器(CMD.EXE)的一部分。这些内置函数不能作为独立程序运行,但必须作为参数提供给相应的命令解释器。
例如,Windows命令行:DIR C:\TEMP需要指定如下:
- 命令:
CMD
- 参数1:
/C
- 参数2:
DIR
- 参数3:
C:\TEMP
OS进程取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 命令 | 要执行的程序名称。 | 是 |
| 工作目录 | 执行命令的目录,默认为系统属性“user.dir”引用的文件夹 |
否 |
| 命令行参数 | 传递给程序名称的参数。 | 否 |
| 环境变量 | 执行命令时添加到环境的键/值对。 | 否 |
| Standard input (stdin) | 要从中获取输入的文件的名称(STDIN)。 |
否 |
| Standard output (stdout) | 标准输出(STDOUT)的输出文件名。如果省略,则捕获输出并作为响应数据返回。 |
否 |
| Standard error (stderr) | 标准错误(STDERR)的输出文件名。如果省略,则捕获输出并作为响应数据返回。 |
否 |
| 检查返回码 | 如果选中,则取样器会将返回码与预期返回代码进行比较。 |
否 |
| 预期返回代码 | 系统调用的预期返回代码,需要选中“检查返回码 ”。注意500在JMeter中用作错误指示符,因此您不应使用它。 |
否 |
| Timeout | 命令超时时间(以毫秒为单位),默认为0,表示不设超时。如果命令执行完之前超时了,JMeter将尝试终止OS进程。 |
否 |
MongoDB脚本(已弃用)
略
18.2 逻辑控制器
逻辑控制器决定取样器的处理顺序。
简单控制器
简单逻辑控制器允许您组织取样器和其他逻辑控制器。与其他逻辑控制器不同,该控制器不提供超出存储设备的功能。
简单控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
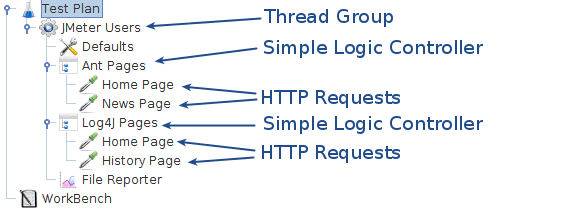
使用简单控制器
下载此示例(参见图6)。在此示例中,我们创建了一个测试计划,该计划发送两个Ant HTTP请求和两个Log4J HTTP请求。我们通过把Ant和Log4J请求放在简单逻辑控制器中将它们分组。请记住,简单逻辑控制器对JMeter如何处理您添加到其中的控制器没有影响。因此,在此示例中,JMeter按以下顺序发送请求:Ant Home Page,Ant News Page,Log4J Home Page, Log4J History Page。注意,File Reporter配置为将结果存储在当前目录中名为“
simple-test.dat”的文件中。
图6 - 简单控制器示例
循环控制器
如果将生成器或逻辑控制器添加到循环控制器,除了为线程组指定的循环次数外,JMeter还将循环它们一定次数。例如,如果将一个HTTP请求添加到循环计数为2的循环控制器,并将线程组循环计数配置为3,则JMeter将发送总共2 * 3 = 6个 HTTP请求。
JMeter将循环索引公开为名为
__jm__<Name of your element>__idx的变量。因此,例如,假设您的循环控制器名称为LC,那么您可以通过${__jm__LC__idx}访问循环索引。索引从0开始
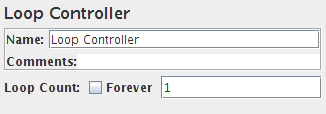
循环控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 循环次数 | 每次测试执行时,将重复此控制器的子元件的次数。 值 -1等同于选中永远。特殊情况:嵌入在线程组元件中的循环控制器的行为略有不同。除非设置为永久,否则在完成给定的迭代次数后,它将停止测试。 在此字段中使用函数时,请注意可能会多次评估它。例如在循环控制器中使用 |
是,除非选中“永远” |
循环示例
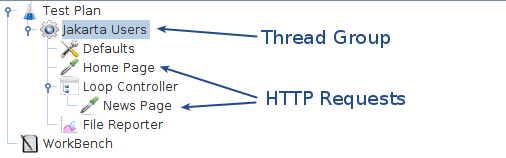
下载此示例(参见图4)。在此示例中,我们创建了一个测试计划,该计划发送一个HTTP请求1次,并发送另一个HTTP请求5次。
图4 - 循环控制器示例我们为单个线程配置了线程组,并将循环次数配置为1。我们使用循环控制器,而不是让线程组控制循环。您可以看到我们向线程组添加了一个HTTP请求,并向循环控制器添加了另一个HTTP请求。我们将循环控制器循环次数配置为5。
JMeter将按以下顺序发送请求:Home Page,News Page,News Page,News Page,News Page,和News Page。
注意,File Reporter配置为将结果存储在当前目录中名为“
loop-test.dat”的文件中。
仅一次控制器
仅一次逻辑控制器告诉JMeter每个线程只处理一次其内部的控制器,并在测试计划之后的迭代期间执行其后的所有请求。
仅一次控制器现在将始终在任何循环父控制器的第一次迭代期间执行。因此,如果将仅一次控制器放置在指定循环5次的循环控制器下,那么仅一次控制器将仅在循环控制器第一次迭代时执行(即每5次)。
注意这意味着如果将它置于一个线程组(每个线程每次测试只运行一次),那么仅一次控制器仍然会像预期的那样运行,但现在用户可以更灵活地使用仅一次控制器。
对于需要登录的测试,请考虑将登录请求放在此控制器中,因为每个线程只需登录一次即可建立会话。
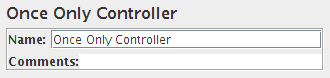
仅一次控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
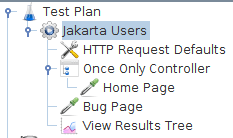
仅一次示例
下载此示例(参见图5)。在此示例中,我们创建了一个测试计划,其中包含两个发送HTTP请求的线程。每个线程向Home Page发送一次请求,然后向Bug Page发送三次请求。虽然我们将线程组配置为迭代三次,但每个JMeter线程只向Home Page发送一次请求,因为此请求位于仅一次控制器内。
图5 - 仅一次控制器示例每个JMeter线程将按以下顺序发送请求:Home Page,Bug Page,Bug Page,Bug Page。
注意,File Reporter配置为将结果存储在当前目录中名为“
loop-test.dat”的文件中。
交替控制器
如果将生成器或逻辑控制器添加到交替控制器,则JMeter每次循环迭代时将在每个其他控制器之间交替进行。
交替控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 忽略子控制器块 | 如果选中,交替控制器将把子控制器当作单个请求元件来处理,并且每个控制器一次只允许一个请求。 | 否 |
| Interleave across threads | 如果选中,交替控制器每次循环迭代时将跨所有线程在每个子控制器之间交替进行。例如在具有4个线程和3个子控制器的配置中,在第一次迭代时线程1将运行第一个子节点,线程2第二个子节点,线程3第三个子线程,线程4第一个子节点,在下一次迭代中,每个线程将运行下一个子控制器 | 否 |
简单交替示例
下载此示例(参见图1)。在此示例中,我们将线程组配置为具有两个线程且循环次数为5,每个线程总共10个请求。请参阅下表,了解JMeter发送HTTP请求的顺序。
图1 - 交替控制器示例1
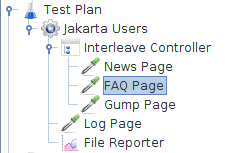
循环迭代 每个JMeter线程发送这些HTTP请求 1 News Page 1 Log Page 2 FAQ Page 2 Log Page 3 Gump Page 3 Log Page 4 因为控制器中没有更多请求,JMeter重新开始并发送第一个HTTP请求,即News Page 4 Log Page 5 FAQ Page 5 Log Page 有用的交替示例
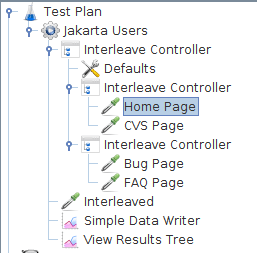
下载另一个示例(参见图2)。在此示例中,我们将线程组配置为具有1个线程且循环次数为8。请注意,测试计划有一个外部交替控制器,其下有两个交替控制器。
图2 - 交替控制器示例2外部交替控制器在两个内部控制器之间交替。然后,每个内部交替控制器在每个HTTP请求之间交替。每个JMeter线程将按以下顺序发送请求: Home Page,Interleaved,Bug Page,Interleaved,CVS Page,Interleaved,和FAQ Page,Interleaved。
注意,File Reporter配置为将结果存储在当前目录中名为“
interleave-test2.dat”的文件中。
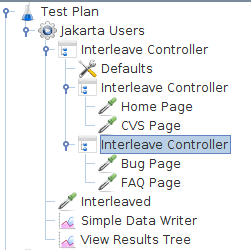
图3 - 交替控制器示例3如果主交替控制器下的两个交替控制器是简单控制器,那么顺序将是:Home Page,CVS Page,Interleaved,Bug Page,FAQ Page,Interleaved。
但是,如果在主交替控制器上选中了“
忽略子控制器块”,那么顺序将是:Home Page,Interleaved,Bug Page,Interleaved,CVS Page,Interleaved,和FAQ Page,Interleaved。
随机控制器
随机逻辑控制器的作用类似于交替控制器,不同之处在于它通过其子控制器和取样器时不是按排列顺序,而是在每次通过时随机选取一个。
多个控制器之间的交互可以产生复杂的行为。随机控制器尤其如此。请在假设任何给定的交互产生的结果之前进行实验

随机控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 忽略子控制器块 | 如果选中,交替控制器将把子控制器当作单个请求元件来处理,并且每个控制器一次只允许一个请求。 | 否 |
随机顺序控制器
随机顺序控制器很像简单控制器,因为它的每个子元件最多只执行一次,但节点的执行顺序是随机的。
随机顺序控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
吞吐量控制器
吞吐量控制器允许用户控制执行的频率。有两种模式:
- Percent executions
- Total executions
Percent executions
使控制器对测试计划执行一定比例的迭代。
Total executions
使控制器在执行了一定数量的执行后停止执行。
与仅一次控制器一样,当父循环控制器重新启动时,此设置将被重置。
该控制器的命名不太好,因为它不控制吞吐量。有关可用于调整吞吐量的元件,请参阅常数吞吐量定时器。
吞吐量控制器控制面板的截图
当与其他控制器结合使用时,吞吐量控制器会产生非常复杂的行为 - 特别是父项是交替或随机控制器的情况(也非常有用)。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 执行方式 | 控制器是以Percent executions模式还是以Total executions模式运行。 | 是 |
| 吞吐量 | 一个数字。对于Percent executions模式,0到100之间的数字表示控制器执行的次数百分比。“50”表示控制器将在测试计划的一半迭代期间执行。对于Total executions模式,该数字表示控制器将执行的总次数。 |
是 |
| Per User | 如果选中,控制器的计算是在每个用户(每个线程)的基础上执行。如果未选中,则所有用户的计算都将是全局的。例如,如果使用Total executions模式,并取消选中“per user”,则为吞吐量指定的数字将是执行的总执行次数。如果选中“per user”,那么执行的总数将是用户数量乘以吞吐量的数量。 |
否 |
Runtime控制器
Runtime控制器控制其子节点运行多长时间。控制器将运行其子项,直到超出配置的Runtime(s)。
Runtime控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称,同时用于命名事务。 | 是 |
| Runtime (seconds) | 期望的运行时间。0表示不运行。 | 是 |
如果(If)控制器
If控制器允许用户控制其下方的测试元件(其子元件)是否运行。
默认情况下,条件仅在初始条目时计算一次,但您可以选择对控制器中包含的每个可运行元件进行计算。
If控制器将在内部使用javascript来计算条件,但这会导致性能下降。
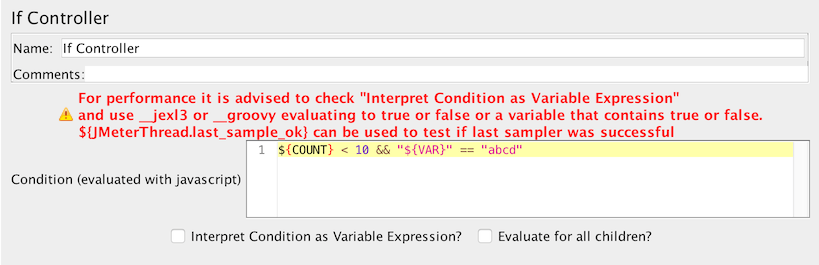
If控制器使用javascript
更好的选项(默认选项)是使用Interpret Condition as Variable Expression?,然后在条件字段中,您有2个选项:
-
选项1:使用包含
true或false的变量如果要测试最后一个样本是否成功,可以使用
${JMeterThread.last_sample_ok}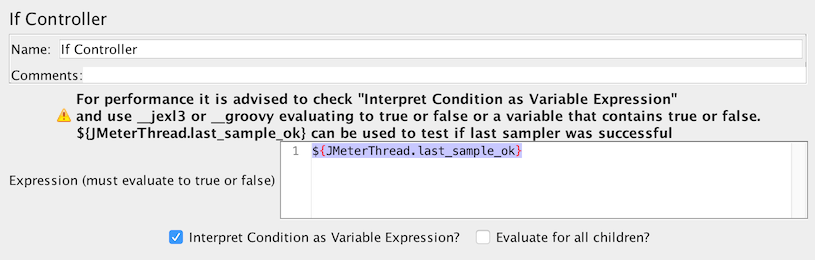
If控制器使用变量 -
选项2:使用函数(建议使用
${__jexl3()})来计算表达式,表达式必须返回true或false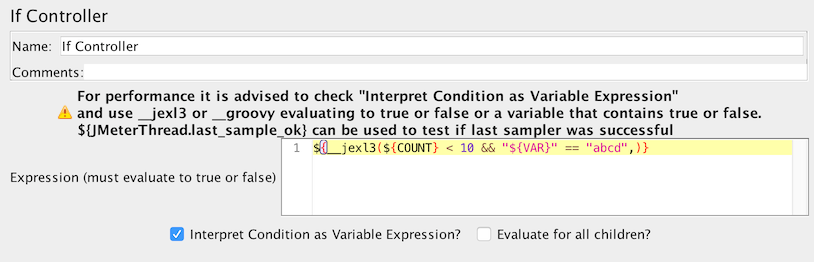
If控制器使用表达式
例如,以前可以使用条件:${__jexl3(${VAR} == 23)}并将其评估为true/false,然后将结果传递给JavaScript,然后返回true/false。如果选择了Variable Expression选项,则会计算表达式并与“true” 进行比较,而无需使用JavaScript。
要测试变量是否未定义(或为null),请执行以下操作,假设变量名为
myVar,表达式如下:"${myVar}" == "\${myVar}"或使用:
"${myVar}" != "\${myVar}"测试变量是否已定义且不为null。
IF控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| Condition (default JavaScript) | 默认情况下,条件按JavaScript代码解析并返回“true”或“false”,但这可以被覆盖(见下文) |
是 |
| Interpret Condition as Variable Expression? | 如果选中,则条件必须是计算结果为“true”的表达式(忽略大小写)。例如,${FOUND}或${__jexl3(${VAR} > 100)}。与JavaScript情况不同,仅检查条件是否匹配“true”(忽略大小写)。对于性能测试,建议在条件中使用__jexl3或__groovy函数 |
是 |
| Evaluate for all children | 是否应对所有子元件进行评估?如果未选中,则仅在输入时评估条件。 | 是 |
示例(JavaScript)
-${COUNT} < 10-"${VAR}" == "abcd"如果解析代码时出错,则假定条件判断为
false,并在jmeter.log中记录消息。注意,性能测试中建议避免使用JavaScript模式。
使用__groovy时请注意不要在字符串中使用变量替换,因为使用更改脚本的变量会无法缓存。应该使用
vars.get("myVar")获取变量。 请参阅下面的Groovy示例。示例(变量表达式)
-${__groovy(vars.get("myVar") != "Invalid" )}(Groovy检查myVar是否不等于Invalid) -${__groovy(vars.get("myInt").toInteger() <=4 )}(Groovy 检查myInt是否小于或等于4) -${__groovy(vars.get("myMissing") != null )}(Groovy 检查myMissing变量是否没有设置) -${__jexl3(${COUNT} < 10)}-${RESULT}-${JMeterThread.last_sample_ok}(检查最后一个样本是否成功)
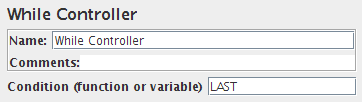
While控制器
While控制器运行其子项,直到条件为“false”时停止。
JMeter将循环索引公开为名为
__jm__<Name of your element>__idx的变量。因此,例如,如果您的While控制器名为WC,那么您可以通过${__jm__WC__idx}访问循环索引。索引从0开始
可能的条件值:
- 空白 - 当循环中的最后一个样本失败时退出循环
LAST- 当循环中的最后一个样本失败时退出循环。如果循环之前的最后一个样本失败,不进入循环。- 其他 - 当条件等于字符串“
false” 时退出(或不进入)循环
条件可以是最终计算为字符串“
false”的任何变量或函数。这允许根据需要使用__jexl3,__groovy函数,属性或变量。请注意,条件被评估两次,一次是在开始采样子项之前,一次是在子项采样结束时,因此将非幂等函数放入Condition(如__counter)可能会产生问题。
例如:
${VAR}- 其他测试元件将VAR设置为false${__jexl3(${C}==10)}${__jexl3("${VAR2}"=="abcd")}${_P(property)}- 其他某个地方将属性设置为"false"
While控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。同时用于命名事务。 | 否 |
| Condition | 空白,LAST,或变量/函数 |
否 |
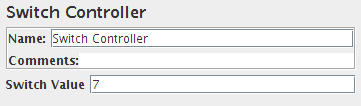
Switch控制器
Switch控制器的作用类似于交替控制器,它在每次迭代时运行一个子元件,但控制器运行顺序不是按排列顺序,而是按switch value定义。
switch value也可以是名称。
如果switch value超出范围,它将运行第0个元件,这是数字情况的默认值。如果value为空字符串,它也是运行第0个元件。
如果value为非数字(且非空),则Switch控制器将查找具有相同名称的元件(要考虑大小写)。如果没有匹配的名称,则选择名为“default”(要考虑大小写)的元件。如果没有默认值,则不选择任何元件,并且控制器不会进行任何操作。
Switch控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| Switch Value | 要调用的从属元件的值(或名称)。元件从0开始编号。默认值为0 | 否 |
ForEach控制器
ForEach控制器循环遍历一组相关变量的值。将取样器(或控制器)添加到ForEach控制器时,每个取样器(或控制器)执行一次或多次,在每个循环期间变量会有新值。输入应包含多个变量,每个变量都用下划线和数字扩展。每个这样的变量都必须有一个值。因此,例如当输入变量的名称为inputVar时,应该定义以下变量:
inputVar_1 = wendyinputVar_2 = charlesinputVar_3 = peterinputVar_4 = john
注意:“_”分隔符现在是可选的。
当返回变量以“returnVar” 给出时,ForEach控制器下的取样器和控制器的集合将连续执行4次,返回变量具有相应的上述值,并且可以在取样器中使用。
JMeter将循环索引公开为名为
__jm__<Name of your element>__idx的变量。因此,例如,如果您的循环控制器名为FEC,那么您可以通过${__jm__FEC__idx}访问循环索引。索引从0开始
它特别适合与正则表达式后置处理器一起运行。这可以从先前请求的结果数据中“创建”必要的输入变量。通过省略“_”分隔符,可以使用ForEach控制器通过输入变量refName_g循环遍历组,并且还可以使用形如refName_${C}_g的输入变量循环遍历所有匹配中的所有组,其中C是计数器变量。
如果
inputVar_1值为null,ForEach控制器不会执行任何取样。如果正则表达式没有返回匹配,则会出现这种情况。
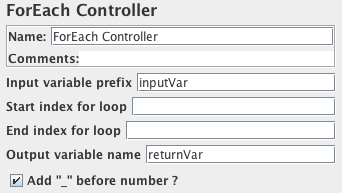
ForEach控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 输入变量前缀 | 要用作输入的变量名称的前缀。默认为空字符串作为前缀。 | 否 |
| 开始循环字段 | 变量循环开始字段(独占)(第一个元件在起始索引+1) | 否 |
| 结束循环字段 | 循环变量的结束字段(包含) | 否 |
| 输出变量名称 | 变量的名称,可以用于循环中的取样器中的替换。默认为空变量名,很可能不需要。 | 否 |
| 使用分隔符 | 如果未选中,则忽略“_”分隔符。 |
是 |
ForEach示例
下载此示例(参见图7)。在此示例中,我们创建了一个测试计划,该计划仅发送一次特定的HTTP请求,并将另一个HTTP请求发送到页面上可找到的每个链接。
图7 - ForEach控制器示例我们为单个线程配置了线程组,并将循环次数配置为1。您可以看到我们向线程组添加了一个HTTP请求,并向ForEach控制器添加了另一个HTTP请求。
在第一个HTTP请求之后,添加了一个正则表达式提取器,它从返回页面中提取所有html链接并将它们放在
inputVar变量中在ForEach循环中,添加了一个HTTP取样器,它请求从第一个返回的HTML页面中提取的所有链接。
ForEach示例
这是您可以下载的另一个示例。这有两个正则表达式和ForEach控制器。第一个正则有匹配,第二个没有匹配,因此第二个ForEach控制器不运行任何样本
图8 - ForEach控制器示例2线程组设置一个线程,循环次数为2。
Sample 1使用JavaTest取样器返回字符串“
a b c d”。正则表达式提取器使用表达式
(\w)\s匹配一个字母后跟一个空格,并返回字母(而不是空格)。所有匹配都以字符串“inputVar” 为前缀。ForEach控制器提取包含前缀“
inputVar_” 的所有变量,并执行其样本,传递变量“returnVar”中的值。在这种情况下,它将依次将变量设置为值“a” “b”和“c”。
For 1是另一个Java取样,使用返回变量“returnVar”作为样本标签的一部分,同时作为采样数据。
Sample 2,Regex 2和For 2几乎相同,只是正则表达式变成“(\w)\sx”,这显然无法获得任何匹配。因此For 2样本将不会运行。
模块控制器
模块控制器提供了一种在运行时将测试计划片段替换为当前测试计划的机制。
测试计划片段由控制器和其中包含的所有测试元件(取样器等)组成。片段可以位于任何线程组中。如果片段位于线程组中,则可以禁用其控制器以防止片段在模块控制器以外运行。或者,您可以将片段存储在虚拟线程组中,并禁用整个线程组。
可以有多个片段,每个片段下面都有不同系列的取样器。然后,只需在模块控制器的下拉框中选择适当的控制器即可在这些多个测试用例之间轻松切换。这为快速轻松地运行许多备用测试计划提供了便利。
片段名称由控制器名称及其所有父名称组成。例如:
Test Plan / Protocol: JDBC / Control / Interleave Controller (Module1)
模块控制器使用的任何片段都必须具有唯一的名称,因为该名称用于在重新加载测试计划时查找目标控制器。因此,最好确保控制器名称不是默认值 - 如上例所示 - 否则在新元件添加到测试计划时可能会意外创建副本。
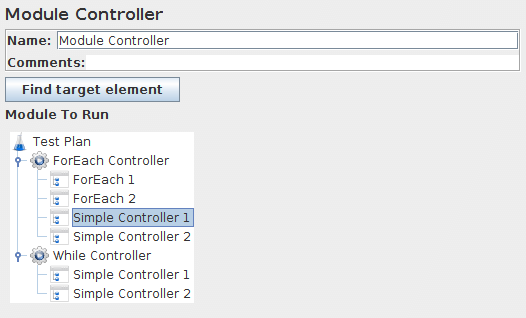
模块控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| Module to Run | 模块控制器提供加载到gui中的所有控制器的列表。在运行时选择要替换的那个。 | 是 |
Include控制器
Include控制器旨在使用外部JMX文件。要使用它,在测试计划下创建一个测试片段,并在其下面添加任何所需的取样器,控制器等。然后保存测试计划。该文件现在可以作为其他测试计划的一部分包含在内。
为方便起见,还可以在外部JMX文件中添加线程组以进行调试。模块控制器可用于引用试验片段。该线程组在include进程中将被忽略。
如果测试使用Cookie管理器或用户定义的变量,则应将这些变量放在顶级测试计划中,而不是include的文件中,否则无法保证它们正常工作。
此元件不支持文件名字段中的变量/函数。
但是,如果定义了属性includecontroller.prefix,则内容将用于路径名称的前缀。使用Include控制器并包含相同的JMX文件时,请确保Include控制器命名不同以避免遇到已知问题Bug 50898。
如果在prefix+Filename给定的位置找不到该文件,则控制器会尝试打开相对于JMX启动目录下的Filename。
Include控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 文件名 | 要包含的文件。 | 是 |
事务控制器
事务控制器生成一个额外的样本,用于测量执行嵌套测试元件所花费的总时间。
注意:如果选中“
Include duration of timer and pre-post processors in generated sample”复选框,则时间包括控制器范围内的所有处理,而不仅仅是样本执行时间。
有两种操作模式:
- 嵌套样本后添加额外的样本
- 添加额外的样本作为嵌套样本的父级
生成的采样时间包括嵌套取样器的所有时间,默认情况下(从2.11开始)不包括定时器和前置/后置处理器执行时间,除非选中“Include duration of timer and pre-post processors in generated sample”复选框。根据时钟精度,它可能略长于各个取样器加定时器的总和。在控制器记录开始时间之后但在第一个样本开始之前,时钟开始滴答。在最后也一样。
仅当所有子样本都成功时,生成的样本才被视为成功。
在父模式下,仍可以在查看结果树监听器中看到各个样本,但不再在其他监听器中显示为单独的条目。此外,子样本不会出现在CSV日志文件中,但可以保存到XML文件中。
在父模式下,可以将断言(等)添加到事务控制器中。但是,默认情况下,它们将同时应用于单个样本和整个事务样本。要限制断言的范围,请使用简单控制器来包含样本,并将断言添加到简单控制器。父模式控制器当前不能正确支持任何类型的嵌套事务控制器。
事务控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称,用于命名事务。 | 是 |
| Generate Parent Sample | 如果选中,则生成样本作为其他样本的父项,否则样本将作为独立样本生成。 | 是 |
| Include duration of timer and pre-post processors in generated sample | 是否在生成的样本中包括定时器,前置和后置处理延迟。默认值为false |
是 |
录制控制器
记录控制器是指示代理服务器录制样本位置的占位符。在测试运行期间,它没有任何效果,类似于简单控制器。但在使用HTTP代理服务器录制时,所有录制的样本将默认保存在录制控制器下。

录制控制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
临界部分控制器
临界部分控制器确保其子元件(取样器/控制器等)将仅由一个线程执行,在执行控制器的子节点之前将执行命名锁定。
临界部分控制器控制面板的截图
下图显示了使用临界部分控制器的示例,如下图所示2个临界部分控制器用来确保:
-
DS2-${__threadNum}一次只能由一个线程执行 -
DS4-${__threadNum}一次只能由一个线程执行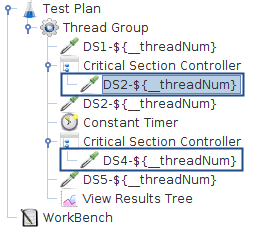
使用临界部分控制器的测试计划
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此控制器的描述性名称。 | 否 |
| 锁名称 | 锁定将由控制器执行,确保为不相关的部分使用不同的锁名称 | 是 |
临界部分控制器仅在一个JVM中获取锁,因此如果使用分布式测试,请确保您的用例不依赖于所有JVM阻塞的所有线程。
18.3 监听器
除了“监听”测试结果之外,大多数监听器扮演多种角色。它们还提供查看,保存和读取已保存测试结果的方法。
注意,监听器在找到它们的范围的最后处理。
测试结果的保存和读取是通用功能。各种监听器都有一个面板,用户可以指定要写入(或读取)结果的文件。默认情况下,结果存储为XML文件,通常带有“.jtl”扩展名。存储为CSV是最有效的选项,但不如XML(另一个可用选项)详细。
监听器不处理在CLI模式下的取样数据,但是,如果配置了输出文件,原始数据将被保存。为了分析CLI运行生成的数据,您需要将文件加载到相应的监听器中。
要读取现有结果并显示它们,请使用文件面板的浏览按钮打开该文件。
如果要在加载新文件之前清除所有当前数据,请在加载文件之前使用菜单项“运行”→“清除” (Ctrl+Shift+E) 或“运行”→“清除全部” (Ctrl+E) 。
可以从XML或CSV格式文件中读取结果。从CSV结果文件中读取时,标题(如果存在)用于确定存在哪些字段。为了正确解析无标题的CSV文件,必须在jmeter.properties中设置相应的属性。
JMeter编写的XML文件在头文件中声明版本1.0,而实际文件使用1.1规则序列化。(这样做是出于历史兼容性原因;请参阅Bug 59973和Bug 58679)这会导致严格的XML解析器失败。考虑使用非严格的XML解析器来读取JTL文件。
文件名可以包含函数和/或变量引用。但是,变量引用在客户端 - 服务器模式下不起作用(函数可以正常工作)。这是因为文件是在客户端上创建的,而客户端不在本地运行测试,因此不会设置变量。
如果有大量样本,监听器会使用大量内存。目前大多数监听器都在其范围内拷贝每个样本的副本,下列监听器除外:
- 简单数据写入器
- BeanShell/JSR223监听器
- 邮件观察器
- 汇总报告
以下监听器不再需要保存每个样本的副本。相反,聚合具有相同经过时间的样本。现在需要更少的内存,特别是如果大多数样本只需要一两秒钟。
- 聚合报告
- 汇总图
要最小化所需的内存量,请使用简单数据写入器,并使用CSV格式。
JMeter变量可以保存到输出文件中。这只能使用属性指定。有关详细信息, 请参阅监听器样本变量
有关设置要保存的默认项的完整详细信息,请参阅监听器默认配置文档。有关输出文件内容的详细信息,请参阅CSV日志格式或XML日志格式。
jmeter.properties中的条目用于定义默认值;可以使用“配置”按钮为单个监听器重写这些内容,如下所示。jmeter.properties中的设置也适用于使用命令行标志-l添加的监听器。
下图显示了结果文件配置面板的示例

结果文件配置面板
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 文件名 | 包含样本结果的文件的名称。可以使用相对路径名或绝对路径名指定文件名。相对路径相对于当前工作目录(默认为bin/目录)进行解析。JMeter还支持相对于包含当前测试计划(JMX文件)的目录的路径。如果路径名以“〜/”(或JMeterjmeter.save.saveservice.base_prefix属性中的任何内容)开头,则假定路径相对于JMX文件位置。 |
否 |
| 浏览... | 文件浏览按钮 | 否 |
| 仅错误日志 | 选择此选项可以写入/只读错误的结果 | 否 |
| 仅成功日志 | 选择此选项可以写入/读取没有错误的结果。如果未选择“仅错误日志”或“仅成功日志”,则处理所有结果。 |
否 |
| 配置 | 配置按钮,见下文 | 否 |
样本结果保存配置
监听器可以通过配置弹窗将不同的选项保存到结果日志文件(JTL),如下所示。默认值的定义如监听器默认配置文档中所述。后面带有(CSV)的选项仅适用于CSV格式;带有(XML)的选项仅适用于XML格式。目前CSV格式无法用于保存包含换行符的任何选项。
注意,cookie、方法和查询字符串将保存为“Sampler Data”选项的一部分。
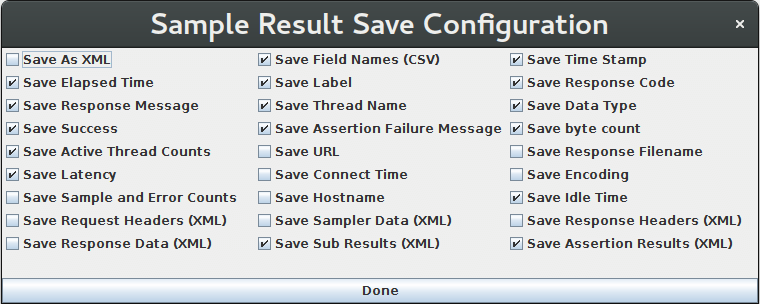
样本结果保存配置控制面板的截图
图形结果
在压力测试期间不得使用图形结果,因为它消耗了大量资源(内存和CPU)。仅用于功能测试或测试计划调试和验证期间。
图形结果监听器生成一个简单的图形,用于绘制所有取样时间。沿着图的底部,以毫秒为单位显示当前样本(黑色),所有样本的当前平均值(蓝色),当前标准差(红色)和当前吞吐量(绿色)。
吞吐量数字表示服务器处理的实际请求数/分钟数。此计算包括您添加到测试中的任何延迟以及JMeter自身的内部处理时间。像这样进行计算的优点是这个数字代表了一些真实的东西 - 你的服务器实际上每分钟处理了多少请求,你可以增加线程数和/或减少延迟来发现服务器的最大吞吐量。然而,如果您的计算考虑了延迟和JMeter的处理时间,那么您可能不清楚从该数字可以得出什么结论。
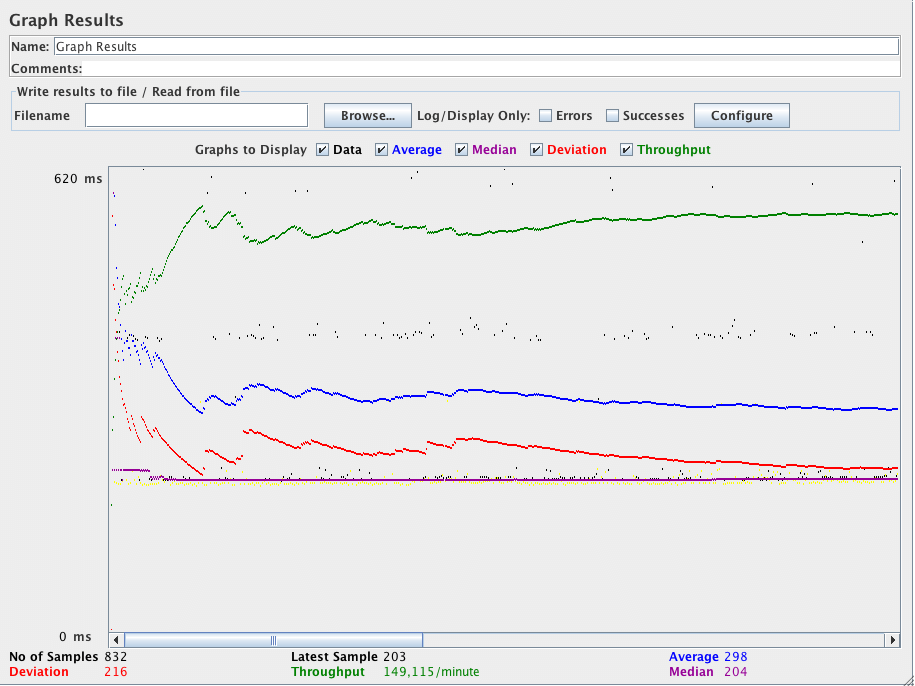
图形结果控制面板的截图
下表简要介绍了图表中的项目。关于统计术语的确切含义的更多细节可以在网上找到 - 例如维基百科 - 或者查阅统计书。
显示屏底部的各个数字是当前值。“最新样本”是当前经过的采样时间,在图表上显示为“数据”。
图表左上角显示的值是响应时间第90百分位数的最大值。
断言结果
在压力测试期间不得使用断言结果,因为它消耗了大量资源(内存和CPU)。仅用于功能测试或测试计划调试和验证期间。
断言结果可视化器显示每个样本的标签。它还报告了作为测试计划一部分的任何断言的失败。
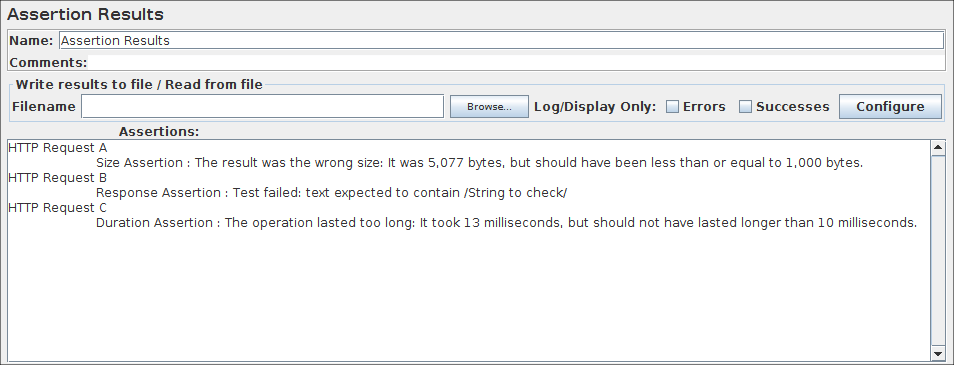
断言结果控制面板的截图
另请参阅:
查看结果树
在压力测试期间不得使用查看结果树,因为它消耗了大量资源(内存和CPU)。仅用于功能测试或测试计划调试和验证期间。
查看结果树是一个显示所有样本响应的树,允许您查看任何样本的响应。除了显示响应之外,您还可以看到获得此响应所花费的时间以及一些响应代码。注意请求面板仅显示JMeter添加的信息头。它不显示可由HTTP协议实现添加的任何信息头(例如Host)。
有几种方法可以查看响应,可以通过左侧面板底部的下拉框进行选择。
| 渲染 | 描述 |
|---|---|
CSS/JQuery Tester |
CSS/JQuery测试只适用于文本响应。它在上面板中显示纯文本。“测试”按钮允许用户将CSS/JQuery表达式应用于上面板,结果将显示在下面板中。CSS / JQuery表达式引擎可以是JSoup或Jodd,二者实现的语法略有不同。 例如,应用于当前JMeter函数页面的具有 href属性的选择器a[class=sectionlink]将给出以下输出:
|
Document |
Document视图将显示各种类型文档,如Microsoft Office(Word,Excel和PowerPoint 97-2003,2007-2010(OPENXML),Apache OpenOffice(writer, calc, impress),HTML,gzip,JAR/ZIP文件(内容列表)中提取的文本,以及“多媒体”文件的一些元数据,如mp3,mp4,flv等。支持格式的完整列表可在Apache Tika格式页面上找到。如果文档大于10MB,则不会显示。要更改此限制,请设置JMeter属性 document.max_size(单位为byte)或设置为0以移除限制。 |
HTML |
HTML视图试图将响应渲染为HTML。渲染的HTML可能与其他Web浏览器中的视图相比较差;但是,它确实提供了快速近似,有助于初始结果评估。 不下载图像,样式表等。 |
HTML (download resources) |
如果选择了HTML(download resources)视图选项,则渲染器可以下载HTML代码引用的图像,样式表等。 |
HTML Source formatted |
如果选择了HTML Source formatted视图选项,则渲染器将显示由Jsoup格式化和整理的HTML源代码。 |
JSON |
JSON视图将显示树风格的响应(也处理内含JSON的JavaScript响应)。 |
JSON Path Tester |
JSON Path Tester视图允许您测试JSON-路径表达式,并从一个特定的响应看到所提取的数据。 |
Regexp Tester |
Regexp Tester视图仅适用于文本响应。它在上面板中显示纯文本。“Test”按钮允许用户将正则表达式应用于上面板,结果将显示在下面板中。 正则表达式引擎与正则表达式提取器中使用的引擎相同。 例如,应用于当前JMeter主页的正则表达式 (JMeter\w*).*提供以下输出:
[]中的第一个数字是匹配号码;第二个数字是其所在分组。组[0]是与整个正则表达式匹配的。组[1]是与第1组相匹配的,即在这种情况下的(JMeter\w*)。见图9b(下图)。 |
Text |
默认的Text视图显示响应中包含的所有文本。注意这仅在响应content-type被视为文本时才有效。如果content-type以下列任何一个开头,则将其视为二进制文件,否则将其视为文本。
|
XML |
XML视图将显示树风格的响应。任何DTD节点或Prolog节点都不会显示在树中;但是,响应可能包含那些节点。您可以右键单击任何节点,然后展开或折叠其下的所有节点。 |
XPath Tester |
XPath Tester只适用于文本响应。它在上面板中显示纯文本。“Test”按钮允许用户将XPath查询应用于上面板,结果将显示在下面板中。 |
边界提取器测试 |
边界提取器测试只适用于文本响应。它在上面板中显示纯文本。“测试”按钮允许用户将边界提取器查询应用于上面板,结果将显示在下面板中。 |
Scroll automatically?选项允许在树选择中显示最后一个节点
从版本3.2开始,视图中的条目数限制为属性
view.results.tree.max_results的值,默认为500个条目。通过将属性设置为0可以恢复旧行为。请注意,这可能会占用大量内存。
通过“查找”选项,大多数视图还允许查找显示的数据;查询结果将在上面板中高亮显示。例如,下面的控制面板截图显示了查找“Java”的一个结果。注意搜索仅对可见文本进行操作,因此在搜索文本和HTML视图时可能会得到不同的结果。
注意:正则表达式使用Java引擎(不是正则表达式提取器或Regexp Tester视图使用的ORO引擎)。
如果未提供content-type,则内容将不会显示在任何响应数据面板中。在这种情况下,您可以使用保存响应到文件来保存数据。注意,响应数据在样本结果中仍然可用,因此可使用后置处理器进行访问。
如果响应数据大于200K,则不会显示。要更改此限制,请设置JMeter属性view.results.tree.max_size。您还可以使用保存响应到文件来保存整个响应。
可以创建其他渲染器。该类必须实现接口org.apache.jmeter.visualizers.ResultRenderer和/或扩展抽象类org.apache.jmeter.visualizers.SamplerResultTab,并且编译的代码必须可用于JMeter(例如,通过将其添加到lib/ext目录)。
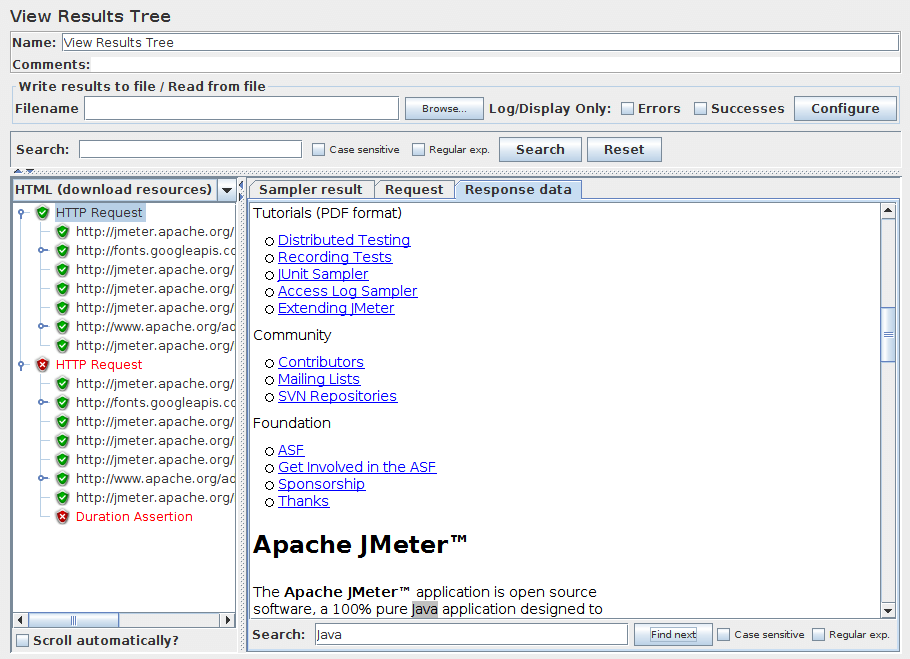
查看结果树控制面板的截图
上图控制面板是HTML显示的示例。 图9(下图)是XML显示的示例。 图9a(下图)是Regexp tester显示的示例。 图9b(下图)是Document显示的示例。
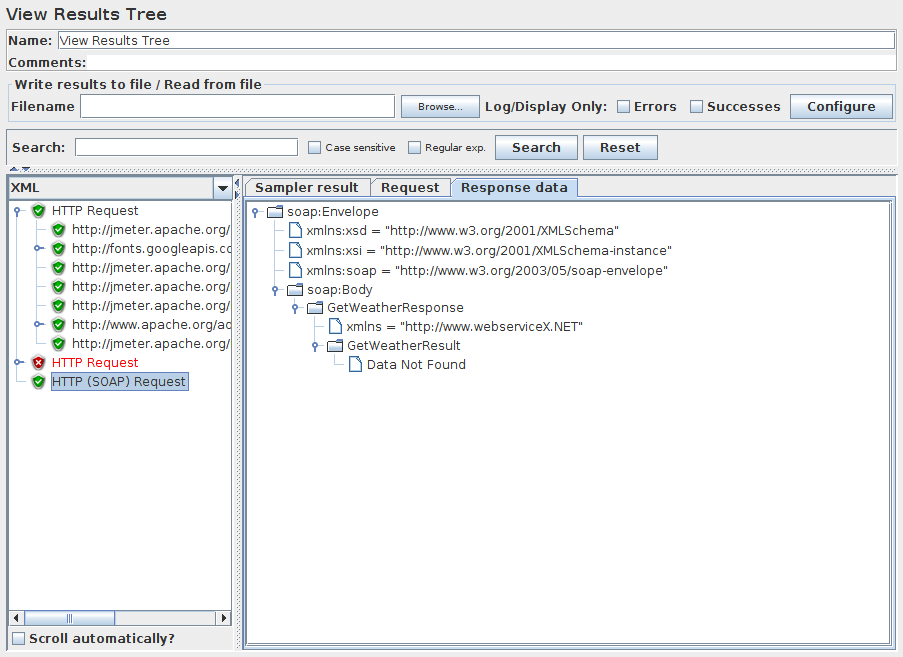
图9 - XML样本显示
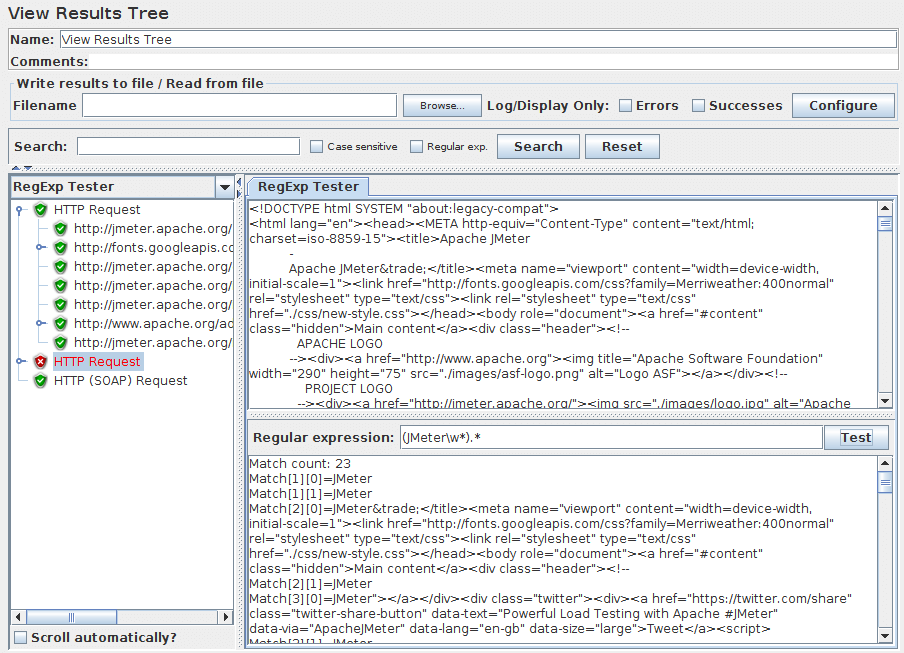
图9a - Regexp Tester样本显示
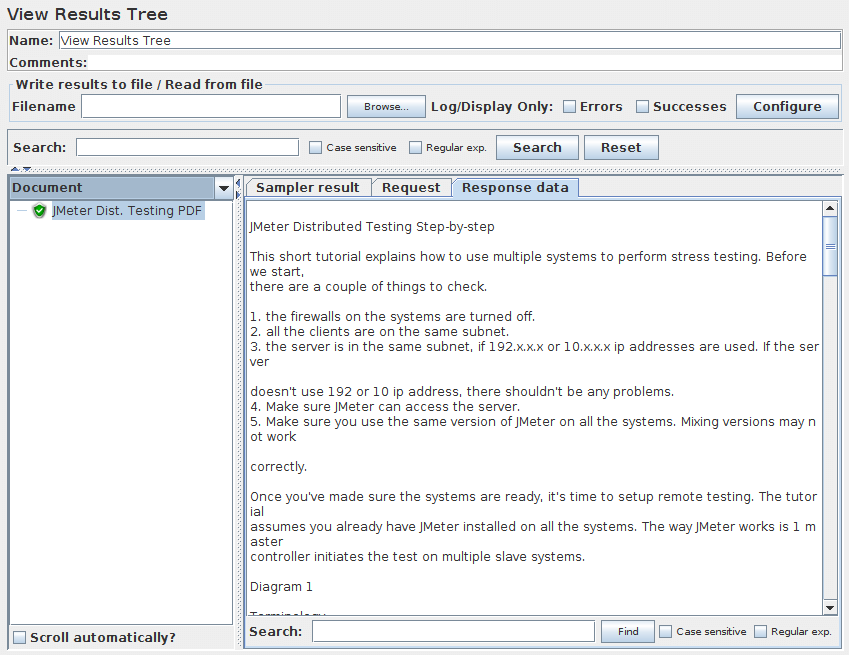
图9b - Document(此处为PDF)样本显示
聚合报告
聚合报告为测试中的每个不同命名的请求创建一个表行。对于每个请求,它总计响应信息并提供请求计数,最小值,最大值,平均值,异常率,近似吞吐量(请求/秒)和每秒千字节吞吐量。测试完成后,吞吐量是整个测试期间的实际吞吐量。
吞吐量是从取样器目标(例如,HTTP样本的远程服务器)的角度计算的。JMeter考虑了生成请求的总时间。如果其他取样器和定时器位于同一线程中,则会增加总时间,从而降低吞吐量值。因此,具有不同名称的两个相同的取样器将具有两个具有相同名称的取样器的吞吐量的一半。正确选择取样器名称以从聚合报告中获得最佳结果非常重要。
计算中位数和90%线(第90百分位数)值需要额外的内存。JMeter现在将相同经过时间的样本相结合,因此使用的内存更少。但是,对于花费时间超过几秒的样本,或者另一种可能性是很少的样本具有相同的时间,在这种情况下需要更多的内存。注意您可以使用此监听器在测试结束后重新加载CSV或XML结果文件,这是避免性能影响的推荐方法。请参阅汇总报告了解类似的监听器,它不存储单个样本,因此需要恒定的内存。
从JMeter 2.12开始,您可以通过设置属性来配置要计算的3个百分位值:
Label- 样本的标签。如果选择“在标签中包含组名称?”,则会添加线程组的名称作为前缀。这允许来自不同线程组的相同标签根据需要被单独整理。# 样本- 具有相同标签的样本数平均值- 一组结果的平均时间中位数- 中位数是一组结果中间的时间。50%的样本不超过这个时间;其余的至少花了这么长时间。90%百分位- 90%的样本不超过这个时间。剩下的样本至少花了这么长时间。(第90百分位数)95%百分位- 95%的样本不超过这个时间。剩下的样本至少花了这么长时间。(第95百分位数)99%百分位- 99%的样本不超过这个时间。剩下的样本至少花了这么长时间。(第99百分位数)最小值- 具有相同标签的样本的最短时间最大值- 具有相同标签的样本的最长时间异常 %- 异常请求的百分比吞吐量- 吞吐量以每秒/分钟/小时的请求来衡量。时间的单位会自动选择,使显示的速率至少为1.0。当吞吐量保存到CSV文件时,它以请求/秒表示,即30.0请求/分钟保存为0.5。接收 KB/sec- 以每秒收到的千字节为单位测量的吞吐量发送 KB/sec- 以每秒发送的千字节为单位测量的吞吐量
时间以毫秒为单位。
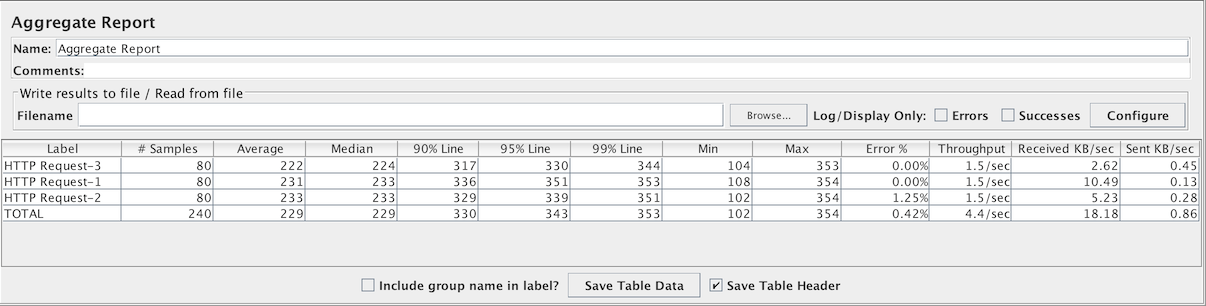
聚合报告控制面板的截图
下图显示了选择“在标签中包含组名称?”复选框的示例。
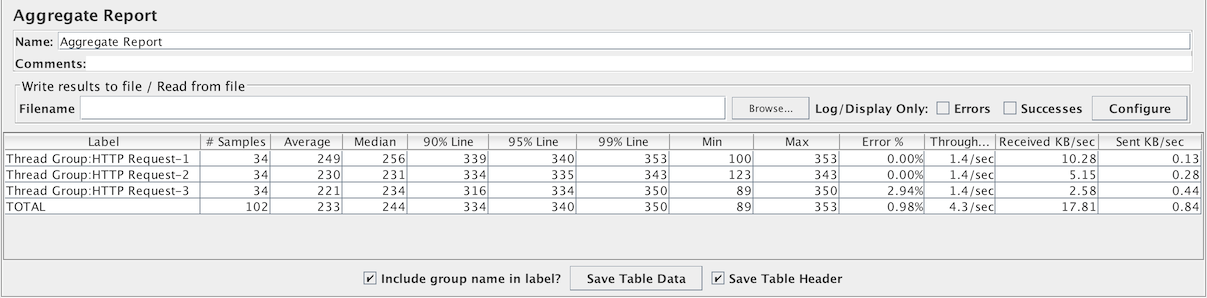 “
“在标签中包含组名称?”样本显示
用表格查看结果
此可视化工具为每个样本结果创建一行。像查看结果树一样,此可视化工具使用大量内存。
默认情况下,它只显示主(父)样本;它不显示子样本。JMeter有一个“Child Samples?”复选框。如果选择此选项,则显示子样本而不是主样本。
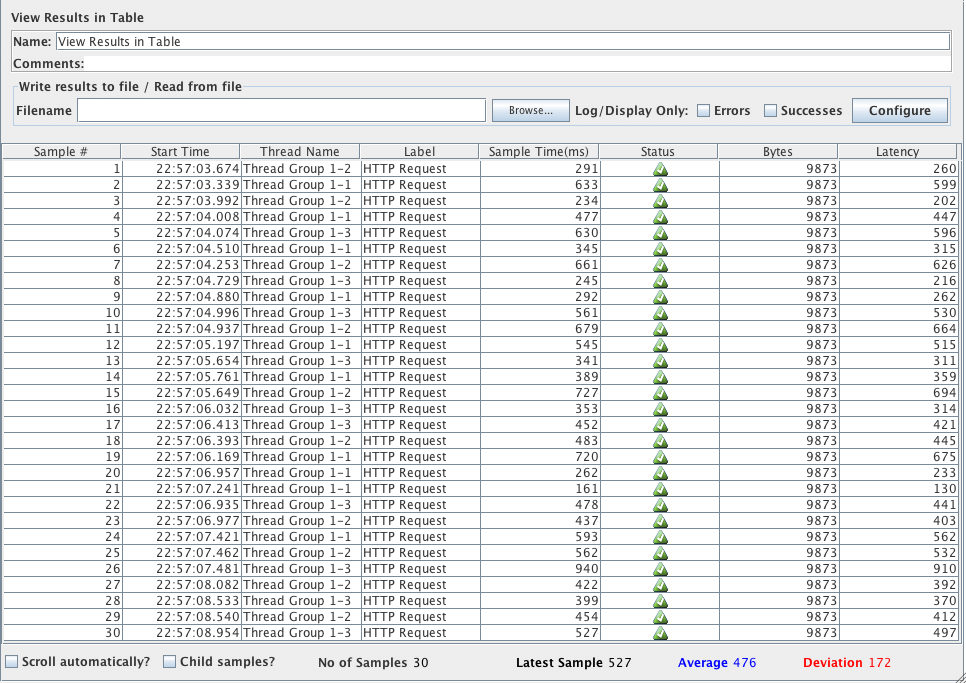
用表格查看结果控制面板的截图
简单数据写入器
此监听器可以将结果记录到文件中,但不能记录到UI。它旨在通过消除GUI开销来提供记录数据的有效方法。在CLI模式下运行时,-l标志可用于创建数据文件。要保存的字段由JMeter属性定义。有关详细信息,请参阅jmeter.properties文件。
简单数据写入器控制面板的截图
汇总图
汇总图与聚合报告类似。主要区别在于汇总图提供了一种生成条形图并将图形保存为PNG文件的简便方法。
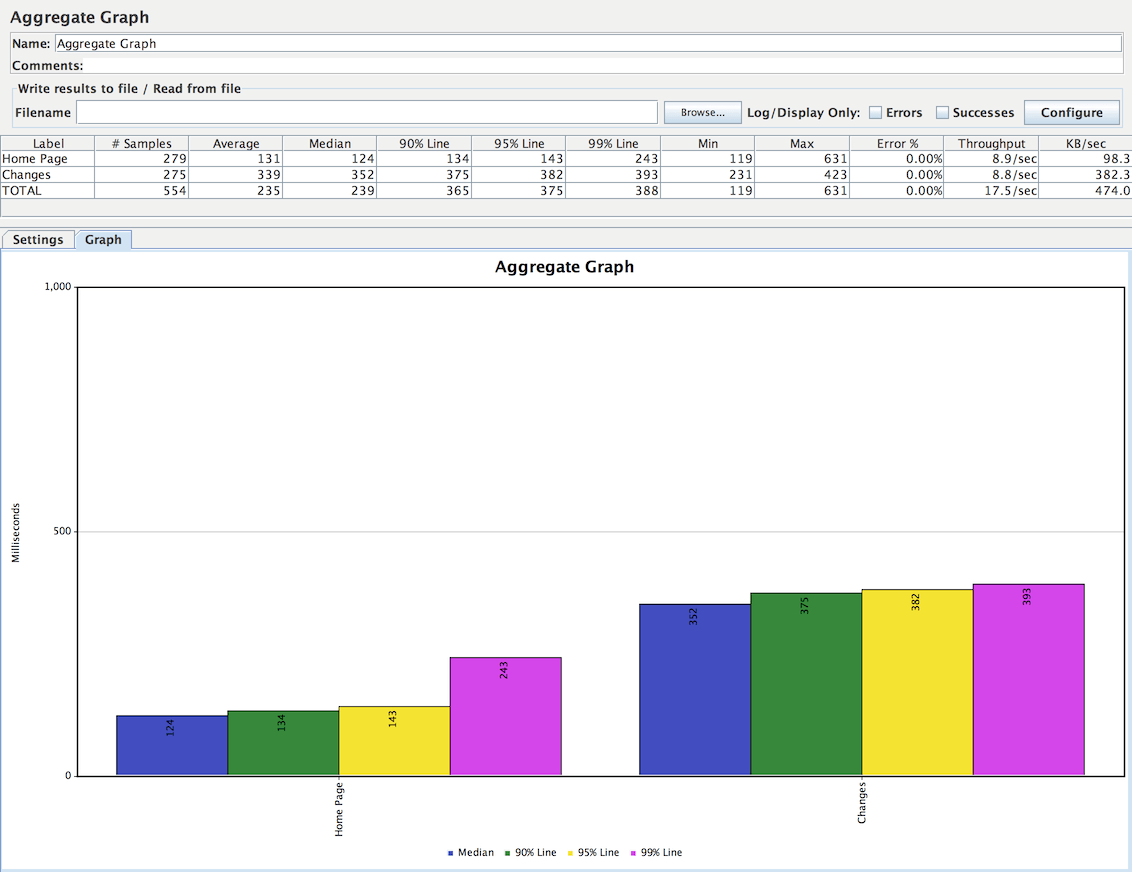
汇总图控制面板的截图
下图显示了绘制此图表的设置示例。
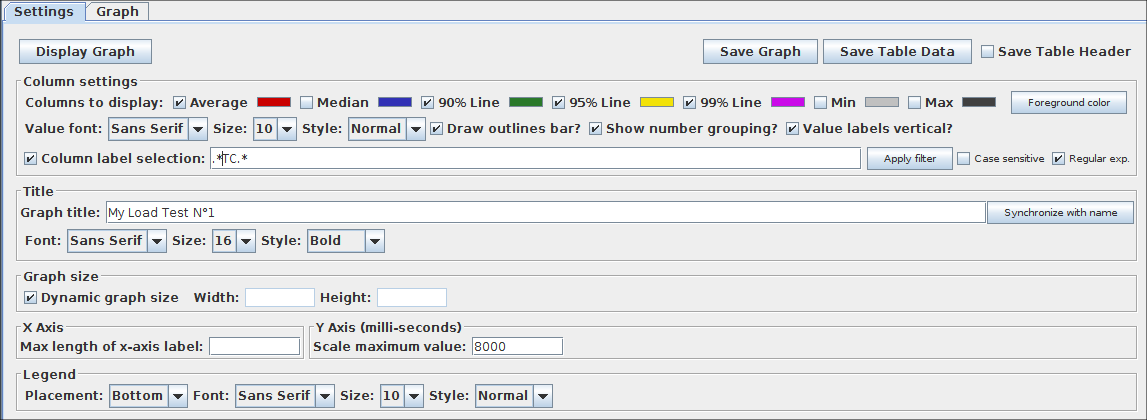 汇总图设置
汇总图设置
注意:所有这些参数都不会保存在JMeter JMX脚本中。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 列设置 |
|
是 |
| 标题 | 在图表的头部定义图表的标题。为空是默认值:“汇总图”。同步名称按钮使用监听器的标签定义标题,并定义图表标题的字体设置 |
否 |
| 图表大小 | 根据当前JMeter窗口大小的宽度和高度计算图形大小。使用宽和高度字段定义自定义大小。单位是像素。 |
否 |
| X轴设置 | 定义X轴标签的最大长度(以像素为单位)。 | 否 |
| Y轴设置 | 为Y轴定义自定义最大值。 | 否 |
| 图例 | 定义图表图例的放置和字体设置 | 是 |
响应时间图
响应时间图绘制了一个折线图,显示了测试期间每个标记请求的响应时间的演变。如果对于相同的时间戳存在许多样本,则显示平均值。
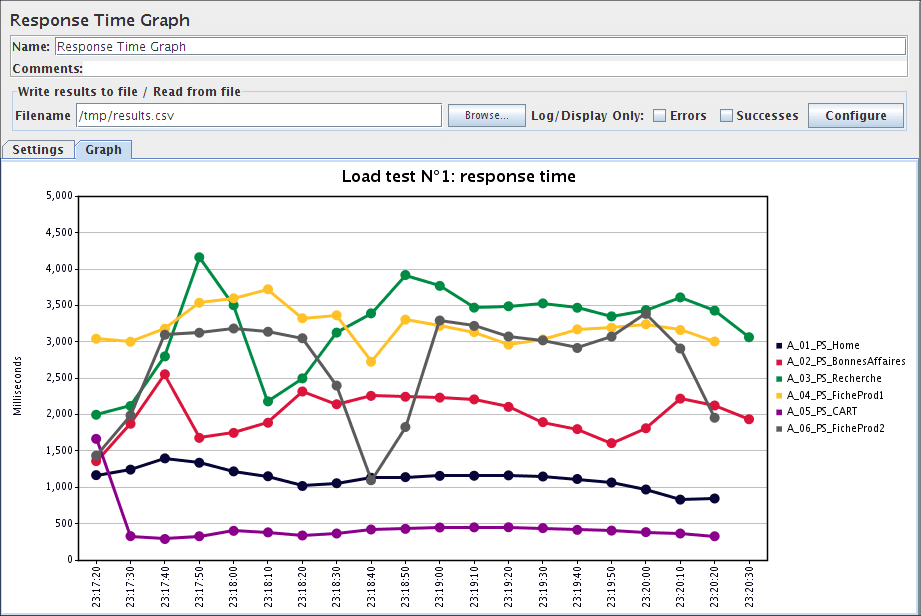
响应时间图控制面板的截图
下图显示了绘制此图表的设置示例。
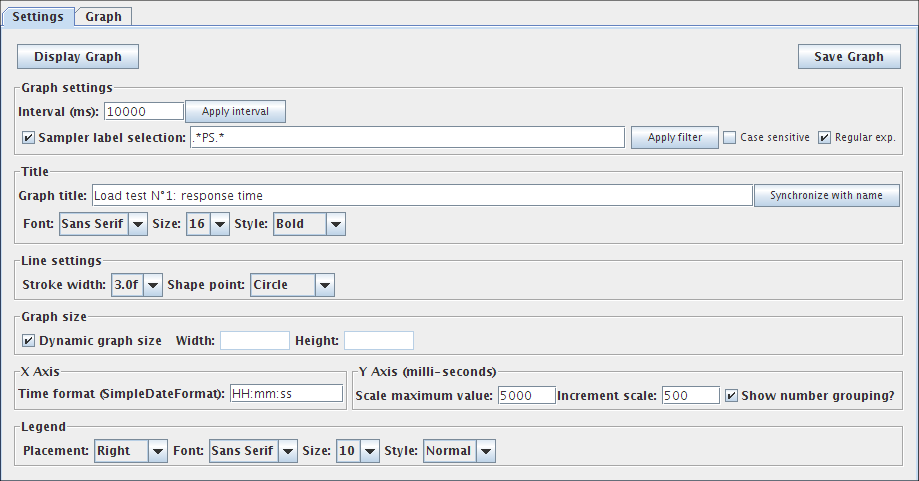
响应时间图设置
注意:所有这些参数都保存在JMeter
.jmx文件中。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 时间间隔(ms) | X轴间隔的时间(以毫秒为单位)。样本根据此值进行分组。在显示图表之前,单击应用区间按钮以刷新内部数据。 |
是 |
| 取样器标签选择 | 按结果标签过滤。可以使用正则表达式,例如.*Transaction.*。在显示图表之前,单击应用过滤器按钮以刷新内部数据。 |
否 |
| 标题 | 在图表的头部定义图表的标题。为空是默认值:“响应时间图”。同步名称按钮使用监听器的标签定义标题,并定义图表标题的字体设置 |
否 |
| 线设置 | 定义线的宽度。定义每个值点的类型。选择空以获得没有标记的行 |
是 |
| 图表大小 | 根据当前JMeter窗口大小的宽度和高度计算图形大小。使用宽和高度字段定义自定义大小。单位是像素。 |
否 |
| X轴设置 | 自定义X轴标签的日期格式。语法是JavaSimpleDateFormat API。 | 否 |
| Y轴设置 | 为Y轴定义自定义最大值(以毫秒为单位)。定义比例的增量(以毫秒为单位)。显示或不显示Y轴标签中的数字分组。 | 否 |
| 图例 | 定义图表图例的放置和字体设置 | 是 |
邮件观察仪
如果测试运行从服务器收到太多失败的响应,可以设置使用邮件观察仪发送电子邮件。
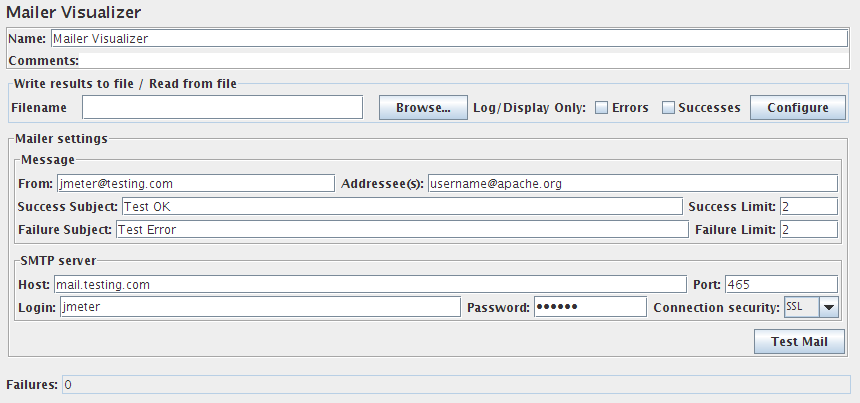
邮件观察仪控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| From | 用于发送邮件的电子邮件地址。 | 是 |
| Addressee(s) | 接收邮件的电子邮件地址,以逗号分隔。 | 是 |
| Success Subject | 成功消息的电子邮件主题行 | 否 |
| Success Limit | 一旦成功响应数量超过先前达到的失败的限制之后,将发送成功电子邮件。因此,邮件程序将以失败-成功-失败-成功这样的顺序发送消息。 | 是 |
| Failure Subject | 失败消息的电子邮件主题行 | 否 |
| Failure Limit | 一旦失败响应数量超过此数,就会发送失败的电子邮件 - 即将计数设置为0就会在第一次失败时发送电子邮件。 |
是 |
| Host | SMTP服务器(电子邮件重定向器)的IP地址或主机名。 | 否 |
| Port | SMTP服务器的端口(默认为25)。 |
否 |
| Login | 用于验证的登录。 | 否 |
| Password | 用于验证的密码。 | 否 |
| Connection security | SMTP身份验证的加密类型(SSL,TLS或无)。 | 否 |
| Test Mail | 按此按钮发送测试邮件 | 否 |
| Failures | 一个字段,用于保持迄今为止收到的故障总数。 | 否 |
BeanShell监听器
BeanShell监听器允许使用BeanShell处理样本以保存等。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223监听器 + Groovy,以提高性能,支持新的Java功能并减少BeanShell库的维护。
测试元件支持ThreadListener和TestListener方法。这些应该在初始化文件中定义。有关定义的示例,请参阅文件BeanShellListeners.bshrc。
BeanShell监听器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。该名称存储在脚本变量Label中 |
否 |
| 每次调用前重置bsh.Interpreter | 如果选择此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息,请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。文件名存储在脚本变量FileName中 |
否 |
| 脚本 | 要运行的BeanShell脚本。返回值被忽略。 | 是(除非提供脚本文件) |
在调用脚本之前,在BeanShell解释器中设置了一些变量:
-
log- (日志记录器) - 可用于写入日志文件 -
ctx- (JMeter上下文) - 允许访问上下文 -
vars- (JMeter变量) - 提供对变量的读/写访问:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
-
props- (JMeter属性 - 类java.util.Properties) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
sampleResult,prev- (SampleResult) - 提供对前一个SampleResult的访问 -
sampleEvent(SampleEvent)可以访问当前取样事件
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc。
如果定义了属性beanshell.listener.init,则用于加载初始化文件,该文件可用于定义在BeanShell脚本中使用的方法等。
汇总报告
汇总报告为测试中的每个不同命名的请求创建一个表行。这与聚合报告类似,只是它使用更少的内存。
吞吐量是从取样器目标(例如,HTTP样本的远程服务器)的角度计算的。JMeter考虑了生成请求的总时间。如果其他取样器和定时器位于同一线程中,则会增加总时间,从而降低吞吐量值。因此,具有不同名称的两个相同的取样器将具有两个具有相同名称的取样器的吞吐量的一半。正确选择取样器标签以从报告中获得最佳结果非常重要。
Label- 样本的标签。如果选择“在标签中包含组名称?”,则会添加线程组的名称作为前缀。这允许来自不同线程组的相同标签根据需要被单独整理。# 样本- 具有相同标签的样本数平均值- 一组结果的平均经过时间最小值- 具有相同标签样本的最短经过时间最大值- 具有相同标签样本的最长经过时间标准偏差- 样本经过时间的标准偏差异常 %- 异常请求的百分比吞吐量- 吞吐量以每秒/分钟/小时的请求来衡量。自动选择时间单位,使显示的速率至少为1.0。当吞吐量保存到CSV文件时,它以请求/秒表示,即30.0请求/分钟保存为0.5。接收 KB/sec- 以千字节/秒为单位测量的吞吐量发送 KB/sec- 以千字节/秒为单位测量的吞吐量平均字节数- 样本响应的平均大小(以byte为单位)。
时间以毫秒为单位。
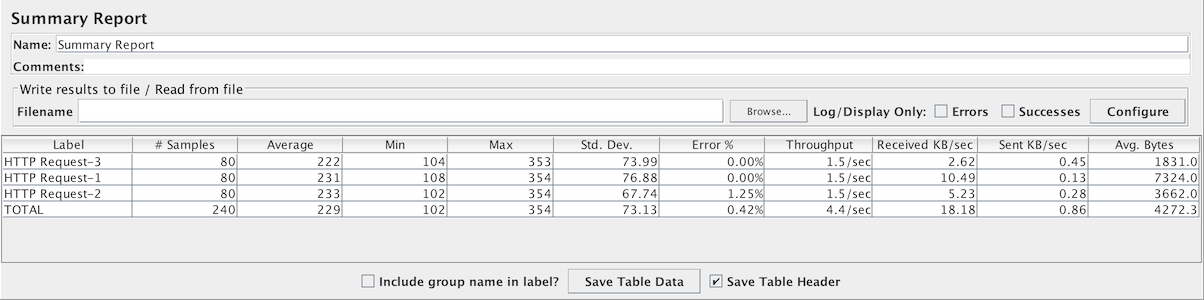
汇总报告控制面板的截图
下图显示了选择“包含组名称”复选框的示例。
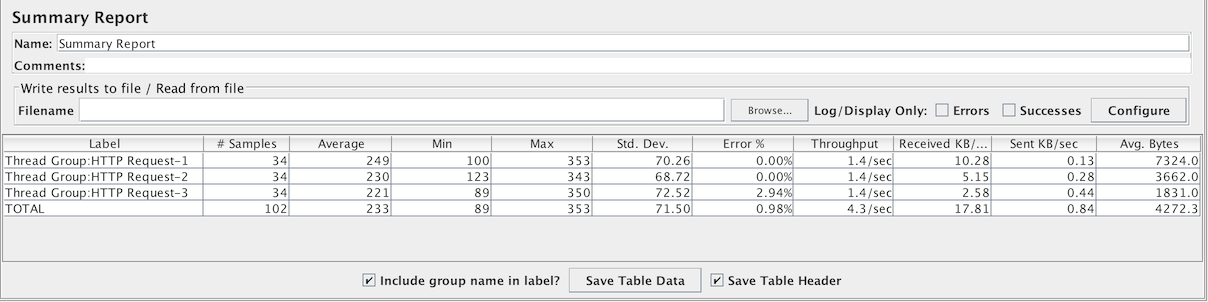 “
“包含组名称”样本显示
保存响应到文件
该测试元件可以放置在测试计划的任何位置。对于其范围内的每个样本,它都会创建响应数据的文件。这个的主要用途是创建功能测试,但在响应太大而无法在查看结果树监听器中显示的情况下,它也很有用 。文件名是根据指定的前缀和数字(除非禁用此参数,请参见下文)创建的。如果文档类型已知,则从文档类型创建文件扩展名。如果未知,则文件扩展名设置为“unknown”。如果禁用编号,并且禁用添加后缀,则将文件前缀作为整个文件名。这允许在需要时生成固定文件名。生成的文件名存储在样本响应中,如果需要,可以保存在测试日志输出文件中。
首先保存当前样本,然后保存任何子样本。如果提供了变量名称,则文件名将按子样本的显示顺序保存。见下文。
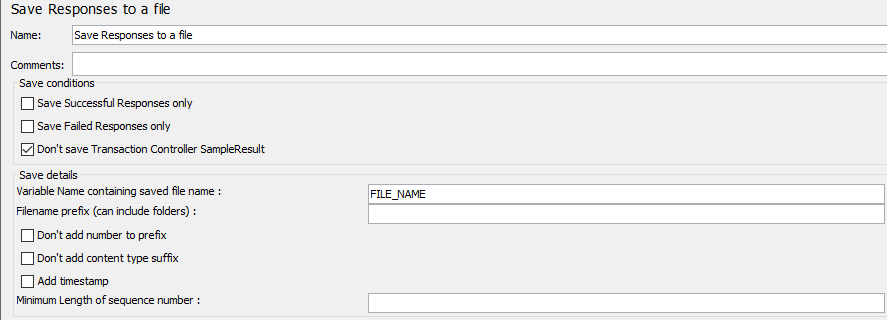
保存响应到文件控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 文件名前缀(可包含文件夹) | 生成的文件名的前缀;这可以包括目录名称。相对路径相对于当前工作目录(默认为bin/目录)进行解析。JMeter还支持相对于包含当前测试计划(JMX文件)的目录的路径。如果路径名以“〜/”(或JMeterjmeter.save.saveservice.base_prefix属性中的任何内容)开头,则假定路径相对于JMX文件位置。如果前缀中的父文件夹不存在,JMeter将创建它们,如果失败则停止测试。 注意文件名前缀不得包含与线程相关的数据,因此请勿在此字段中使用任何变量( |
是 |
| Variable Name containing saved file name | 用于保存生成的文件名的变量的名称(因此可以在测试计划中稍后使用)。如果有子样本,则会在变量名称中添加数字后缀。例如,如果变量名称为FILENAME,则父样本文件名保存在变量FILENAME中,子样本的文件名保存在FILENAME1,FILENAME2等中。 |
否 |
| Minimum Length of sequence number | 如果未选中“Don't add number to prefix”,则添加到前缀的数字将填充为0,前缀长度即为此值。默认为0。 |
否 |
| Save Failed Responses only | 如果选中,则仅保存失败的响应 | 是 |
| Save Successful Responses only | 如果选中,则仅保存成功的响应 | 是 |
| Don't add number to prefix | 如果选中,则前缀中不会添加任何数字。如果选择此选项,请确保前缀唯一,否则文件可能被覆盖。 | 是 |
| Don't add content type suffix | 如果选择,则不添加后缀。如果选择此选项,请确保前缀唯一,否则文件可能被覆盖。 | 是 |
| Add timestamp | 如果选中,则日期将包含在文件后缀中,格式为yyyyMMdd-HHmm_ |
是 |
| Don't Save Transaction Controller SampleResult | 如果选中,则将忽略事务控制器生成的取样结果 | 是 |
JSR223监听器
JSR223 监听器允许将JSR223脚本代码应用于样本结果。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 语言 | 要使用的JSR223语言 | 是 |
| 参数 | 要传递给脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的脚本的文件,如果使用相对文件路径,则它将相对于系统属性“user.dir”引用的目录 |
否 |
| 脚本编译缓存 | 测试计划中的唯一字符串,如果使用的语言支持Compilable接口(Groovy是其中之一,java,beanshell和javascript不是),则JMeter将用于缓存脚本编译的结果。如果您在不检查此选项的情况下使用Groovy,请参阅JSR223取样器Java系统属性中的注释 |
否 |
| 脚本 | 要运行的脚本。 | 是(除非提供脚本文件) |
在调用脚本之前,会设置一些变量。请注意,这些是JSR223变量 - 即它们可以直接在脚本中使用。
-
log(Logger) - 可用于写入日志文件
-
Label标签字符串
-
FileName脚本文件名(如果有)
-
Parameters参数(作为字符串)
-
ARGS作为字符串数组的参数(在空格上拆分)
-
CTX(JMeterContext) - 允许访问上下文
-
vars(JMeterVariables) - 提供对变量的读/写访问权限:
vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object()); vars.getObject("OBJ2");
-
props(JMeterProperties - 类java.util.Properties) - 例如
props.get("START.HMS");props.put("PROP1","1234"); -
sampleResult,prev(SampleResult) - 允许访问SampleResult
-
sampleEvent(SampleEvent) - 提供对SampleEvent的访问
-
sampler(取样器) - 允许访问最后一个取样器
-
OUTSystem.out- 例如OUT.println("message")
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc
生成概要结果
该测试元件可以放置在测试计划的任何位置。生成到目前为止测试运行的摘要到日志文件和/或标准输出。显示运行和差异总计。在适当的时间边界上每n秒(默认为30秒)生成输出,以便同步多个同时运行的测试。有关汇总器配置项,请参阅jmeter.properties文件:
# Define the following property to automatically start a summariser with that name
# (applies to CLI mode only)
#summariser.name=summary
#
# interval between summaries (in seconds) default 3 minutes
#summariser.interval=30
#
# Write messages to log file
#summariser.log=true
#
# Write messages to System.out
#summariser.out=true
该元件主要用于批处理(CLI)运行。输出如下所示:
label + 16 in 0:00:12 = 1.3/s Avg: 1608 Min: 1163 Max: 2009 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label + 82 in 0:00:30 = 2.7/s Avg: 1518 Min: 1003 Max: 2020 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 98 in 0:00:42 = 2.3/s Avg: 1533 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 85 in 0:00:30 = 2.8/s Avg: 1505 Min: 1008 Max: 2005 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 183 in 0:01:13 = 2.5/s Avg: 1520 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 79 in 0:00:30 = 2.7/s Avg: 1578 Min: 1089 Max: 2012 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 262 in 0:01:43 = 2.6/s Avg: 1538 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 80 in 0:00:30 = 2.7/s Avg: 1531 Min: 1013 Max: 2014 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 342 in 0:02:12 = 2.6/s Avg: 1536 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 83 in 0:00:31 = 2.7/s Avg: 1512 Min: 1003 Max: 1982 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 425 in 0:02:43 = 2.6/s Avg: 1531 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 83 in 0:00:29 = 2.8/s Avg: 1487 Min: 1023 Max: 2013 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 508 in 0:03:12 = 2.6/s Avg: 1524 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 78 in 0:00:30 = 2.6/s Avg: 1594 Min: 1013 Max: 2016 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 586 in 0:03:43 = 2.6/s Avg: 1533 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 80 in 0:00:30 = 2.7/s Avg: 1516 Min: 1013 Max: 2005 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 666 in 0:04:12 = 2.6/s Avg: 1531 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 86 in 0:00:30 = 2.9/s Avg: 1449 Min: 1004 Max: 2017 Err: 0 (0.00%) Active: 5 Started: 5 Finished: 0
label = 752 in 0:04:43 = 2.7/s Avg: 1522 Min: 1003 Max: 2020 Err: 0 (0.00%)
label + 65 in 0:00:24 = 2.7/s Avg: 1579 Min: 1007 Max: 2003 Err: 0 (0.00%) Active: 0 Started: 5 Finished: 5
label = 817 in 0:05:07 = 2.7/s Avg: 1526 Min: 1003 Max: 2020 Err: 0 (0.00%)
“label”是元件的名称。“+”意味着该行是一个变化行,即显示了从上次输出之后的变化。
“=”表示该行是一个总计行,即其示出了运行总数。
JMeter日志文件中的条目还包括时间戳。例如“817 in 0:05:07 = 2.7/s”表示在5分7秒内记录了817个样本,并且每秒处理2.7个样本。
Avg(平均值),Min(最小值)和Max(最大值)时间以毫秒为单位。
“Err”表示异常数量(也显示为百分比)。
最后两行将出现在测试结束时。它们不会与适当的时间边界同步。注意初始和最终变化量可能小于设置的间隔(在上面的示例中,是30秒)。第一个变化量通常较低,因为JMeter与间隔边界同步。最后的变化量将更低,因为测试通常不会在精确的间隔边界上完成。
标签用于将样本结果在一起分组。因此,如果您有多个线程组并希望对它���进行汇总,那么请使用相同的标签 - 或将汇总器添加到测试计划中(因此所有线程组都在范围内)。可以通过使用合适的标签并将摘要器添加到测试计划的适当部分来实现不同的概要分组。
在CLI模式,默认情况下会配置名为“
summariser”的生成概要结果监听器,如果您已在测试计划中添加了一个,请确保命名不同,否则将在此标签(概要)下累积结果,从而导致错误的结果(样本总和+位于生成摘要结果监听器父级下面的样本数)。 这不是一个bug,而是一个允许跨线程组进行汇总的设计选择。
生成摘要结果控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。它在输出中显示为“label”。具有相同标签的所有元件的详细信息将加到一起。 |
是 |
比较断言可视化器
比较断言可视化器显示任何比较断言元件的结果。
比较断言可视化器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
后端监听器
后端监听器是一个异步监听器,允许您插入BackendListenerClient的自定义实现。默认情况下,提供Graphite实现。
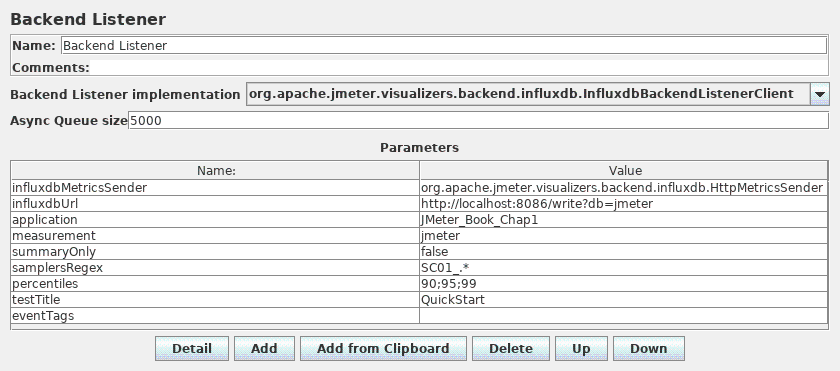
后端监听器控制面板的屏幕截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 是 |
| 后端监听器实现 | BackendListenerClient类的实现。 |
是 |
| 异步队列大小 | 异步处理的采样结果队列的大小。 | 是 |
| 参数 | BackendListenerClient实现的参数。 |
是 |
以下参数适用于GraphiteBackendListenerClient实现:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| graphiteMetricsSender | org.apache.jmeter.visualizers.backend.graphite.TextGraphiteMetricsSenderor或org.apache.jmeter.visualizers.backend.graphite.PickleGraphiteMetricsSender |
是 |
| graphiteHost | Graphite或InfluxDB(启用Graphite插件)服务器主机 | 是 |
| graphitePort | Graphite或InfluxDB(启用Graphite插件)服务器端口,默认为2003。注意PickleGraphiteMetricsSender(端口2004)只能与Graphite服务器通信。 |
是 |
| rootMetricsPrefix | 发送到后端的指标的前缀。默认为“jmeter.”。注意JMeter不会在根前缀和样本名称之间添加分隔符,这就是当前需要尾部点号的原因。 |
是 |
| summaryOnly | 仅发送没有详细信息的摘要。默认为true。 |
是 |
| samplersList | 定义要发送到后端的样本结果的名称(标签)。如果useRegexpForSamplersList=false则是一个以分号分隔的名称列表。如果useRegexpForSamplersList=true则是一个与名称匹配的正则表达式。 |
是 |
| useRegexpForSamplersList | 将samplersList视为正则表达式,以选择要将度量标准报告给后端的取样器。默认为false。 |
是 |
| percentiles | 要发送到后端的百分位数。百分位数可以包含小数部分,例如12.5。(分隔符始终为“.”)列表必须以分号分隔。通常3或4个值就足够了。 |
是 |
有关更多详细信息,请参阅实时结果。
Grafana仪表板
从JMeter 3.2开始,添加了一个允许使用自定义模式直接在InfluxDB中编写的新实现,它被称为InfluxdbBackendListenerClient。以下参数适用于InfluxdbBackendListenerClient实现:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| influxdbMetricsSender | org.apache.jmeter.visualizers.backend.influxdb.HttpMetricsSender |
是 |
| influxdbUrl | Influx URL (例如:http://influxHost:8086/write?db=jmeter) | 是 |
| application | 被测试应用的名称。此值也作为名为“application”的标记存储在“events”度量中 | 是 |
| measurement | 根据Influx线路协议参考来度量。默认为“jmeter”。 |
InfluxInflux是 |
| summaryOnly | 仅发送没有详细信息的摘要。默认为true。 |
是 |
| samplersRegex | 将与样本名称匹配并发送到后端的正则表达式。 | 是 |
| testTitle | 测试名称。默认为Test name。该值作为名为“text”的字段存储在“events”度量中。JMeter在测试的开始和结束时自动生成一个该值的注释,以'started'和'ended'结尾。 |
是 |
| eventTags | Grafana允许显示每个注释的标记。你可以在这里填写它们。该值作为名为“tags”的标记存储在“events”度量中。 | 否 |
| percentiles | 要发送到后端的百分位数。百分位数可以包含小数部分,例如12.5。(分隔符始终为“.”)列表必须以分号分隔。通常3或4个值就足够了。 |
是 |
| TAG_WhatEverYouWant | 您可以根据需要添加任意数量的自定义标签。对于它们中的每一个,只需创建一个新行并在其名称前加“TAG_” |
否 |
有关更多详细信息,另请参阅实时结果和Grafana中的Influxdb注释。
18.4 配置元件
配置元件可用于设置默认值和变量,供后续取样器使用。注意这些元件在它们范围开始处处理,即在相同范围内的任何取样器之前处理。
CSV 数据文件设置
CSV 数据文件设置用于从文件中读取行,并将它们拆分为变量。它比__CSVRead()和__StringFromFile()函数更容易使用。它非常适合处理大量变量,对于使用“随机”和唯一值进行测试也很有用。
在运行时生成唯一的随机值在CPU和内存消耗方面是很大的,因此最好在测试之前创建数据。如有必要,文件中的“随机”数据可以与运行时参数一起使用,以便在每次运行中创建不同的值集 - 例如使用级联 - 这比在运行时生成所有内容消耗的资源小得多。
JMeter允许引用值;这允许值包含分隔符。如果启用“是否允许带引号”,则可以用双引号括起值。双引号在引用时会被删除。要在引用字段中包含双引号,请使用两个双引号。例如:
1,"2,3","4""5" =>
1
2,3
4"5
JMeter支持带具有定义列名称的标题行的CSV文件。要启用此功能,请将“变量名称”字段留空。还必须提供正确的分隔符。
JMeter支持包含新行的带引号数据的CSV文件。
默认情况下,文件只打开一次,每个线程将使用文件中的不同行。但是,行传递给线程的顺序取决于它们执行的顺序,这可能在迭代之间有所不同。在每次测试迭代开始时读取行。在第一次迭代中解析文件名和模式。
有关其他选项,请参阅下面的共享模式说明。如果您希望每个线程都有自己的一组值,那么您将需要创建一组文件,每个线程对应一个。例如test1.csv,test2.csv,...,testn.csv。使用文件名test${__threadNum}.csv并将“线程共享模式”设置为“当前线程”。
CSV 数据文件变量在每次测试迭代开始时定义。由于这是在配置处理完成之后,它们不能用于某些配置选项 - 例如JDBC配置 - 在配置时处理它们的内容(参见Bug 40394)。但是变量在HTTP授权管理器中起作用,如
用户名等。因为是在运行时处理。
作为一种特殊情况,分隔符字段中的字符串“ \t”(不带引号)被视为制表符(Tab)。
到达文件结尾(EOF)并且循环选项为true时,将再次从文件的第一行开始读取。
如果再次循环选项为false,并且停止线程为false,则在到达文件末尾时,所有变量都将设置为<EOF>。可以通过设置JMeter属性csvdataset.eofstring来更改此值。
如果再次循环选项为false,并且止线程为true,则到达EOF将导致线程停止。
CSV 数据文件设置控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 文件名 | 要读取的文件的名称。 根据活动测试计划的路径解析相对文件名。对于分布式测试,CSV文件必须存储在服务器主机系统上与JMeter服务器启动的正确相对目录中。 也支持绝对文件名,但请注意,除非远程服务器具有相同的目录结构,否则它们不太可能在远程模式下工作。如果以两种不同的方式引用相同的物理文件 - 例如csvdata.txt和./csvdata.txt - 则将这些文件视为不同的文件。如果操作系统不区分大小写,则csvData.TXT也将被视为不同文件单独打开。 |
是 |
| 文件编码 | 用于读取文件的编码,如果不是平台默认值。 | 否 |
| 变量名称 | 变量名称列表。名称必须用分隔符分隔。可以使用双引号引用它们。JMeter支持CSV标题行:如果变量名称字段为空,则读取文件的第一行并将其解释为列名列表。 | 否 |
| 忽略首行 | 忽略CSV文件的第一行,仅当变量名称不为空时才使用它,如果变量名称为空,则第一行必须包含标题。 | 否 |
| 分隔符 | 用于拆分文件记录的分隔符。如果一行上的值少于变量数,则其余变量不会更新 - 因此它们将保留其先前的值(如果有)。 | 是 |
| 是否允许带引号? | CSV文件是否允许值带引号?如果启用,则可以将值括在" - 双引号中,允许值包含分隔符。 |
是 |
| 遇到文件结束符再次循环? | 是否在达到EOF时从头开始重新读取文件?(默认为true) |
是 |
| 遇到文件结束符停止线程? | 如果再次循环设置为false,线程是否在EOF上停止(默认为false) |
是 |
| 线程共享模式 |
|
是 |
FTP请求默认值
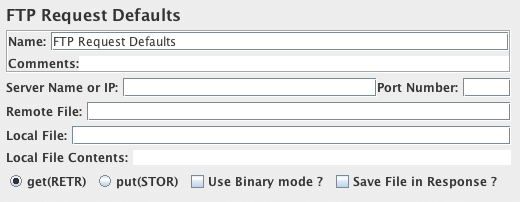
FTP请求默认值控制面板的截图
DNS缓存管理器
当用户从不同的IP接收内容时,DNS缓存管理器元件允许测试在负载平衡器(CDN等)后面有多个服务器的应用程序。默认情况下,JMeter使用JVM DNS缓存。这就是集群中只有一台服务器接收负载的原因。DNS缓存管理器在每次迭代时分别解析每个线程的名称,并将解析结果保存到其内部DNS缓存中,该缓存独立于JVM和系统DNS缓存。
静态主机的映射可用于模拟/etc/hosts文件之类的。这些条目将优先于自定义解析程序。如果要使用此映射,则必须启用Use custom DNS resolver。
静态主机表的用法
比如,您有一个测试服务器,您希望使用名称来访问,该名称尚未在您的DNS服务器中设置。在我们的例子中,服务器名称是www.example.com,您希望通过服务器的IP地址a123.another.example.org来访问。您可以更改工作站并在
/etc/hosts文件中添加条目- 或者等效于在您的操作系统中,在DNS缓存管理器的静态主机表中添加条目。您可以在第一列(
Host)中键入www.example.com, 在第二列(Hostname or IP address)中键入a123.another.example.org。正如第二列的名称所暗示的那样,您甚至可以使用测试服务器的IP地址。将使用自定义DNS解析程序查找测试服务器的IP地址。如果没有给出,将使用系统DNS解析器。
现在,您可以在HTTPClient4取样器中使用
www.example.com,并且对于a123.another.example.org的所有请求,使用www.example.com设置的信息头。
DNS缓存管理器控制面板的截图
DNS缓存管理器设计用于在线程组或测试计划的根节点中使用。不要将其作为特定HTTP取样器的子元件
DNS缓存管理器仅适用于使用HTTPClient4实现的HTTP请求。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 在每次迭代中清除缓存 | 如果选中,则每次启动新迭代时都会清除每个线程的DNS缓存。 | 否 |
| Use system DNS resolver | 将使用系统DNS解析程序。要使它能正确工作,需要编辑$JAVA_HOME/jre/lib/security/java.security并添加networkaddress.cache.ttl=0 |
N/A |
| Use custom DNS resolver | 将使用自定义DNS解析器(来自dnsjava库)。 | N/A |
| Hostname or IP address | 要使用的DNS服务器列表。如果为空,将使用网络配置DNS。 | 否 |
| 添加按钮 | 将条目添加到DNS服务器表。 | N/A |
| 删除按钮 | 删除当前选定的表条目。 | N/A |
| Host and Hostname or IP address | 将主机名映射到静态主机条目,该条目将使用自定义DNS解析程序解析。 | 否 |
| 添加静态主机按钮 | 将条目添加到静态主机表。 | N/A |
| 删除静态主机按钮 | 删除表中当前选定的静态主机。 | N/A |
HTTP授权管理器
授权管理器允许您为使用服务器身份认证限制的网页指定一个或多个用户登录。当您使用浏览器访问受限页面时,您会看到此类型的身份认证,并且浏览器会显示登录对话框。JMeter在遇到此类页面时会传输登录信息。
授权信息头可能不会显示在树视图监听器“请求”选项卡中。Java实现会执行抢先认证,但在JMeter获取信息头时它不会返回授权信息头。HttpComponents(HC 4.5.X)实现从3.2版本之后默认执行抢先认证,并且显示信息头。要禁用此功能,请按下面方式设置值,在这种情况下,只有响应质询时会执行身份认证。
在jmeter.properties文件中设置httpclient4.auth.preemptive=false
注意:以上设置仅适用于HttpClient取样器。
在查找URL匹配时,JMeter依次检查每个条目,并在找到第一个匹配时停止。因此,最明确的URL应首先出现在列表中,然后是不太明确的URL。重复的网址将被忽略。如果要为不同的线程使用不同的用户名/密码,可以使用变量。这些可以通过CSV数据文件设置元件(举例)进行设置。
HTTP授权管理器控制面板的截图
如果取样器范围内有多个授权管理器,目前是无法指定要使用哪个的。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 在每次迭代中清除认证? | 由Kerberos身份认证使用。如果选中,则将对主线程组循环的每次迭代进行身份认证,即使它已在前一个迭代中完成。要使每个主线程组迭代表示一个虚拟用户的行为时,这通常很有用。 | 是 |
| 基础URL | 与一个或多个HTTP请求URL匹配的部分或完整URL。例如,假设您指定一个基础URL为“http://localhost/restricted/”,其用户名为“jmeter”,密码为“jmeter”。如果您向URL“http://localhost/restricted/ant/myPage.html” 发送HTTP请求,则授权管理器会发送名为“jmeter” 的用户的登录信息。 |
是 |
| 用户名 | 要授权的用户名。 | 是 |
| 密码 | 用户的密码。(注意,这在测试计划中没有加密存储) | 是 |
| 域 | NTLM的域。 | 否 |
| Realm | NTLM的领域。 | 否 |
| Mechanism | 要执行的身份认证类型。JMeter可以根据使用的不同Http取样器执行不同类型的身份认证:
|
否 |
Realm仅适用于HttpClient取样器。
Kerberos配置:
要配置Kerberos,您需要设置至少两个JVM系统属性:
-Djava.security.krb5.conf=krb5.conf-Djava.security.auth.login.config=jaas.conf
您还可以在文件bin/system.properties中配置这两个属性。查看位于JMeterbin文件夹中的两个示例配置文件(krb5.conf和jaas.conf),以获取对更多文档的引用,并调整它们以匹配您的Kerberos配置。
SPNEGO默认禁用证书授权。可以通过将属性kerberos.spnego.delegate_cred设置为true来启用它。
为Kerberos SPNEGO授权生成SPN时,IE和Firefox将省略URL中的端口号。如果端口号与标准端口号不同(80和443),Chrome有一个选项(--enable-auth-negotiate-port)可以包含端口号。可以通过设置以下JMeter属性来模拟该行为。
在jmeter.properties或user.properties中,设置:
kerberos.spnego.strip_port=false
控制:
添加按钮 - 向授权表添加条目。删除按钮 - 删除当前选定的表条目。载入按钮 - 加载以前保存的授权表,并将条目添加到现有授权表条目中。保存测试计划按钮 - 将当前授权表保存到文件中。
保存测试计划时,JMeter会自动保存所有授权表条目 - 包括任何未加密的密码。
授权示例
下载此示例。在此示例中,我们在本地服务器上创建了一个测试计划,该服务器发送3个HTTP请求,两个需要登录,另一个对所有人开放。请参见图10,了解我们的测试计划的组成。在我们的服务器上,我们有一个名为“
secret” 的受限目录,其中包含两个文件“index.html”和“index2.html”。我们创建了一个名为“kevin” 的登录ID ,其密码为“spot”。因此,在我们的授权管理器中,我们为受限目录创建了一个带用户名和密码的条目(参见图11)。名为“SecretPage1”和“SecretPage2” 的两个HTTP请求发送到”/secret/index.html“和”/secret/index2.html“。另一个名为”NoSecretPage“的HTTP 请求发送到”/index.html“ 。
图10 - 测试计划
图11 - 授权管理器控制面板当我们运行测试计划时,JMeter在授权表中查找它请求的URL。如果基本URL与URL匹配,则JMeter会将此信息与请求一起传递。
您可以下载测试计划,但由于它是作为本地服务器的测试而构建的,因此您将无法运行它。但是,您可以将其用作构建自己的测试计划的参考。
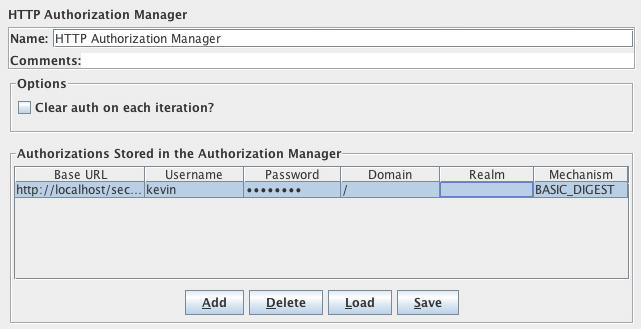
HTTP缓存管理器
HTTP缓存管理器用于向其范围内的HTTP请求添加缓存功能,以模拟浏览器缓存功能。每个虚拟用户线程都有自己的缓存。默认情况下,缓存管理器将使用LRU算法在每个虚拟用户线程的缓存中存储多达5000个项目。使用属性“maxSize”修改此值。注意,此值增加越多,HTTP缓存管理器消耗的内存也越多,因此请务必相应地调整-XmxJVM选项。
如果样本成功(即响应代码为2xx),则会为URL保存Last-Modified和Etag(以及相关的Expired)值。在执行下一个样本之前,取样器会检查缓存中是否有条目,如果是,则为请求设置If-Last-Modified和If-None-Match条件信息头。
此外,如果选择“Use Cache-Control/Expires header”选项,则会根据当前时间检查Cache-Control/Expires值。如果请求是GET请求,并且时间戳是将来的,则取样器会立即返回,而不从远程服务器请求URL。这旨在模拟浏览器行为。请注意,如果Cache-Control信息头为“no-cache”,则响应将作为预过期存储在缓存中,因此将生成条件GET请求。如果Cache-Control有任何其他值,则“max-age“到期选项将会执行以计算条目生存期,如果丢失则将使用expire信息,如果还缺失条目将按照RFC 2616第13.2.4节中的规定使用Last-Modified时间和响应日期进行缓存。
如果请求的文档在缓存后没有更改,则响应正文将为空。同样,如果
Expires日期是将来。这可能会导致断言出现问题。
HTTP缓存管理器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 在每次迭代中清除缓存 | 如果选中,则在线程开始时清除缓存。 | 是 |
| Use Cache Control/Expires header when processing GET requests | 见上面的描述。 | 是 |
| 缓存中元素的最大数量 | 见上面的描述。 | 是 |
HTTP Cookie管理器
Cookie管理器元件有两个功能: 首先,它像Web浏览器一样存储和发送Cookie。如果您有HTTP请求并且响应包含cookie,则Cookie管理器会自动存储该cookie,并将其用于之后对该特定网站的所有请求。每个JMeter线程都有自己的“cookie存储区”。因此,如果您正在测试使用cookie存储会话信息的网站,则每个JMeter线程都将拥有自己的会话。注意这样的Cookie不会显示在Cookie管理器显示屏上,但可以使用“查看结果树监听器”查看它们。
JMeter检查收到的cookie是否对URL有效。这意味着不存储跨域cookie。如果您有窃听行为或希望使用跨域cookie,请定义JMeter属性“CookieManager.check.cookies=false”。
收到的Cookie可以存储为JMeter线程变量。要将cookie保存为变量,请定义属性“CookieManager.save.cookies=true”。此外,cookie名称在存储之前以“COOKIE_” 为前缀(这可以避免意外损坏局部变量)。要恢复原始行为,请定义属性“CookieManager.name.prefix=”(一个或多个空格)。如果启用,名称为TEST的cookie的值可以被${COOKIE_TEST}引用。
其次,您可以手动将Cookie添加到Cookie管理器。但是,如果这样做,cookie将被所有JMeter线程共享。
注意,此类Cookie创建时的过期时间过长
默认情况下,将忽略具值为null的Cookie 。这可以通过设置JMeter属性来更改:CookieManager.delete_null_cookies=false。注意这也适用于手动定义的cookie - 任何这样的cookie将在更新时不再显示。另请注意,所有cookie名称必须是唯一的 - 如果第二个cookie使用相同的名称定义,则它将替换第一个cookie。
HTTP Cookie管理器的控制面板的截图
如果取样器范围内有多个Cookie管理器,目前无法指定要使用哪个Cookie管理器。此外,存储在一个cookie管理器中的cookie不可用于任何其他管理器,因此请谨慎使用多个Cookie管理器。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 每次反复清除Cookies | 如果选中,则每次执行主线程组循环时都会清除所有服务器定义的cookie。GUI中定义的任何cookie都不会被清除。 | 是 |
| Cookie 策略 | 将用于管理cookie的cookie策略。“standard”是3.0以来的默认值,在大多数情况下应该都有效。请参阅Cookie规范和CookieSpec实现 [注意:“ignoreCookies”相当于忽略Cookie管理器。 |
是 |
| 实现 | HC4CookieHandler(HttpClient 4.5.X API)。自3.0以来默认为HC4CookieHandler。 [注意:如果您有要使用IPv6地址进行测试的网站,请选择HC4CookieHandler(兼容IPv6)] |
是 |
| 用户定义的Cookie | 这使您有机会使用在测试执行期间将由所有线程共享的硬编码cookie。 “ domain”是服务器的主机名(不包括http://); 端口号目前被忽略。 |
不建议使用(除非你知道你在做什么) |
| 添加按钮 | 在cookie表中添加一个条目。 | N/A |
| 删除按钮 | 删除当前选定的表条目。 | N/A |
| 载入按钮 | 加载以前保存的cookie表,并将条目添加到现有cookie表条目中。 | N/A |
| 保存测试计划按钮 | 将当前cookie表保存到文件中(不保存从HTTP响应中提取的任何cookie)。 | N/A |
HTTP请求默认值
此元件允许您设置HTTP请求控制器使用的默认值。例如,如果要创建具有25个HTTP请求控制器的测试计划并且所有请求都发送到同一服务器,则可以添加单个HTTP请求默认值元件,并填写“服务器名称或IP”字段。然后,当您添加25个HTTP请求控制器时,请将“服务器名称或IP”字段留空。控制器将从HTTP请求默认值元件继承此字段值。
所有端口的值也同样处理;未指定端口的取样器将使用HTTP请求默认值里的端口号(如果提供了端口)。
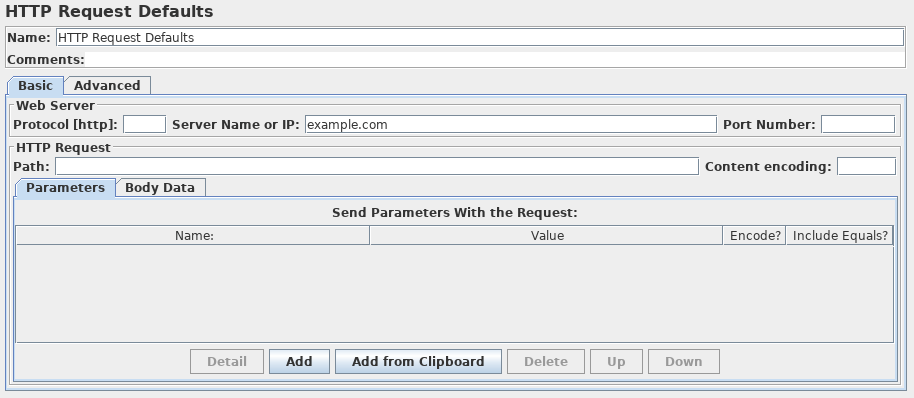
HTTP请求默认值控制面板的截图
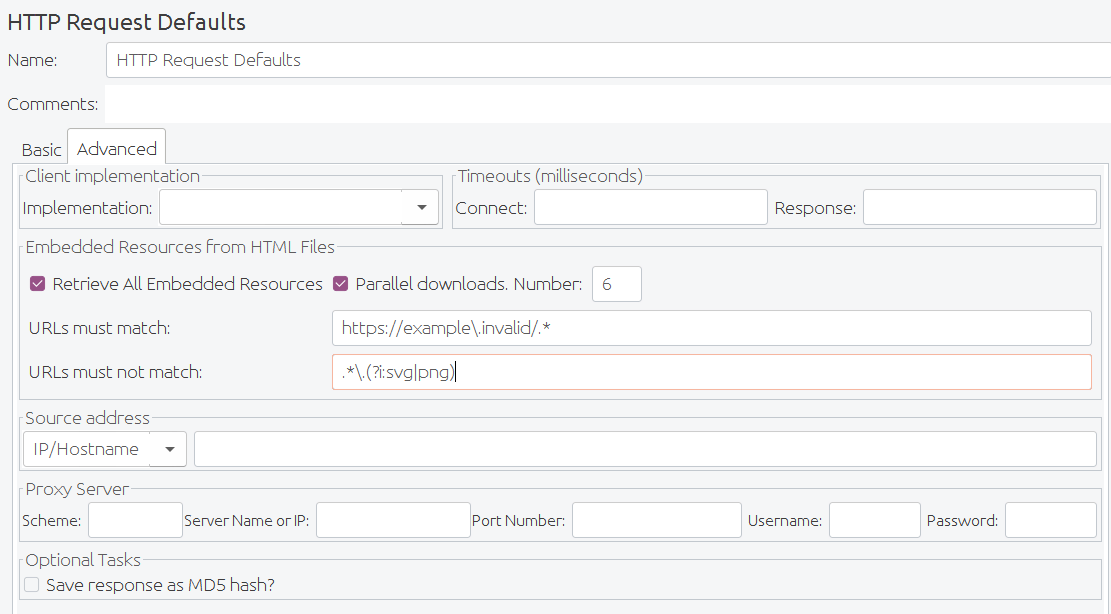
HTTP请求高级配置字段
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。 | 否 |
| 服务器 | web服务器的域名或IP地址,例如www.example.com。【不包含http://前缀。】 |
否 |
| 端口 | Web服务器监听的端口。 | 否 |
| 连接超时 | 连接超时。等待连接打开的毫秒数。 | 否 |
| 响应超时 | 响应超时。等待响应的毫秒数。 | 否 |
| 实现 | Java,HttpClient4。如果未指定,则默认值取JMeter属性jmeter.httpsampler的值。如果仍取不到值,则使用Java实现。 |
否 |
| 协议 | HTTP或HTTPS 。 |
否 |
| 内容编码 | 用于请求的编码。 | 否 |
| 路径 | 资源的路径(例如,/servlets/myServlet)。如果资源需要查询字符串参数,请将参数添加到“同请求一起发送参数”部分中。注意,路径是完整路径的默认路径,而不是要应用于HTTP请求屏幕上指定的路径的前缀。 |
是 |
| 同请求一起发送参数 | 查询字符串将从您提供的参数列表中生成。每个参数都有一个名称和 值。查询字符串将以正确的方式生成,具体取决于您所选择的“方法”(即,如果您选择GET,查询字符串将附加到URL上,如果是POST,则将单独发送)。此外,如果使用multipart form发送文件,则将使用multipart form规范创建查询字符串。 |
否 |
| 服务器(代理) | 要执行请求的代理服务器的主机名或IP地址。【不包含http://前缀。】 |
否 |
| 端口 | 代理服务器监听的端口。 | 否,除非指定了代理主机名 |
| 用户名 | (可选)代理服务器的用户名。 | 否 |
| 密码 | (可选)代理服务器的密码。(注意,它在测试计划中没有加密存储) | 否 |
| 从HTML文件获取所有内含的资源 | 告诉JMeter解析HTML文件并发送文件中引用的所有图像,Java小程序,JavaScript文件,CSS等的HTTP/HTTPS请求。 | 否 |
| 使用并发池 | 使用并发连接来获取内含的资源。 | 否 |
| 数量 | 用于获取内含的资源的并发连接池大小。 | 否 |
| 内含的网址必须匹配: | 如果选中,则必须填入正则表达式,用于与找到的所有内含的URL匹配。因此,如果您只想从http://example.com/下载内含的资源,请使用以下表达式: http://example\.com/.* |
否 |
注意:单选按钮只有两种状态 - 开或关。这使得无法一致地覆盖设置 - 关闭意味着关闭,还是意味着使用当前默认设置?JMeter使用后者(否则默认值根本不起作用)。因此,如果按钮关闭,则后面的元件可以将其设置为打开,但如果按钮处于打开状态,则后面的元件无法将其设置为关闭。
HTTP信息头管理器
信息头管理器允许您添加或覆盖HTTP请求信息头。
JMeter现在支持多个信息头管理器。合并信息头条目以形成取样器的列表。如果要合并的条目与现有信息头名称匹配,则它将替换先前的条目。这允许您设置一组默认信息头,并对特定取样器应用调整。注意信息头的空值不会删除现有信息头,只是替换其值。
HTTP信息头管理器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 名称(信息头) | 请求信息头的名称。您可能想要尝试的两个常见请求信息头是“User-Agent”和“Referer”。 |
否(但应该至少有一个) |
| 值 | 请求信息头的值。 | 否(但应该至少有一个) |
| 添加按钮 | 在信息头表中添加一个条目。 | N/A |
| 删除按钮 | 删除当前选定的表条目。 | N/A |
| 载入按钮 | 加载以前保存的信息头表,并将条目添加到现有信息头表条目中。 | N/A |
| 保存测试计划按钮 | 将当前信息头表保存到文件中。 | N/A |
信息头管理器示例
下载此示例。在此示例中,我们创建了一个测试计划,告诉JMeter覆盖默认的“User-Agent”请求信息头,并使用特定的Internet Explorer代理字符串。(见图12和13)。
图12 - 测试计划
图13 - 信息头管理器控制面板
Java默认请求
Java默认请求组件允许您为Java测试设置默认值。请参阅Java请求。
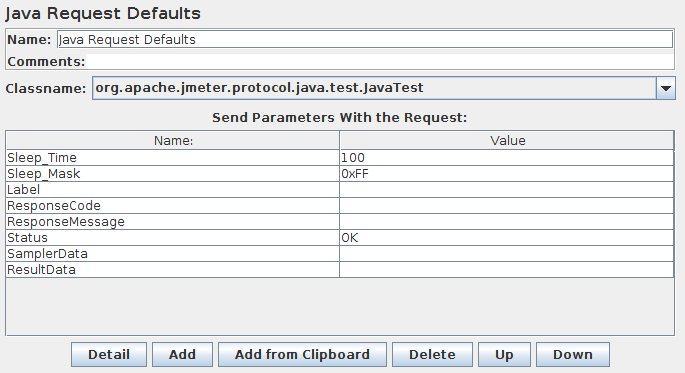
Java默认请求控制面板的截图
JDBC连接配置
从支持的JDBC连接设置创建数据库连接(提供给JDBC请求取样器使用)。可以在线程之间随意建立连接池连接,也可以让每个线程单独连接。JDBC取样器通过连接配置名称来选择适当的连接。使用的连接池是DBCP,请参阅BasicDataSource配置参数。
JDBC连接配置控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Variable Name for created pool | 连接所绑定的变量的名称。可以使用多个连接,每个连接绑定到不同的变量,允许JDBC取样器选择适当的连接。每个名称必须不同。如果有两个使用相同名称的配置元件,则只保存一个。如果检测到重复的名称,JMeter会在日志中显示。 |
是 |
| Max Number of Connections | 连接池中允许的最大连接数。在大多数情况下,将其设置为零(0)。这意味着每个线程将获得其自己的连接池,其中包含单个连接,即线程之间不共享连接。 如果你真的想使用共享池(为什么?),请将最大数量设置为与线程数相同,以确保线程不会互相等待。 |
是 |
| Max Wait (ms) | 如果在尝试检索连接的过程中超出等待时间,则线程池会抛出错误,请参阅BasicDataSource.html#getMaxWaitMillis | 是 |
| Time Between Eviction Runs (ms) | 在空闲对象逐出器线程的运行期间休眠的毫秒数。当非正数时,将不运行空闲对象逐出器线程。(默认为“60000”,1分钟)。请参阅BasicDataSource.html#getTimeBetweenEvictionRunsMillis |
是 |
| Auto Commit | 为连接打开或关闭自动提交。 | 是 |
| Transaction isolation | 事务隔离级别 | 是 |
| Init SQL statements separated by new line | 一组SQL语句,用于在首次创建物理连接时初始化它们。这些语句只执行一次 - 当配置的连接工厂创建连接时。 | 否 |
| Test While Idle | 测试连接池的空闲连接,请参阅BasicDataSource.html#getTestWhileIdle。验证查询将用于测试它。 | 是 |
| Soft Min Evictable Idle Time(ms) | 在保证minIdle连接保留在连接池的情况下,在达到空闲对象逐出器驱逐条件之前,连接可能在池中空闲的最短时间。请参阅BasicDataSource.html#getSoftMinEvictableIdleTimeMillis。默认为5000(5秒) |
是 |
| Validation Query | 用于确定数据库是否仍在响应的简单查询。这默认为jdbc驱动程序的'isValid()'方法,适用于许多数据库。但是有些可能需要不同的查询;例如像Oracle'SELECT 1 FROM DUAL'这样可以使用的。验证查询列表可以使用 jdbc.config.check.query属性来配置,默认为:
该列表来自不同数据库验证查询的stackoverflow条目,它可能不正确 注意此验证查询用于线程池创建以验证它,即使“ |
否 |
| Database URL | 数据库的JDBC连接字符串。 | 是 |
| JDBC Driver class | 驱动程序类的完全限定名称。(必须在JMeter的classpath中 - 很容易将.jar文件复制到JMeter的/lib目录中)。验证查询列表可以使用 jdbc.config.jdbc.driver.class属性来配置,默认为:
|
是 |
| Username | 要连接的用户的名称。 | 否 |
| Password | 要连接的密码。(注意在测试计划中没有加密存储) | 否 |
不同的数据库和JDBC驱动程序需要不同的JDBC设置。数据库URL和JDBC驱动类由JDBC实现的提供程序定义。
下面是一些可能的设置。请查看JDBC驱动程序文档中的确切详细信息。
如果JMeter报告No suitable driver(没有合适的驱动程序),那么这可能意味着:
- 找不到驱动程序类。在这种情况下,会有一条日志消息,例如
DataSourceElement: Could not load driver: {classname} java.lang.ClassNotFoundException: {classname} - 找到了驱动程序类,但该类不支持连接字符串。这可能是因为连接字符串中存在语法错误,或者因为使用了错误的类名。
如果数据库服务器未运行或无法访问,则JMeter将报告java.net.ConnectException。
下面给出了数据库及其参数的一些示例。
MySQL
-
Driver class
com.mysql.jdbc.Driver -
Database URL
jdbc:mysql://host[:port]/dbname
PostgreSQL
-
Driver class
org.postgresql.Driver -
Database URL
jdbc:postgresql:{dbname}
Oracle
-
Driver class
oracle.jdbc.OracleDriver -
Database URL
jdbc:oracle:thin:@//host:port/service或jdbc:oracle:thin:@(description=(address=(host={mc-name})(protocol=tcp)(port={port-no}))(connect_data=(sid={sid})))
Ingress (2006)
-
Driver class
ingres.jdbc.IngresDriver -
Database URL
jdbc:ingres://host:port/db[;attr=value]
Microsoft SQL Server (MS JDBC driver)
-
Driver class
com.microsoft.sqlserver.jdbc.SQLServerDriver -
Database URL
jdbc:sqlserver://host:port;DatabaseName=dbname
Apache Derby
-
Driver class
org.apache.derby.jdbc.ClientDriver -
Database URL
jdbc:derby://server[:port]/databaseName[;URLAttributes=value[;…]]
以上可能不正确 - 请查看相关的JDBC驱动程序文档。
密钥库配置
密钥库配置元件允许您配置密钥库的加载方式以及它将使用的密钥。此组件通常用于您不希望在响应时间中考虑密钥库初始化时间的HTTPS方案中。
要使用此元件,您需要首先使用要测试的客户端证书设置Java密钥库,以执行此操作:
-
使用Java
keytool实用程序或通过PKI创建证书 -
如果由PKI创建,请将密钥转换为JKS可接受的格式再导入Java密钥库
-
然后通过两个JVM属性引用密钥库文件(或在
system.properties中添加它们):-Djavax.net.ssl.keyStore=path_to_keystore-Djavax.net.ssl.keyStorePassword=password_of_keystore
密钥库配置控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 预加载 | 是否预加载密钥库。将其设置为true通常是最佳选择。 |
是 |
| 指向证书别名的变量名称 | 变量名称,包含用于身份验证的客户端证书的别名。以在CSV数据文件填充变量值为例。在屏幕截图中,“certificat_ssl”也是CSV数据文件的变量。默认为clientCertAliasVarName |
否 |
| 别名起始索引 | 密钥库中使用的第一个key的索引,从0开始。 | 是 |
| 别名末尾索引 | 密钥库中使用的最后一个key的索引,从0开始。使用“指向证书别名的变量名称”时,请确保它足够大,以便在启动时加载所有密钥。默认为-1表示加载全部。 |
是 |
要使JMeter使用多个证书,您需要确保:
- 在
jmeter.properties或user.properties中设置了https.use.cached.ssl.context=false- 您对HTTP请求使用HTTPClient 4实现
登录配置元件
登录配置元件允许您在使用用户名和密码作为其设置的一部分的取样器中添加或覆盖用户名和密码设置。
登录配置元件控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 用户名 | 默认要使用的用户名。 | 否 |
| 密码 | 默认要使用的密码。(注意这在测试计划中没有加密存储) | 否 |
LDAP默认请求
LDAP默认请求组件允许您为LDAP测试设置默认值。请参阅LDAP请求。
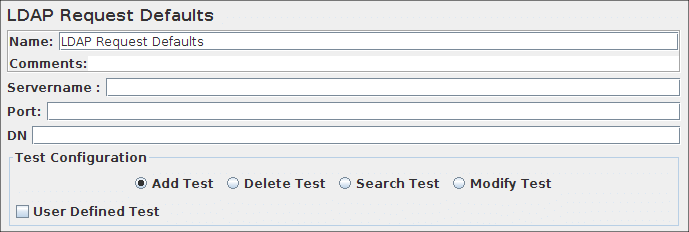
LDAP默认请求控制面板的截图
LDAP扩展请求默认值
LDAP扩展请求默认值组件允许您为LDAP扩展测试设置默认值。请参阅LDAP扩展请求。
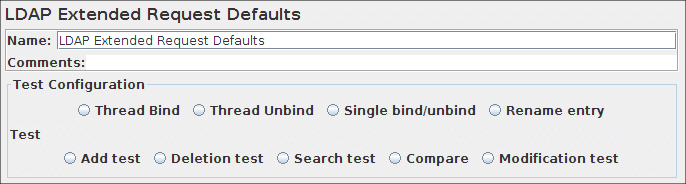
LDAP扩展请求默认值控制面板的截图
TCP取样器配置
TCP取样器配置为TCP取样器提供默认数据。
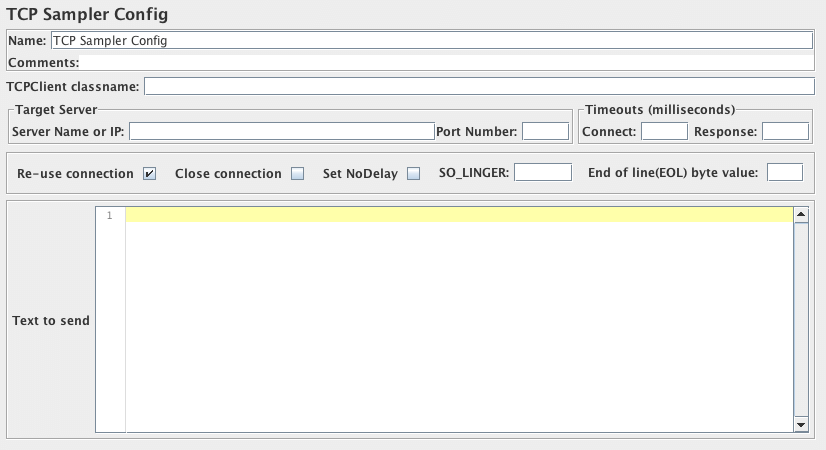
TCP取样器配置控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| TCPClient classname | TCP客户端类的名称。默认从属性tcp.handler读取,失败则从TCPClientImpl取。 |
否 |
| 服务器名称或IP | TCP服务器的名称或IP | 否 |
| 端口号 | 要使用的端口 | 否 |
| Re-use connection | 如果选中,则连接保持打开状态。否则,在读取数据后将关闭连接。 | 是 |
| 关闭连接 | 如果选择此选项,则在运行取样器后将关闭连接。 | 是 |
| SO_LINGER | 创建套接字时启用/禁用指定的延迟时间(以秒为单位)SO_LINGER。如果将“SO_LINGER”值设置为0,则可以防止大量套接字处于TIME_WAIT状态。 |
否 |
| 行尾(EOL)字节值 | 行尾的字节值,将其设置为-128到+127范围之外的值以跳过EOL检查。您可以在jmeter.properties文件中设置,也可以设置tcp.eolByte属性。如果在TCP取样器配置和jmeter.properties文件中同时设置此项,将使用TCP取样器配置中的设置值。 |
否 |
| 连接超时 | 连接超时时间(毫秒,0为禁用)。 | 否 |
| 响应超时 | 响应超时时间(毫秒,0为禁用)。 | 否 |
| 设置无延迟 | 是否设置无延迟属性? | 否 |
| 要发送的文本 | 要发送的文本 | 否 |
用户定义的变量
用户定义的变量元件允许您定义一组初始变量,就像在测试计划中一样。
注意,测试计划中的所有用户定义的变量元件 - 无论它们在何处 - 都会在开始时进行处理。
因此,您无法引用定义为测试运行一部分的变量,例如在后置处理器中。
用户定义的变量不应与每次调用时生成不同结果的函数一起使用。只有第一个函数调用的结果才会保存在变量中。但是,用户定义的变量可以与__P()等函数一起使用,例如:
HOST ${__P(host,localhost)}
这将定义变量“HOST”并赋JMeter属性“host” 的值,如果未定义则默认为“localhost”。
要在测试运行期间定义变量,请参阅用户参数。用户定义的变量按照它们在计划中出现的顺序从上到下进行处理。
为简单起见,建议将用户定义的变量仅放置在线程组的开头(或者在测试计划本身下)。
一旦处理了测试计划和所有用户定义的变量,就会将生成的变量集复制到每个线程以提供初始变量集。
如果运行时元件(例如用户参数前置处理器或正则表达式提取器)定义了与其中一个用户定义的变量同名的变量,那么这将替换初始值,并且线程中的所有其他测试元件将看到更新的值。
用户定义的变量控制面板的截图
如果您有多个线程组,请确保为不同的值使用不同的名称,因为户定义的变量在线程组之间共享。此外,在元件被处理之后变量才可用,因此您无法引用在同一元件中定义的变量。您可以引用之前用户定义的变量或测试计划中定义的变量。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 用户定义的变量 | 变量名称/值对。“名称”列下的字符串是您需要放在${...}构造中的括号内以便稍后使用变量的内容。然后,整个${...}将被“值”列中的字符串替换。 |
否 |
随机变量
随机变量配置元件用于生成随机数字符串并将它们存储在变量中以供以后使用。它比使用用户定义的变量和__Random()函数更简单。
使用随机数生成器构造输出变量,然后使用格式字符串格式化结果数字。数字的计算使用公式minimum+Random.nextInt(maximum-minimum+1)。Random.nextInt()需要一个正整数。这意味着最大值-最小值 - 即范围 - 必须小于2147483647,但是只要在范围内,最小值和最大值可以是任何long值。
由于在每次迭代开始时评估随机值,因此使用属性以外的变量作为最小值或最大值的值可能不是一个好主意。在第一次迭代时它将为零。
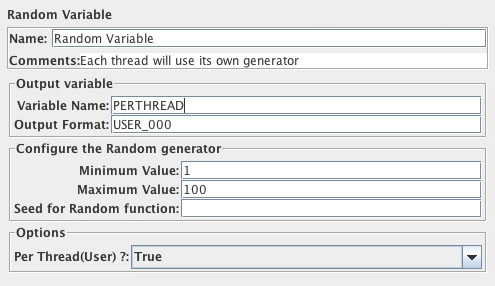
随机变量控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 变量名称 | 用于存储随机字符串的变量的名称 | 是 |
| 输出格式 | 要使用的java.text.DecimalFormat格式字符串。例如,“000”将生成至少3位数的数字,或“USER_000”将生成USER_nnn形式的输出。如果未指定,则默认使用Long.toString()生成数字 |
否 |
| 最小值 | 生成的随机数的最小值(long)。 |
是 |
| 最大值 | 生成的随机数的最大值(long)。 |
是 |
| 随机种子 | 随机数生成器的种子。如果将每线程设置为true使用相同的种子值,则每个线程将获得与每个Random类相同的值。如果未设置种子,则将使用Random的默认构造函数。 |
否 |
| 每线程(用户)? | 如果为False,则生成器在线程组中的所有线程之间共享。如果为True,则每个线程都有自己的随机生成器。 |
是 |
计数器
允许用户创建可在线程组中的任何位置引用的计数器。计数器配置允许用户配置起始值,最大值和递增值。计数器将从起始循环到最大,然后从起始重新开始,继续这样直到测试结束。
计数器使用long类型来存储值,因此范围从-2^63到2^63-1。
计数器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Starting value | 计数器的起始值。计数器将在第一次迭代期间等于此值(默认为0)。 | 否 |
| 递增 | 每次迭代后计数器的增加量(默认为0,表示没有增量)。 | 是 |
| Maximum value | 如果计数器超过最大值,则将其重置为Starting value。默认值为Long.MAX_VALUE |
否 |
| 数字格式 | 可选的格式,如000将格式化为001,002这样的。它将传递给DecimalFormat,所以可以使用任何有效的格式。如果解释格式时出现问题,则忽略该格式。【使用Long.toString()生成默认格式】 |
否 |
| 引用名称 | 这是计数器值可用的变量名称。如果将其命名为counterA,则可以使用${counterA}访问它, 如用户定义的值中所述(默认情况下,它创建一个可以使用${}访问的空字符串变量,但强烈建议不要这样做) |
否 |
| 与每用户独立的跟踪计数器 | 换句话说,这是一个全局计数器,还是每个用户都使用自己的计数器?如果未选中,则计数器是全局的(即,用户#1将获得值“1”,并且用户#2将在第一次迭代时获得值“2”)。如果选中,则每个用户都有一个独立的计数器 |
否 |
| 在每个线程组迭代上重置计数器 | 此选项仅在每个用户跟踪计数器选中时可用,如果选中,则计数器将在每个线程组迭代时重置为“起始”值。当计数器在循环控制器中时,这可能很有用。 |
否 |
简单配置元件
简单配置元件允许您在取样器中添加或覆盖任意值。您可以选择值的名称和值本身。虽然一些有冒险精神的用户可能会发现这个元件的用途,但它主要是供开发人员在开发新的JMeter组件时使用的基本GUI。
简单配置元件控件面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 是 |
| 参数名称 | 每个参数的名称。这些值是JMeter工作的内部值,通常不会记录。只有熟悉代码的人才会知道这些值。 | 是 |
| 参数值 | 要应用于该参数的值。 | 是 |
MongoDB源配置(已弃用)
18.5 断言
断言用于对取样器执行附加检查,并在同一范围内的每个取样器之后进行处理。要确保仅将断言应用于特定取样器,请将其添加为取样器的子级。
注意:除非另有说明,否则断言不适用于子样本 - 仅适用于父样本。对于JSR223和BeanShell断言,脚本可以使用
prev.getSubResults()方法检索子样本,该方法返回取样结果数组。如果没有结果,则数组将为空。
断言可以应用于主样本,子样本或两者。默认设置是仅将断言应用于主样本。如果断言支持此选项,则GUI上将显示如下所示的条目:

断言范围
或如下

断言范围
如果子取样器失败且主样本成功,则主样本将设置为失败状态,并将添加断言结果。如果使用JMeter变量选项,则假定它与主样本相关,并且任何失败将仅应用于主样本。
在运行了取样器的所有断言之后,变量
JMeterThread.last_sample_ok将更新为“true”或“false”。
响应断言
响应断言控制面板允许您添加模式字符串来和请求或响应的各个字段进行比较。模式字符串是:
包括,匹配:Perl5风格的正则表达式相等,字符串:纯文本,区分大小写
模式匹配字符的摘要可以参阅ORO Perl5正则表达式。
您还可以选择是否期望字符串与整个响应匹配,或者是否仅期望响应包括该模式。您可以将多个断言附加到任何控制器,以获得额外的灵活性。
注意模式字符串不应包含封闭分隔符,即使用Price: \d+而不是/Price: \d+/。
默认情况下,模式处于多行模式,这意味着“.”元字符与换行符不匹配。在多行模式下,“^”和“$”匹配字符串中任何位置的任何行的开头或结尾 - 而不仅仅是整个字符串的开头和结尾。请注意\s确实匹配换行符。不忽略大小写。要覆盖这些设置,可以使用扩展的正则表达式语法。例如:
-
(?i)忽略大小写
-
(?s)将目标视为单行,即“
.”匹配新行 -
(?is)以上都是
这些可以在表达式中的任何位置使用,并在被覆盖之前保持有效。例如
-
(?i)apple(?-i) Pie匹配“
ApPLe Pie”,但不匹配“ApPLe pIe” -
(?s)Apple.+?Pie匹配
Apple,然后是Pie,后者可能会在后续行中。 -
Apple(?s).+?Pie与上面相同,但在开始时使用
(?s)可能更清楚。
响应断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
|
是 |
| 测试字段 | 指示JMeter测试请求或响应的哪个字段。
|
是 |
| 忽略状态 | 指示JMeter将状态初始化为成功。 通过将断言的结果与现有的响应状态相结合来确定样本的总体成功。当 忽略状态复选框选中后,在评估断言之前,将强制响应状态为成功。在 4xx和5xx范围内状态的HTTP响应通常被视为不成功。在执行进一步检查之前,“忽略状态”复选框可用于设置状态成功。请注意,这将清除任何先前的断言失败,因此请确保仅在第一个断言上设置此操作。 |
是 |
| 模式匹配规则 | 指示如何根据模式检查正在测试的文本。
相等和Substring模式是纯字符串,而不是正则表达式。也可以选择NOT来反转检查结果。或者在OR组合中应用每个断言(如果1个模式测试中能够匹配,断言就通过)而不是AND(所有模式必须匹配,断言才能通过)。 |
是 |
| 要测试的模式 | 要测试的模式列表。每个模式都单独测试。如果一个模式失败,则后续的模式不再检查。使用多个模式设置一个断言和使用一个模式设置多个断言之间没有区别(假设其他选项相同)。但是,当选中“ |
是 |
| 自定义失败消息 | 允许您定义将替换生成的失败消息 | 否 |
该模式是Perl5样式的正则表达式,但没有括号。
断言实例
图14 - 测试计划
图15 - 带模式的断言控制面板
图16 - 断言监听器结果(通过)
图17 - 断言监听器结果(失败)
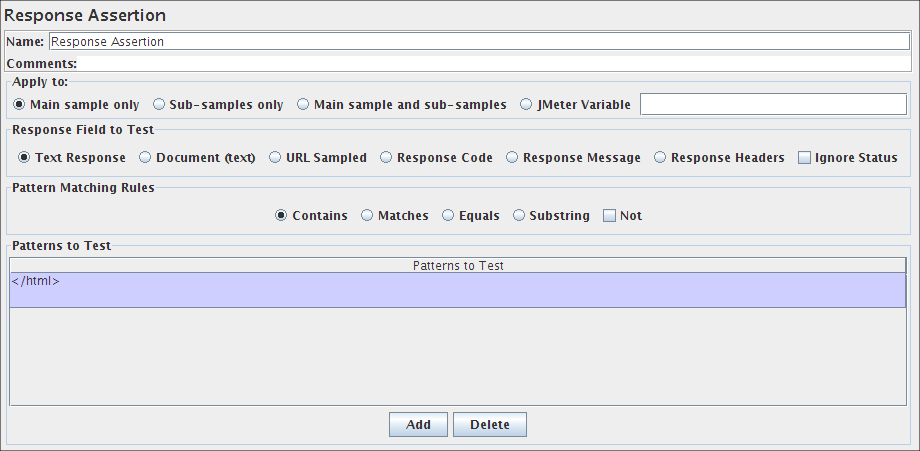
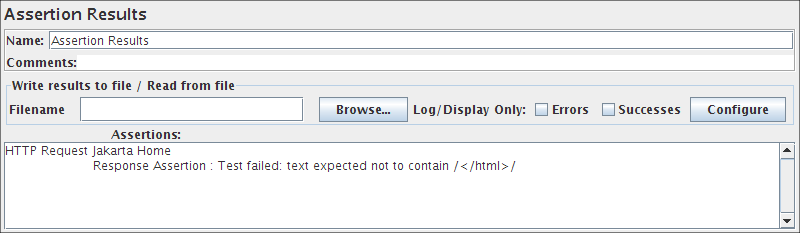
断言持续时间
断言持续时间测试在给定的时间内收到每个响应。任何花费超过给定毫秒数(由用户指定)的响应都会标记为失败的响应。
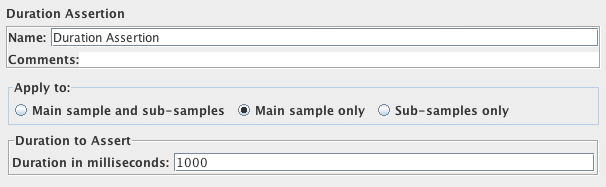
断言持续时间控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 持续时间(毫秒) | 在标记为失败之前允许的每个响应的最大毫秒数。 | 是 |
大小断言
大小断言测试每个响应中包含正确的字节数。您可以指定大小等于,大于,小于或不等于给定的字节数。
空响应被视为0字节而不是报告为错误。
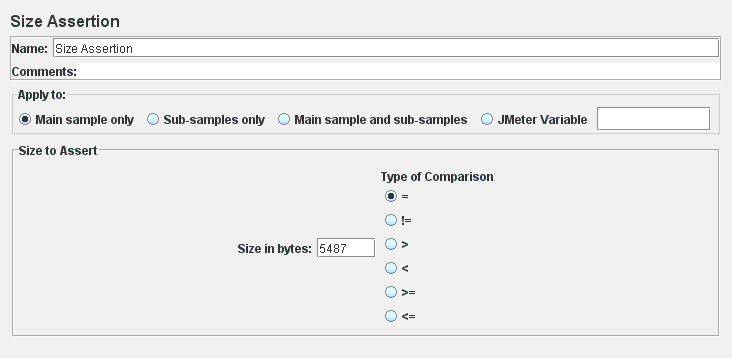
大小断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
|
是 |
| 字节大小 | 用于测试响应大小(或JMeter变量值)的字节数。 | 是 |
| 比较类型 | 是否测试响应是否等于,大于,小于或不等于指定的字节数。 | 是 |
XML断言
XML断言测试响应数据由正式的XML文档组成。它不会基于DTD或模式来验证XML,也不会进行任何进一步的验证。

XML断言控件面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
BeanShell断言
BeanShell断言允许用户使用BeanShell脚本执行断言检查。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223 Sampler+Groovy以提高性能,支持新的Java功能并限制BeanShell库的维护。
请注意,在测试脚本的每个线程中,每个独立出现的断言都使用不同的解释器,但是相同的解释器用于后续调用。这意味着变量会在对断言的调用中持续存在。
所有断言都是从与取样器相同的线程调用的。
如果定义了属性“beanshell.assertion.init”,则将其作为源文件的名称传递给解释器。这可以用于定义常用方法和变量。bin目录中有一个示例init文件:BeanShellAssertion.bshrc。
测试元件支持ThreadListener和TestListener方法。这些应该在初始化文件中定义。有关示例定义,请参阅文件BeanShellListeners.bshrc。
BeanShell断言控件面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。该名称存储在脚本变量Label中 | 否 |
| 每次调用前重置bsh.Interpreter | 如果选择此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。这会覆盖脚本。文件名存储在脚本变量FileName中 |
否 |
| 脚本 | 要运行的BeanShell脚本。忽略返回值。 | 是(除非提供脚本文件) |
您可以尝试一个示例脚本。
在调用脚本之前,在BeanShell解释器中设置了一些变量。这些没有另外说明,都是字符串:
-
log- 记录器对象。(例如)log.warn("Message"[,Throwable]) -
SampleResult,prev- SampleResult对象; 可读-可写 -
Response- 响应对象; 可读-可写 -
Failure- 布尔值; 可读-可写; 用于设置断言状态 -
FailureMessage- 字符串; 可读-可写; 用于设置断言消息 -
ResponseData- 响应消息体(byte[]) -
ResponseCode- 例如200 -
ResponseMessage- 例如OK -
ResponseHeaders- 包含HTTP信息头 -
RequestHeaders- 包含发送到服务器的HTTP信息头 -
SampleLabel -
SamplerData- 发送到服务器的数据 -
ctx- JMeterContext -
vars- JMeterVariables - 例如vars.get("VAR1"); vars.put("VAR2","value"); vars.putObject("OBJ1",new Object());
-
props- JMeterProperties(java.util.Properties类) - 例如props.get("START.HMS"); props.put("PROP1","1234");
响应对象的下列方法可能很有用:
setStopThread(boolean)setStopTest(boolean)String getSampleLabel()setSampleLabel(String)
MD5Hex断言
MD5Hex断言允许用户检查响应数据的MD5哈希值。
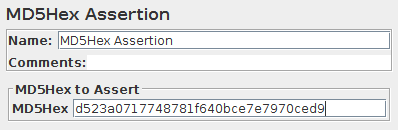
MD5Hex断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| MD5Hex | 表示MD5哈希的32位十六进制数字(不区分大小写) | 是 |
HTML断言
HTML断言允许用户使用JTidy检查响应数据的HTML语法。
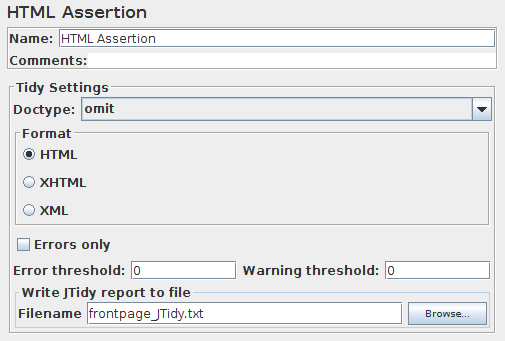
HTML断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| doctype | omit,auto,strict或oose |
是 |
| Format | HTML,XHTML或XML |
是 |
| Errors only | 只记录错误? | 是 |
| Error threshold | 在将响应归类为失败之前允许的错误数 | 是 |
| Warning threshold | 在将响应归类为失败之前允许的警告数 | 是 |
| 文件名 | 写入报告的文件的名称 | 否 |
XPath断言
XPath断言测试文档的格式是否良好,可以选择验证DTD,或者通过JTidy转换文档并测试XPath。如果该XPath存在,则断言为真。使用“/”将匹配任何格式良好的文档,并且是默认的XPath表达式。断言还支持布尔表达式,例如“count(//*error)=2”。有关XPath的更多信息,请参见http://www.w3.org/TR/xpath。
一些示例表达式:
//title[text()='Text to match']- 匹配响应中任何位置的<title>Text to match</title>/title[text()='Text to match']- 匹配响应的根节点的<title>Text to match</title>
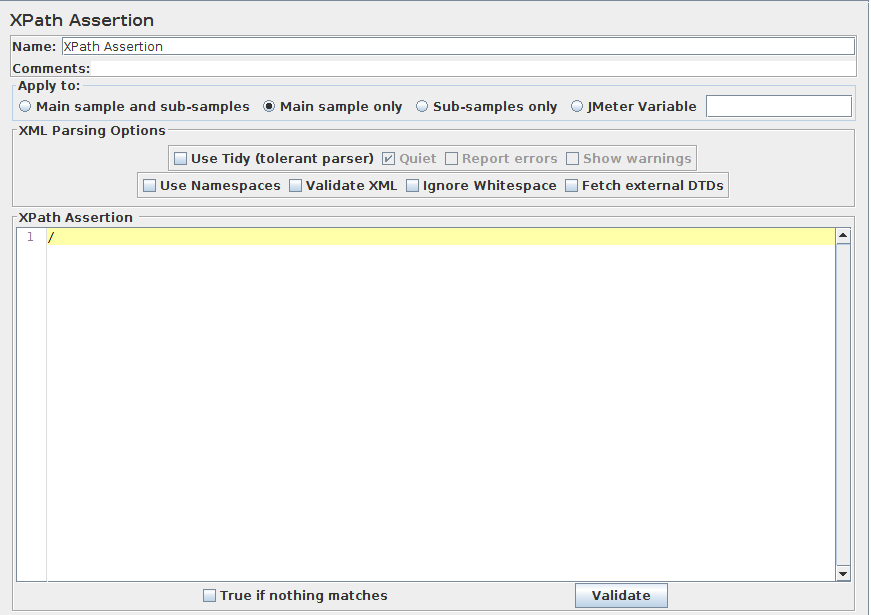
XPath断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Use Tidy (tolerant parser) | 使用Tidy,即容忍XML/HTML错误 | 是 |
| Quiet | 设置Tidy Quiet标志 | 如果选择了Tidy |
| Report Errors | 如果发生Tidy错误,则相应地设置断言 | 如果选择了Tidy |
| Show warnings | 设置Tidy显示警告选项 | 如果选择了Tidy |
| Use Namespaces | 命名空间应该被尊重吗?(见下面关于命名空间的说明) | 如果未选择Tidy |
| Validate XML | 根据其架构检查文档。 | 如果未选择Tidy |
| Ignore Whitespace | 忽略元件中空格。 | 如果未选择Tidy |
| Fetch External DTDs | 如果选中,则获取外部DTD。 | 如果未选择Tidy |
| XPath Assertion | 要在文档中匹配的XPath。 | 是 |
| True if nothing matches | 如果XPath表达式不匹配,则为True | 否 |
非容忍解析器可能非常慢,因为它可能需要下载DTD等。
命名空间
作为Xalan XPath解析器(JMeter所基于的实现)限制的命名空间的工作轮,您需要:
提供一个属性文件(例如,如果您的文件名为namespaces.properties),其中包含名称空间前缀的映射:
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …使用如下属性在
user.properties文件中引用此文件:xpath.namespace.config=namespaces.properties
XML Schema断言
XML Schema断言允许用户验证针对XML Schema的响应。
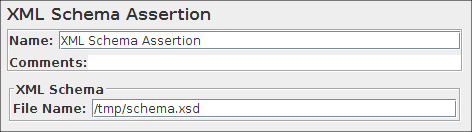
XML Schema断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 文件名 | 指定XML Schema的文件名 | 是 |
JSR223断言
JSR223断言允许使用JSR223脚本代码来检查上一个样本的状态。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 语言 | 要使用的JSR223语言。 | 是 |
| 参数 | 要传递给脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的脚本的文件,如果使用相对文件路径,则它将相对于系统属性“user.dir” 所引用的目录 |
否 |
| 缓存编译脚本(如果可用) | 测试计划中的唯一字符串,如果使用的语言支持Compilable接口(Groovy是其中之一,java,BeanShell和JavaScript不是),则JMeter将用于缓存脚本编译的结果如果您在不检查此选项的情况下使用Groovy,请参阅JSR223取样器Java系统属性中的注释 |
否 |
| 脚本 | 要运行的脚本。 | 是(除非提供脚本文件) |
设置以下变量供脚本使用:
-
log- (Logger) - 可用于写入日志文件 -
Label- 字符串标签 -
Filename- 脚本文件名(如果有) -
Parameters- 参数(作为字符串) -
args- 作为String数组的参数(在空格上拆分) -
ctx- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object()); vars.getObject("OBJ2");
-
props- (JMeterProperties - java.util.Properties类) - 例如props.get("START.HMS"); props.put("PROP1","1234");
-
SampleResult,prev- (SampleResult) - 提供对前一个取样器结果的访问(如果有的话) -
sampler- (Sampler) - 提供对当前取样器的访问 -
OUT-System.out- 例如OUT.println("message") -
AssertionResult- (AssertionResult) - 断言结果
该脚本可以检查SampleResult的各个方面。如果检测到错误,脚本应使用AssertionResult.setFailureMessage("message")和AssertionResult.setFailure(true)。
有关上述每个变量的所有可用方法的更多详细信息,请查看Javadoc。
比较断言
在压力测试期间不得使用比较断言,因为它会消耗大量资源(内存和CPU)。仅用于功能测试或测试计划调试和验证期间。
比较断言可用于比较其范围内的样本结果。可以比较内容或经过的时间,并且可以在比较之前过滤内容。断言比较结果可以在比较断言可视化器中看到。
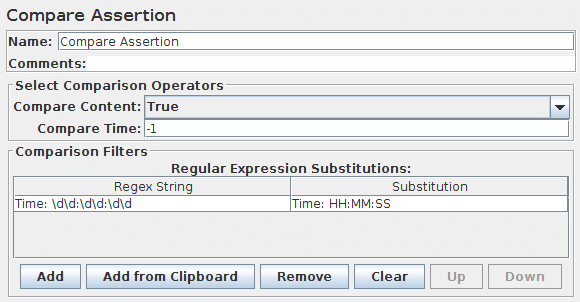
比较断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 比较的内容 | 是否比较内容(响应数据) | 是 |
| 比较的时间 | 如果该值≥0,则检查响应时间差是否不大于该值。即如果值为0,则响应时间必须完全相等。 |
是 |
| 比较过滤器 | 过滤器可用于从内容比较中删除字符串。例如,如果页面有时间戳,并且与以下内容匹配:“Time: \d\d:\d\d:\d\d”,它可以被替换为虚拟固定时间“Time: HH:MM:SS“。 |
否 |
SMIME断言
SMIME断言可用于评估邮件阅读者取样器的样本结果。此断言验证mime消息的正文是否已签名。还可以针对特定签署者证书来验证签名。由于这是大多数用户不一定需要的功能,因此需要下载额外的jar并将其添加到JMETER_HOME/lib:
bcmail-xxx.jar(BouncyCastle SMIME/CMS)bcprov-xxx.jar(BouncyCastle Provider)
这些需要从BouncyCastle下载。
如果使用邮件阅读者取样器,请确保选择“Store the message using MIME (raw)”,否则断言将无法正确处理消息。
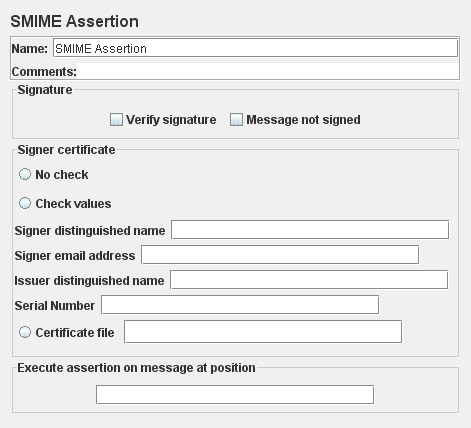
SMIME断言控制面板的屏幕截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Verify Signature | 如果选中,则断言将根据“Signer Certificate”框中定义的参数验证它是否是有效签名。 |
是 |
| Message not signed | 是否期望在消息中签名 | 是 |
| Signer Certificate | “No Check”表示它不会执行签名验证。“Check values”用于根据提供的输入验证签名。并且“Certificate file”将针对特定证书文件执行验证。 |
是 |
| Message Position | Mail取样器可以在单个样本中检索多条消息。使用此字段指定要检查的邮件。消息从0开始编号,因此0表示第一条消息。负数从最后的消息开始计算; -1表示最后,-2表示倒数第二个等。 |
是 |
JSON断言
此组件允许您执行JSON文档的验证。首先,如果数据不是JSON格式,它将解析失败。其次,它将使用Jayway JsonPath 1.2.0的语法搜索指定的路径。如果找不到路径,则会失败。第三,如果在文档中找到JSON路径,并且请求了对期望值的验证,则它将执行验证。对于null值,GUI中有特殊复选框。注意,如果路径返回数组对象,则对其进行迭代;如果找到预期值,则断言将成功。验证空数组使用字符串[]。此外,如果patch返回字典对象,它将在比较之前转换为字符串。
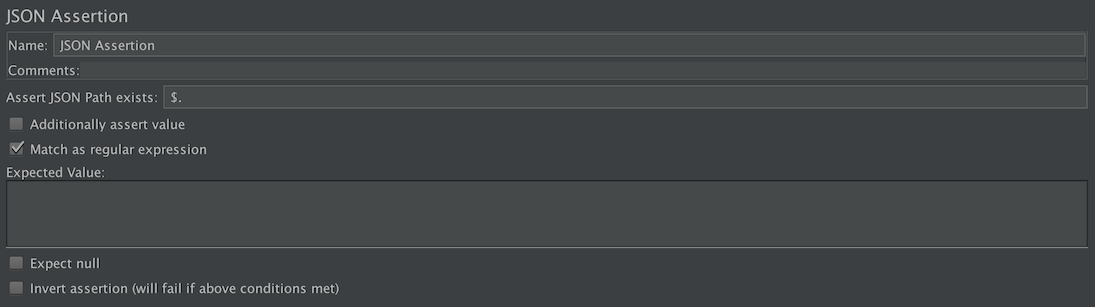
JSON断言控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Assert JSON Path exists | JSON元件路径的断言。 | 是 |
| Additionally assert value | 如果要使断言具有某个值,请选中复选框 | 否 |
| Match as regular expression | 如果要使用正则表达式,请选中复选框 | 否 |
| Expected Value | 匹配的断言或正则表达式的值 | 否 |
| Expect null | 如果希望null,请选中复选框 | 否 |
| Invert assertion (will fail if above conditions met) | 反转断言(如果符合上述条件,将失败) | 否 |
18.6 定时器
从3.1版本开始,一个新的特性(Beta模式下,从JMeter3.1开始后续可能会有变更)已经被实现,它提供下列特性。
您可以通过设置属性
timer.factor=float number来对随机定时器计算的睡眠延迟应用乘法因子,其中float number是十进制正数。JMeter会将此因子乘以计算的睡眠延迟。此功能可用于:
注意,定时器在它们的范围内的所有取样器之前被处理;如果在同一范围内有多个定时器,则在所有取样器之前处理所有定时器。
定时器仅与取样器一起处理。与取样器不在同一范围内的定时器不会被处理。
要将定时器应用于单个取样器,请将定时器添加为取样器的子元件。定时器将在执行取样器之前应用。要在取样器之后应用计时器,请将其添加到下一个取样器,或将其添加为测试活动取样器的子级。
固定定时器
如果要让每个线程在请求之间暂停相同的时间,请使用此定时器。
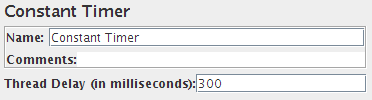
固定定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此定时器的描述性名称。 | 否 |
| 线程延迟 | 暂停的毫秒数。 | 是 |
高斯随机定时器
该定时器暂停每个线程请求一段随机时间,大部分时间间隔发生在特定值附近。总延迟是高斯分布值(平均值为0.0,标准差为1.0)乘以指定偏差值,再加上偏移值之和。另一种解释是,在高斯随机定时器中,固定偏移周围的变化具有高斯曲线分布。
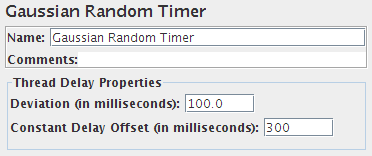
高斯随机定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 偏差 | 偏差,以毫秒为单位。 | 是 |
| 固定延迟偏移 | 除随机延迟之外暂停的毫秒数。 | 是 |
统一随机定时器
该定时器暂停每个线程请求一段随机时间,每个时间间隔具有相同的发生概率。总延迟是随机值和偏移值之和。
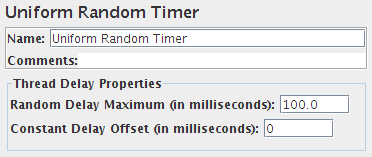
统一随机定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Random Delay Maximum | 暂停的最大随机毫秒数。 | 是 |
| Constant Delay Offset | 除随机延迟之外暂停的毫秒数。 | 是 |
常数吞吐量定时器
该定时器引入可变暂停,计算以使总吞吐量(以每分钟样本数计)尽可能接近给定数字。当然,如果服务器无法处理它,或者如果其他定时器或耗时的测试元件阻止它,吞吐量将会降低。
注意虽然定时器被称为常数吞吐量定时器,但吞吐量值不需要是常量。它可以根据变量或函数调用来定义,并且可以在测试期间更改该值。可以通过各种方式更改值:
- 使用计数器变量
- 使用
__jexl3,__ groovy函数来提供更改值 - 使用远程BeanShell服务器更改JMeter属性
有关详细信息,请参阅最佳实践。
注意在测试期间不应经常更改吞吐量值 - 新值需要一段时间才能生效。
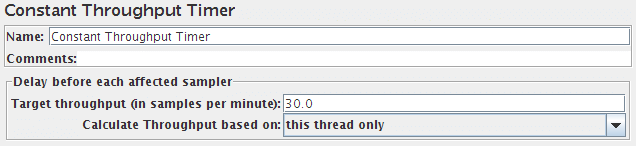
常数吞吐量定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 目标吞吐量 | 我们希望定时器尝试生成的吞吐量。 | 是 |
| 基于计算吞吐量 |
|
是 |
共享和非共享算法都旨在生成所需的吞吐量,并将产生类似的结果。 共享算法应该生成更准确的总体事务率。 非共享算法应该跨线程生成更均匀的事务传播。
准确的吞吐量定时器
该定时器引入可变暂停,计算以保持总吞吐量(例如,以每分钟样本计)尽可能接近给定数字。当然,如果服务器无法处理它,或者其他定时器影响,或者没有足够的线程,或者耗时的测试元件阻止它,吞吐量都会降低。
虽然定时器被称为准确的吞吐量定时器,但它的目的并不是在测试期间以每秒的间隔产生相同数量精确的样本。
定时器最适合工作在36000请求/小时以下的频率,但您的总请求可能会有所不同(如果您的目标差别很大,请参阅下面的监控部分)。
测试计划中准确的吞吐量定时器的最佳位置
您可能知道,定时器是被所有兄弟姐妹及其子元件继承的。这就是为什么准确的吞吐量定时器的最佳位置之一是在测试循环中的第一个元件之下。例如,您可以在开头添加一个虚拟取样器,并将定时器放在该虚拟取样器下。
生成调度
准确的吞吐量定时器模拟泊松到达调度。该调度通常发生在现实生活中,因此将其用于压力测试是有意义的。例如,它自然可能生成靠近的样本,因此能够会揭示并发问题。即使您设法使用泊松随机定时器生成泊松到达,它也会受到下面列出的问题的影响。例如,真正的泊松到达可能会无限期地暂停,这对于压力测试是不实际的。例如,速率为每秒1个的“常规”泊松到达可能在60秒长测试中结束50个样本。
常数吞吐量定时器收敛到指定的速率,但它倾向于以均匀的间隔产生采样。
加速和启动峰值
您可以使用“加速”或类似方法来避免测试开始时出现尖峰。例如,如果将线程组配置为具有100个线程,并将Ramp-up时间设置为0(或者设置为较小的数字),那么所有线程将同时启动,并且会产生不必要的负载峰值。最重要的是,如果将Ramp-up时间设置得太高,可能会导致“太少”线程在一开始可用,达不到所需的负载。
准确的吞吐量定时器以随机方式调度执行,因此可用于生成恒定负载,建议将Ramp-up时间和延迟设置为0。
多个线程组同时启动
当测试计划包含多个线程组时,可能会出现Ramp-up问题的变体。为了缓解该问题,通常会向每个线程组添加“随机”延迟,以便线程在不同时间启动。
准确的吞吐量定时器避免了这个问题,因为它以随机方式安排执行。您无需添加额外的随机延迟来缓解启动峰值。
每小时的迭代次数
其中一个基本要求是每M分钟发出N个样本。让它每小时执行60次迭代。如果您使用57次执行(仅因为次数是随机的)报告负载测试结果,会使业务客户无法理解。为了每小时生成60次迭代,您需要配置如下(其他参数可以保留其默认值)
目标吞吐量(样本):60吞吐量周期(秒):3600测试持续时间(秒):3600
前两个选项设置吞吐量。尽管60/3600,30/1800和120/7200表示完全相同的负载水平,但请选择能够更好地表示业务需求的负载水平。例如,如果要求测试“每小时60个样本”,则设置60/3600。如果要求测试“每分钟1个样本”,则设置1/60。
测试持续时间(秒)确保定时器在给定测试持续时间执行确切样本数。准确的吞吐量定时器在测试启动时为样本创建调度。例如,如果您希望以每小时60个吞吐量执行5分钟测试,则可以将测试持续时间(秒)设置为300。这样可以以业务友好的方式配置吞吐量。注:测试持续时间(秒)并没有限制测试时间。这只是定时器的一个提示。
线程数和思考时间
其中一个常见的误区是调整线程数和思考时间,以便最终获得所需的吞吐量。即使它可能有效,但这种方法会导致在测试运行上花费大量时间。当测试新的应用程序版本时,可能需要再次调整线程和延迟。
准确的吞吐量定时器可以设置吞吐量目标,无论应用程序执行得多好,都可以使用它。为了做到这一点,准确的吞吐量定时器在测试启动时创建一个调度,然后它使用该调度来释放线程。思考时间和线程数的主要驱动因素应该是业务需求,而不是以某种方式匹配吞吐量的愿望。
例如,如果您的应用程序由呼叫中心的支持工程师使用。假设呼叫中心有2名工程师,目标吞吐量为每分钟1。假设工程师需要4分钟才能阅读和查看网页。在这种情况下,您应该在组中设置2个线程,使用4分钟进行思考时间延迟,并在准确的吞吐量定时器指定每分钟1个。当然,它会生成大约2个样本/4分钟=每分钟0.5个这样的结果,这样的测试结果意味着“您需要更多支持工程师在呼叫中心”或“您需要减少工程师完成任务所需的时间”。
测试低速率和可重复测试
低速率测试(例如每小时60次)需要知道所需的测试配置。例如,如果您需要以均匀间隔(例如介于60秒之间)注入负载,那么您最好使用常数吞吐量定时器。但是,如果您需要随机调度(例如,为执行报告的真实用户建模),那么准确的吞吐量定时器就是您的朋友。
在比较多个压力测试的结果时,能够重复完全相同的测试配置文件非常有用。例如,如果在测试开始5分钟后调用操作X(例如“利润报告”),那么为后续测试执行复制该模式会很好。复制相同的负载模式简化了测试结果的分析(例如CPU%图表)。
随机种子(从0变为随机)可以控制准确的吞吐量定时器使用的种子值。默认情况下,它初始化为0,这意味着使用随机种子用于每次测试执行。如果您需要具有可重复的加载模式,则将随机种子更改为 一些随机值。一般建议是使用非零种子,“0默认情况下”是实现限制。
注意:当使用具有相同吞吐率和相同非零种子的多个线程组时,可能会导致不必要的同时触发样本。
测试高速率和/或长持续时间测试
当样本数量很大(例如,它超过10,000)时,由于准确的吞吐量定时器试图产生确切数量的样本,因此调度生成可能需要花费显著的时间(例如,数秒)。还有内存消耗,但是它应该不太重要,因为调度中的每个项目只消耗8个字节。为了减少调度生成开销,准确的吞吐量定时器在生成长调度时允许一些松弛。它由生成延迟的准确性属性控制 。默认情况下,当样本数超过10,000时,允许不精确的调度。
如果您想以每小时5'000的速度进行为期2周的测试,则无需为该2周创建调度。您可以将计时器的测试持续时间(秒)属性设置为1小时。计时器将创建一个小时的5'000个样本的调度,并且当调度用尽时,计时器将生成下一个小时的调度。
突发负载
可能存在所有样本成对,成三等出现的的情况。某些情况可能通过同步定时器来解决,但准确的吞吐量定时器具有本地方式来以包的形式发出请求。默认情况下禁用此行为,并使用“批处理离开”设置进行控制
批处理中的线程数(线程)。指定批次中的样本数。注意样本的总数仍将与目标吞吐量一致批处理中的线程之间的延迟(ms)。例如,如果设置为42,批量大小为3,则线程将在x,x + 42ms,x + 84ms处离开
可变负载率
尽管可以通过表达式定义属性值(例如吞吐量),但建议通过测试使值或多或少保持相同,因为重新计算新计划以适应新值需要时间。
监控
当生成下一个调度时,准确的吞吐量定时器将消息记录到jmeter.log:2018-01-04 17:34:03,635 INFO o.a.j.t.ConstantPoissonProcessGenerator: Generated 21 timings (... 20 required, rate 1.0, duration 20, exact lim 20000, i21) in 0 ms, restart was issued 3 times. First 15 events will be fired at: 1.1869653574244292 (+1.1869653574244292), 1.4691340403043207 (+0.2821686828798915), 3.638151706179226 (+2.169017665874905), 3.836357090410566 (+0.19820538423134026), 4.709330071408575 (+0.8729729809980085), 5.61330076999953 (+0.903970698590955), ...
这表明调度生成花了0毫秒,它显示了以秒为单位的绝对时间戳。在上面的情况中,速率设置为每秒1,实际时间戳变为1.2秒,1.5秒,3.6秒,3.8秒,4.7秒,依此类推。
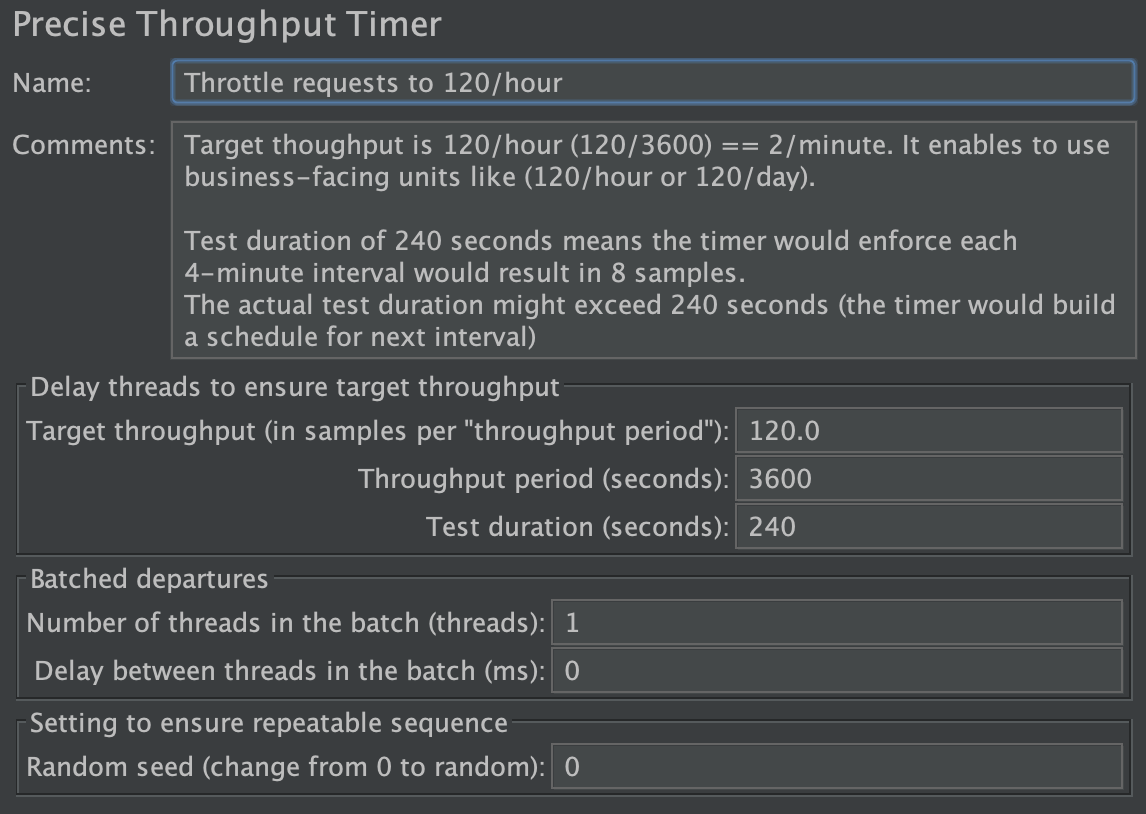
准确的吞吐量定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 目标吞吐量(每个“吞吐期”的样本) | 每个“吞吐量周期”要获得的最大样本数,包括所有受影响的取样器中的组中的所有线程。 | 是 |
| 吞吐量周期(秒) | 吞吐量周期。例如,如果“吞吐量”设置为42并且“吞吐量周期”设置为21秒,那么您将获得每秒2个样本。 | 是 |
| 测试持续时间(秒) | 这用于确保您在“测试持续时间”时间范围内获得吞吐量*持续时间样本数。 | 是 |
| 批处理中的线程数(线程) | 如果该值超过1,则多个线程同时离开定时器。平均吞吐量仍然符合“吞吐量”值。 | 是 |
| 批处理中的线程之间的延迟(ms) | 例如,如果设置为42,批量大小为3,则线程将在x,x + 42ms,x + 84ms处离开。 | 是 |
| 当序列长度超过(样本)时使用近似吞吐量 | 当所需的样本数小于此限制时,定时器将生成确切数量的样本。 | 是 |
| 允许吞吐量过剩(百分比) | 当需要超过“最大精确样本”样本时,定时器可能会生成比吞吐量指定的事件稍多的事件。 | 是 |
| 随机种子(从0变为随机) | 注意:不同的定时器最好使用不同的种子值。常量种子确保计时器在每次测试开始时产生相同的延迟。值“0”表示计时器是真正随机的(从一次执行到另一次执行不可重复)。 | 是 |
同步定时器
同步定时器的目的是阻塞线程,直到X个线程被阻塞,然后它们全部被同时释放。因此,同步定时器可以在测试计划的各个点创建大的即时负载。
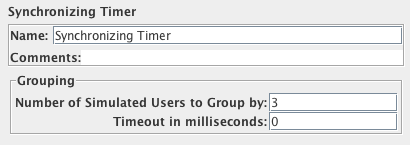
同步定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此定时器的描述性名称。 | 否 |
| 模拟用户组的数量 | 一次释放的线程数。将其设置为0相当于将其设置为线程组中配置的线程数。 |
是 |
| 超时时间(以毫秒为单位) | 如果设置为0,则定时器将等待线程数达到“模拟用户组的数量”中的值。如果大于0,则计时器将以最大“超时时间(以毫秒为单位)” 等待线程数。如果在超时时间之后未达到等待的用户数,则定时器将停止等待。默认为0 |
否 |
如果以毫秒为单位的超时时间设置为
0并且线程数永远不会达到“模拟用户组的数量”,则测试将无限暂停。只有强制停止才能阻止它。在这种情况下,可以考虑设置超时时间。同步定时器阻塞仅在一个JVM内,因此如果使用分布式测试,请确保永远不要将“
模拟用户组的数量”设置为大于其包含的线程组(仅考虑1个注入器)的用户数的值。
BeanShell定时器
BeanShell定时器可用于生成延迟。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223 Sampler+Groovy以提高性能,支持新的Java功能并限制BeanShell库的维护。
测试元件支持ThreadListener和TestListener接口方法。这些必须在初始化文件中定义。有关定义的示例,请参阅文件BeanShellListeners.bshrc。
BeanShell定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。该名称存储在脚本变量Label中 |
否 |
| 每次调用前重置bsh.Interpreter | 如果选择此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息,请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。文件名存储在脚本变量FileName中。返回值用作等待的毫秒数。 |
否 |
| 脚本 | 要运行的BeanShell脚本。返回值用作等待的毫秒数。 | 是(除非提供脚本文件) |
在调用脚本之前,在BeanShell解释器中设置了一些变量:
-
log- (Logger) - 可用于写入日志文件 -
ctx- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
-
props- (JMeterProperties - java.util.Properties类) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
prev- (SampleResult) - 提供对前一个SampleResult的访问(如果有的话)
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc。
如果定义了属性beanshell.listener.init,则用于加载初始化文件,该文件可用于定义在BeanShell脚本中使用的方法等。
JSR223定时器
JSR223定时器可使用JSR223脚本语言生成延迟。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 语言 | 要使用的脚本语言 | 是 |
| 参数 | 要传递给脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的脚本的文件,如果使用相对文件路径,则它将相对于系统属性“user.dir”引用的目录。返回值转换为长整数并用作等待的毫秒数。 |
否 |
| 脚本编译缓存 | 测试计划中的唯一字符串,如果使用的语言支持Compilable接口(Groovy是其中之一,java,beanshell和javascript不是),则JMeter将用于缓存脚本编译的结果。如果您在不检查此选项的情况下使用Groovy,请参阅JSR223取样器Java系统属性中的注释 |
否 |
| 脚本 | 脚本。返回值用作等待的毫秒数。 | 是(除非提供脚本文件) |
在调用脚本之前,脚本解释器中设置了一些变量:
-
log- (Logger) - 可用于写入日志文件 -
CTX- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问权限:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
-
props(JMeterProperties - java.util.Properties类) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
sampler(取样器) - 当前的取样器 -
Label- 定时器的名称 -
FileName- 文件名(如果有) -
OUT-System.out
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc。
泊松随机定时器
该定时器暂停每个线程请求一段随机时间,大部分时间间隔发生在特定值附近。总延迟是泊松分布值和偏移值之和。
注意:如果要对泊松到达进行建模,请考虑使用准确的吞吐量定时器。
泊松随机定时器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此定时器的描述性名称。 | 否 |
| LAMBDA | Lambda值,以毫秒为单位。 | 是 |
| Constant Delay Offset | 除随机延迟之外暂停的毫秒数。 | 是 |
18.7 前置处理器
前置处理器用于修饰其范围内的取样器。
HTML链接解析器
此修饰器解析来自服务器的HTML响应并提取链接和表单。将检查通过此修饰器的URL测试样本,以查看它是否“匹配”从前一个响应中提取的任何链接或表单。然后,它将使用匹配的链接或表单中的适当值替换URL测试样本中的值。Perl类型的正则表达式可用于查找匹配项。
HTML链接解析器控制面板的截图
使用
协议,主机,路径和参数名称执行匹配。目标取样器不能包含不在响应链接中的参数。如果使用分布式测试,请切换模式(请参阅
jmeter.properties)以确保其不在剥离模式下,请参阅Bug 56376。爬虫示例
考虑一个简单的例子:假设您希望JMeter爬取您的站点,在从服务器返回的HTML解析链接后点击链接(这实际上不是最有用的事情,但它是一个很好的例子) 。您将创建一个简单控制器,并对其添加“HTML链接解析器”。然后,创建一个HTTP请求,将域设置为“.*”,并将路径设置为同样。这将使您的测试样本与返回页面上找到的任何链接相匹配。如果要将抓取内容限制为特定域,请将域值更改为所需的域值。然后,将仅遵循指向该域的链接。轮询示例
一个更有用的示例:给定一个Web轮询应用程序,您可能会有一个页面包含多个轮询选项的单选按钮供用户选择。假设轮询选项的值非常动态 - 可能是用户生成的。如果您希望JMeter测试轮询,您可以创建选择了硬编码值的测试样本,也可以让HTML链接解析器解析表单,并在URL测试样本中插入随机轮询选项。为此,请按照上面的示例进行操作,但在配置Web测试控制器的URL选项时,请务必选择“POST”方法。为域,路径和任何其他表单参数输入硬编码值。然后,对于实际的单选按钮参数,输入名称(让我们假设它为"poll_choice“),然后”.*“表示该参数的值。当修饰器检查此URL测试样本时,它会发现它”匹配“轮询表单(并且它不应该匹配任何其他表单,因为您已经指定了URL测试示例的所有其他方面),它将使用表单中的匹配参数替换您的表单参数。由于正则表达式“.*”将与任何内容匹配,因此修饰符可能会有一个单选按钮列表可供选择。它将随机选择,并替换URL测试样本中的值。每次通过测试,将选择一个新的随机值。
图18 - 在线轮询示例
需要记住的一件重要事情是,您必须在返回HTML页面之前立即创建一个测试样本,其中包含与动态测试样本相关的链接和表单。
HTTP URL 重写修饰符
此修饰器与HTML链接分析器的工作方式类似,不同之处在于它具有比HTML链接分析器更易于使用的特定目的,并且效率更高。对于使用URL重写来存储会话ID而不是cookie的Web应用程序,可以在线程组级别附加此元件,就像HTTP Cookie管理器一样。只需为其指定会话ID参数的名称,它就会在页面上找到它并将参数添加到该线程组的每个请求中。
或者,此修饰器可以附加到选择请求,它只会修改它们。聪明的用户甚至可以使用此修饰器获取HTML链接解析器没有获取到的值。
HTTP URL重写修饰符的控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 会话参数名称 | 要从先前响应中获取的参数的名称。此修饰器将在页面上的任何位置找到参数,并获取分配给它的值,无论它是在HREF还是表单中。 | 是 |
| 路径扩展 | 某些Web应用程序通过附加分号和会话ID参数来重写URL。如果是这样,请选中此框。 | 否 |
| Do not use equals in path extension | 某些网络应用程序在参数名称和值之间不使用“=”的情况下重写URL(例如Intershop Enfinity)。 |
否 |
| Do not use questionmark in path extension | 阻止查询字符串以路径扩展结尾(例如Intershop Enfinity)。 | 否 |
| 缓存会话ID? | 是否应保存会话ID的值以供以后使用? | 是 |
| URL编码 | URL写参数时的编码值 | 否 |
如果使用分布式测试,请切换模式(请参阅
jmeter.properties)以确保其不在剥离模式下,请参阅Bug 56376。
用户参数
允许用户指定特定于各个线程的用户变量的值。
用户变量也可以在测试计划中指定,但不是特定于各个线程。此面板允许您为任何用户变量指定一系列值。对于每个线程,将根据序列中的一个值为变量分配一个值。如果线程数多于值,则重新使用这些值。例如,这可以用于分配每个线程使用的不同用户ID。用户变量可以在任何JMeter组件的任何字段中引用。
通过单击面板底部的“添加变量”按钮并在“名称:”列中填写变量名称来指定变量。要向系列添加新值,请单击“添加用户”按钮,然后在新添加的列中填写所需的值。
可以使用函数语法在同一个线程组中的任何测试组件中访问值:${variable}。
另请参见CSV 数据文件设置元件,它更适合于大量参数
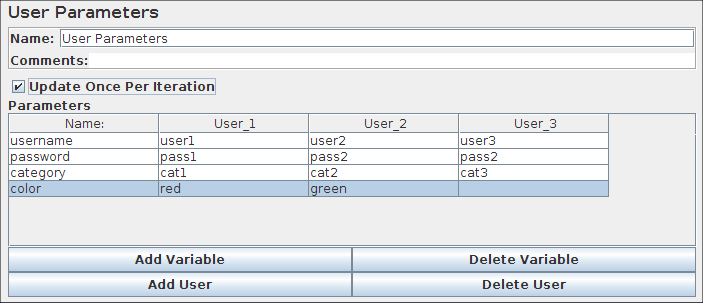
用户参数控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 每次迭代更新一次 | 一个标志,指示用户参数元件是否在每次迭代时更新其变量一次。如果将函数嵌入到用户参数中,则可能需要更好地控制变量值的更新频率。选中此框以确保每次通过用户参数的父控制器更新值。取消选中该框,用户参数将更新其范围内的每个样本请求的参数。 | 是 |
BeanShell预处理程序
BeanShell预处理程序允许在采样之前应用任意代码。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223 Sampler+Groovy以提高性能,支持新的Java功能并限制BeanShell库的维护。
测试元件支持ThreadListener和TestListener接口方法。这些必须在初始化文件中定义。有关定义的示例,请参阅文件BeanShellListeners.bshrc。
BeanShell预处理程序控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此取样器的描述性名称。该名称存储在脚本变量Label中 |
否 |
| 每次调用前重置bsh.Interpreter | 如果选择此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。参数存储在以下变量中:Parameters:包含参数的字符串,作为单个变量bsh.args:包含参数的字符串数组,在空格处分割 |
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。文件名存储在脚本变量FileName中 |
否 |
| 脚本 | BeanShell脚本。返回值被忽略。 | 是(除非提供脚本文件) |
在调用脚本之前,在BeanShell解释器中设置了一些变量:
-
log- (Logger) - 可用于写入日志文件 -
ctx- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
-
props- (JMeterProperties - 类java.util.Properties) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
prev- (SampleResult) - 允许访问前一个SampleResult(如果有的话) -
sampler(SampleEvent)提供对当前取样器的访问
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc。
如果定义了属性beanshell.listener.init,则用于加载初始化文件,该文件可用于定义在BeanShell脚本中使用的方法等。
JSR223预处理程序
JSR223预处理程序允许在采样之前应用JSR223脚本代码。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 语言 | 要使用的JSR223脚本语言 | 是 |
| 参数 | 要传递给脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的脚本的文件,如果使用相对文件路径,则它将相对于系统属性“user.dir”引用的目录。 |
否 |
| 脚本编译缓存 | 测试计划中的唯一字符串,如果使用的语言支持Compilable接口(Groovy是其中之一,java,beanshell和javascript不是),则JMeter将用于缓存脚本编译的结果。如果您在不检查此选项的情况下使用Groovy,请参阅JSR223取样器Java系统属性中的注释 |
否 |
| 脚本 | 要运行的脚本。 | 是(除非提供脚本文件) |
在调用脚本之前,会设置一些变量。请注意,这些是JSR223变量 - 即它们可以直接在脚本中使用。
-
log- (Logger) - 可用于写入日志文件 -
Label- 标签字符串 -
FileName- 脚本文件名(如果有) -
Parameters- 参数(作为字符串) -
ARGS- 作为字符串数组的参数(在空格上拆分) -
CTX- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问权限:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object()); vars.getObject("OBJ2");
-
props- (JMeterProperties - 类java.util.Properties) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
sampler- (取样器) - 允许访问最后一个取样器 -
OUT-System.out- 例如OUT.println("message")
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc
JDBC预处理程序
JDBC预处理程序使您可以在样本运行之前运行一些SQL语句。如果JDBC样本需要某些数据位于数据库中,并且无法在初始化线程组中计算此数据,则此选项非常有用。有关详细信息,请参阅JDBC请求。
请参阅以下测试计划:
另请参阅:
在链接的测试计划中,“Create Price Cut-Off”JDBC预处理程序调用存储过程在数据库中创建Price Cut-Off,这个将由“Calculate Price cut off”使用。
Create Price Cut-Off预处理程序
正则表达式用户参数
允许使用正则表达式从一个HTTP请求中提取指定动态值并传递到另一个HTTP参数。正则表达式用户参数特定于各个线程。
此组件允许您指定提取HTTP请求参数的名称和值的正则表达式的引用名称。必须为参数名称和参数值指定正则表达式组编号。仅对使用此名称匹配的正则表达式用户参数的取样器中的参数进行替换。

正则表达式用户参数控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Regular Expression Reference Name | 正则表达式的引用名称 | 是 |
| Parameter names regexp group number | 用于提取参数名称的正则表达式的组编号 | 是 |
| Parameter values regex group number | 用于提取参数值的正则表达式的组编号 | 是 |
正则表达式示例
假设我们有一个返回带有3个输入参数的表单的请求,我们想要提取其中2个的值,以便在下一个请求中注入它们
- 为第一个HTTP请求创建正则表达式后置处理器
引用名称- 设置正则表达式的名称(listParams)正则表达式- 将提取输入名称和输入值属性的表达式 正则表达式:input name="([^"]+?)" value="([^"]+?)"模板- 将是空的匹配数字--1(为了遍历所有可能的匹配)- 为第二个HTTP请求创建预处理程序正则表达式用户参数
引用名称- 设置正则表达式的相同引用名称,在我们的示例中是listParamsParameter names group number- 参数名称的正则表达式的组编号,在我们的示例中为1Parameter values group number- 参数值的正则表达式的组编号,在我们的示例中为2
另请参阅正则表达式提取器元件,该元件用于提取参数名称和值。
另请参阅:
取样器超时
如果完成时间过长,此前置处理器会调度计时器任务以中断样本。如果超时为零或为负,则忽略超时。为此,取样器必须实现可中断。已知以下取样器可实现: AJP,BeanShell,FTP,HTTP,Soap,AccessLog,邮件阅读者,JMS订阅,TCP取样器,测试活动,Java取样器
此测试元件适用于连接超时或响应超时等单个超时不足或取样器不支持超时的情况。超时应设置得足够长,以使在正常测试中不会被触发,同时要足够短以使它会能中断被卡住的样本。
【默认情况下,JMeter使用Callable来中断取样器。这与定时器在同一个线程中执行,因此如果中断需要很长时间,则可能会延迟后续超时的处理。这不是一个问题,但如果有必要, 可以将属性InterruptTimer.useRunnable设置为true以使用单独的Runnable线程而不是Callable。】
取样器超时控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此定时器的描述性名称。 | 否 |
| Sample Timeout | 样本执行超出时间后,将被中断。 | 是 |
18.8 后置处理器
顾名思义,后置处理器适用于取样器之后。请注意,它们适用于同一范围内的所有取样器,因此要确保后置处理器仅应用于特定取样器,请将其添加为取样器的子级。
注意:除非另有说明,否则后置处理器不适用于子样本 - 仅适用于父样本。对于JSR223和BeanShell后置处理器,脚本可以使用
prev.getSubResults()方法检索子样本,该方法返回SampleResults数组。如果没有,则数组将为空。
后置处理器在断言之前运行,因此它们无法访问任何断言结果,样本状态也不会反映任何断言的结果。如果您需要访问断言结果,请尝试使用监听器。另请注意,在运行所有断言后,变量JMeterThread.last_sample_ok设置为“true”或“false”。
正则表达式提取器
允许用户使用Perl类型的正则表达式从服务器响应中提取值。作为后置处理器,此元件将在其范围内的每个样本请求之后执行,应用正则表达式,提取请求的值,生成模板字符串,并将结果存储到给定的变量名称中。
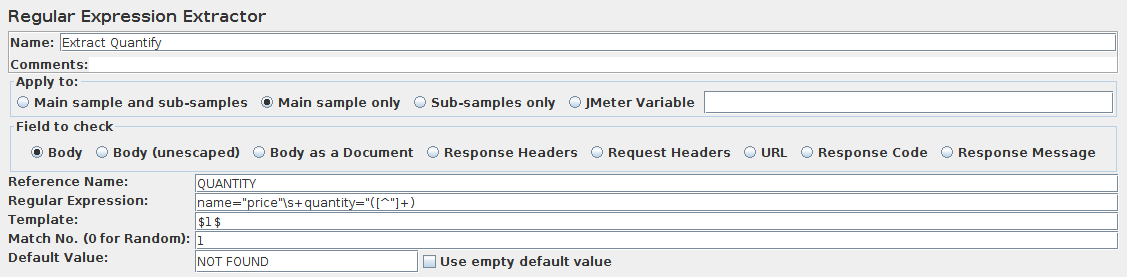
正则表达式提取器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
3,仅适用于子样本,提取器将匹配第3个子样本。对于匹配数=3,匹配主样本和子样本,提取器将匹配第2个子样本(第1个匹配是主样本)。对于匹配数字=0或负数,将处理所有符合条件的样本。对于匹配数字>0,匹配将在找到足够的匹配后立即停止。 |
是 |
| 要检查的响应字段 | 可以检查以下字段:
|
是 |
| 引用名称 | 用于存储结果的JMeter变量的名称。另请注意,每个组都存储为形如[refname]_g#,其中[refname]是您输入的作为引用名称的字符串,#是组号,其中组0是整个匹配,组1是第一组括号的匹配等 |
是 |
| 正则表达式 | 用于解析响应数据的正则表达式。除非使用组$0$,否则必须包含至少一组括号“()”来捕获字符串的一部分。不要将表达式括在/ /中 - 除非你确实想要匹配这些字符。 |
是 |
| 模板 | 用于从找到的匹配项创建字符串的模板。这是一个包含特殊元素的任意字符串,用于引用正则表达式中的组。引用组的语法是:'$1$'表示组1,'$2$'表示组2,等等。$0$表示整个表达式匹配的内容。 |
是 |
| 匹配数字(0代表随机) | 指示要使用的匹配项。正则表达式可以多次匹配。
|
是 |
| 缺省值 | 如果正则表达式没有匹配,则引用变量将设置为默认值。这对于调试测试特别有用。如果没有提供默认值,则很难判断是正则表达式没有匹配,还是正则表达式元件未处理或者使用了错误的变量。 然而,如果您有多个设置相同变量的测试元件,如果表达式没有匹配,您可能希望保持变量不变。在这种情况下,请在调试完成后删除默认值。 |
否,但推荐 |
| 使用空默认值 | 如果选中该复选框并且缺省值为空,则JMeter会将变量设置为空字符串而不是不设置它。因此,当您在测试计划中使用${var}(假设引用名称为var)时,如果未找到提取的值,则${var}的值将等于空字符串而不是${var},如果提取的值是可选的,这可能非常有用。 |
否 |
如果匹配号设置为非负数,并且匹配到内容,则变量设置如下:
refName- 模板的值refName_gn,其中n=0,1,2- 匹配的组refName_g- 正则表达式中的组数(不包括0)
如果没有匹配,则将refName变量设置为默认值(除非不存在)。此外,删除以下变量:
refName_g0refName_g1refName_g
如果匹配号设置为负数,则处理取样器数据中的所有可能匹配。变量设置如下:
refName_matchNr- 找到的匹配数;可能是0refName_n,其中n=0,1,2等 - 由模板生成的字符串refName_n_gm,其中m=0,1,2- 匹配n的组refName- 始终设置为默认值refName_gn- 未设置
注意在这种情况下,refName变量始终设置为默认值,并且未设置关联的组变量。
有关如何指定修饰符及关于JMeter正则表达式的更多信息,请参阅响应断言。
CSS选择器提取器(即:CSS/JQuery提取器)
允许用户使用CSS选择器语法从服务器HTML响应中提取值。作为后置处理器,此元件将在其范围内的每个样本请求之后执行,应用CSS/JQuery表达式,提取所请求的节点,将节点提取为文本或属性值并将结果存储到给定的变量名称中。
CSS选择器提取器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
3,仅适用于子样本,提取器将匹配第3个子样本。对于匹配数=3,匹配主样本和子样本,提取器将匹配第2个子样本(第1个匹配是主样本)。对于匹配数字=0或负数,将处理所有符合条件的样本。对于匹配数字>0,匹配将在找到足够的匹配后立即停止。 |
是 |
| CSS选择器实现 | 支持基于CSS/JQuery语法的2种实现:如果选择器设置为空,则将使用默认实现(JSoup)。 | 是 |
| 引用名称 | 用于存储结果的JMeter变量的名称。 | 是 |
| CSS/JQuery表达式 | CSS / JQuery选择器用于从响应数据中选择节点。支持选择器,选择器组合和伪选择器,示例:
|
是 |
| 属性 | 从与选择器匹配的节点中提取的属性名称(根据HTML语法)。如果为空,则返回此元素及其所有子元素的组合文本。 如果设置了属性,这是JSoup的等效Element#attr(name)函数。 设置属性值的CSS选择器 如果为空,这相当于JSoup 的Element#text()函数,如果没有为属性设置值。  没有设置属性的CSS选择器 |
是 |
| 匹配数字(0代表随机) | 指示要使用的匹配项。CSS/JQuery选择器可能会多次匹配。
|
是 |
| 缺省值 | 如果表达式没有匹配,则引用变量将设置为默认值。这对于调试测试特别有用。如果没有提供默认值,则很难判断是表达式没有匹配,还是CSS/JQuery元件未处理或者使用了错误的变量。 然而,如果您有多个设置相同变量的测试元件,如果表达式没有匹配,您可能希望保持变量不变。在这种情况下,请在调试完成后删除默认值。 |
否,但推荐 |
| 使用空默认值 | 如果选中该复选框并且缺省值为空,则JMeter会将变量设置为空字符串而不是不设置它。因此,当您在测试计划中使用${var}(假设引用名称为var)时,如果未找到提取的值,则${var}的值将等于空字符串而不是${var},如果提取的值是可选的,这可能非常有用。 |
否 |
如果匹配号设置为非负数,并且匹配发生,则变量设置如下:
refName- 模板的值
如果不匹配,则将refName变量设置为默认值(除非不存在)。
如果匹配号设置为负数,则处理取样器数据中的所有可能匹配。变量设置如下:
refName_matchNr- 找到的匹配数;可能是0refName_n,其中n=0,1,2等 - 由模板生成的字符串refName- 始终设置为默认值
请注意,在这种情况下,refName变量始终设置为默认值。
XPath2 Extractor
此测试元件允许用户使用XPath2查询语言从结构化响应(XML或(X)HTML)中提取值。
XPath2 Extractor控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
|
是 |
| Return entire XPath fragment instead of text content? | 如果选中,将返回片段而不是文本内容。 例如 //title将返回“<title>Apache JMeter</title>”而不是“Apache JMeter”。在这种情况下, //title/text()将返回“Apache JMeter”。 |
是 |
| 引用名称 | 用于存储结果的JMeter变量的名称。 | 是 |
| XPath Query | XPath 2.0语言的元素查询。可以返回多个匹配项。 | 是 |
| 匹配数字(0代表随机) | 如果XPath路径查询导致许多结果,您可以选择要提取哪个(些)作为变量:
|
否 |
| 缺省值 | 找不到匹配项时返回默认值。如果节点没有值并且未选择片段选项,也会返回它。 | 是 |
| Namespaces aliases list | 用于解析文档的命名空间别名列表,每个声明一行。您必须将它们指定为:prefix=namespace这样的。此实现使得使用命名空间比使用旧版本的XPath提取器更容易。 |
否 |
要允许在ForEach控制器中使用,它的工作方式与上面的XPath提取器完全相同。
XPath2 Extractor提供了一些有趣的工具,例如改进的语法和比它的第一个版本更多的功能。
以下是一些例子:
-
abs(/book/page[2])从book中提取第2个page的绝对值
-
avg(/librarie/book/page)从librarie中的所有book中提取平均page数
-
compare(/book[1]/page[2],/book[2]/page[2])如果第1个book的第2个page等于第2个book的第2个page,返回整数值0,否则返回-1。
要查看有关函数的更多信息,请参阅xPath2函数。
XPath提取器
此测试元件允许用户使用XPath查询语言从结构化响应(XML或(X)HTML)中提取值。
从JMeter 5.0开始,您应该使用XPath2 Extractor,因为它提供了更好,更简单的命名空间管理,更好的性能和对XPath 2.0的支持
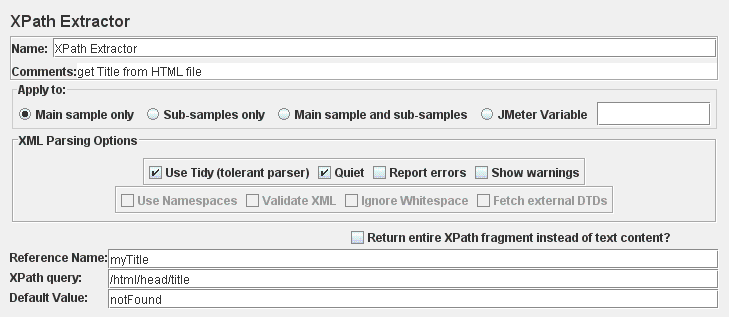
XPath提取器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
|
是 |
| Use Tidy (tolerant parser) | 如果选中则使用Tidy将HTML响应解析为XHTML。
对于HTML,CSS选择器提取器是正确且有效的方案。不要将XPath用于HTML提取。 |
是 |
| Quiet | 设置Tidy Quiet标志 | 如果选择了Tidy |
| 报告异常 | 如果发生Tidy异常,则相应地设置断言 | 如果选择了Tidy |
| 显示警告 | 设置Tidy显示警告选项 | 如果选择了Tidy |
| Use Namespaces | 如果选中,则XML解析器将使用命名空间解析。(请参阅下面关于命名空间的注释)注意目前只能识别在根元素上声明的命名空间。有关用户定义的其他工作区名称的,请参见下文。 | 如果未选择Tidy |
| Validate XML | 根据其架构检查文档。 | 如果未选择Tidy |
| Ignore Whitespace | 忽略空白元素。 | 如果未选择Tidy |
| Fetch External DTDs | 如果选中,则获取外部DTD。 | 如果未选择Tidy |
| Return entire XPath fragment instead of text content? | 如果选中,将返回片段而不是文本内容。 例如 //title将返回“<title>Apache JMeter</title>”而不是“Apache JMeter”。在这种情况下, //title/text()将返回“Apache JMeter”。 |
是 |
| 引用名称 | 用于存储结果的JMeter变量的名称。 | 是 |
| XPath Query | XPath语言的元素查询。可以返回多个匹配项。 | 是 |
| 匹配数字(0代表随机) | 如果XPath路径查询导致许多结果,您可以选择要提取哪个(些)作为变量:
|
否 |
| 缺省值 | 找不到匹配项时返回默认值。如果节点没有值并且未选择片段选项,也会返回它。 | 否 |
要允许在ForEach控制器中使用,请在返回时设置以下变量:
refName- 设置为第一个(或唯一)匹配;如果没有匹配,则设置为默认值refName_matchNr- 设置为匹配数字(可能为0)refName_n,n=0,1,2等。设置为第1,第2,第3个匹配等
注意:下一个
refName_n变量设置为null- 例如,如果有2个匹配项,则refName_3设置为null,如果没有匹配项,则refName_1设置为null。
XPath是主要针对XSLT转换的查询语言。然而,它也可用作结构化数据的通用查询语言。有关更多信息,请参阅 XPath参考或XPath规范。以下是一些例子:
-
/html/head/title从HTML响应中提取title元素
-
/book/page[2]提取book中的第2个page
-
/book/page提取book中的所有page
-
//form[@name='countryForm']//select[@name='country']/option[text()='Czech Republic'])/@value提取name属性为
countryForm的form下name属性为country的select元素下包含Czech Republic文本的option元素的value属性
选中“
Use Tidy"时 - 生成的XML文档可能与原始HTML响应略有不同:
- 所有元素和属性名称都转换为小写
- Tidy尝试纠正不正确的嵌套元素。例如 - 原始(不正确)
ul/font/li变为正确的ul/li/font有关更多信息,请参阅Tidy主页。
命名空间
作为Xalan XPath解析器(JMeter所基于的实现)的命名空间限制的工作轮,您需要:
提供一个属性文件(例如,如果您的文件名为namespaces.properties),其中包含名称空间前缀的映射:
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …通过在
user.properties文件中引用此文件来使用属性:xpath.namespace.config=namespaces.properties
//mynamespace:tagname
//*[local-name()='tagname' and namespace-uri()='uri-for-namespace']
uri-for-namespace mynamespace
结果状态处理器
此测试元件允许用户在相关取样器发生故障后停止线程或整个测试。
结果状态处理器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 在取样器错误后要执行的动作 | 决定取样器发生错误(包括样本本身失败或断言失败)时发生什么。可能的选择是:
|
否 |
BeanShell后置处理程序
BeanShell预处理程器允许在采集样本后应用任意代码。
BeanShell后置处理程器不再忽略具有零长度结果数据的样本。
有关使用BeanShell的完整详细信息,请参阅BeanShell网站。
强烈建议迁移到JSR223 Sampler+Groovy以提高性能,支持新的Java功能并限制BeanShell库的维护。
测试元件支持ThreadListener和TestListener接口方法。这些必须在初始化文件中定义。有关定义的示例,请参阅文件BeanShellListeners.bshrc。
BeanShell后置处理程序控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。该名称存储在脚本变量Label中 |
否 |
| 每次调用前重置bsh.Interpreter | 如果选择此选项,则将为每个样本重新创建解释器。对于某些长时间运行的脚本,这可能是必需的。有关详细信息请参阅最佳实践 - BeanShell脚本。 | 是 |
| 参数 | 要传递给BeanShell脚本的参数。参数存储在以下变量中:Parameters:包含参数的字符串,作为单个变量bsh.args:包含参数的字符串数组,在空格处分割 |
否 |
| 脚本文件 | 包含要运行的BeanShell脚本的文件。文件名存储在脚本变量FileName中 |
否 |
| 脚本 | 要运行的BeanShell脚本。返回值被忽略。 | 是(除非提供脚本文件) |
设置以下BeanShell变量供脚本使用:
-
log- (Logger) - 可用于写入日志文件 -
ctx- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object());
-
props- (JMeterProperties - 类java.util.Properties) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
prev- (SampleResult) - 提供对前一个SampleResult的访问 -
data(byte [])提供对当前样本数据的访问
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc。
如果定义了属性beanshell.listener.init,则用于加载初始化文件,该文件可用于定义在BeanShell脚本中使用的方法等。
JSR223后置处理程序
JSR223后置处理程序允许在获取样本后应用JSR223脚本代码。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 语言 | 要使用的JSR223语言 | 是 |
| 参数 | 要传递给脚本的参数。参数存储在以下变量中:
|
否 |
| 脚本文件 | 包含要运行的脚本的文件,如果使用相对文件路径,则它将相对于系统属性“user.dir”引用的目录 |
否 |
| 脚本编译缓存 | 测试计划中的唯一字符串,如果使用的语言支持Compilable接口(Groovy是其中之一,java,beanshell和javascript不是),则JMeter将用于缓存脚本编译的结果。如果您在不检查此选项的情况下使用Groovy,请参阅JSR223取样器Java系统属性中的注释 |
否 |
| 脚本 | 要运行的脚本。 | 是(除非提供脚本文件) |
在调用脚本之前,会设置一些变量。请注意,这些是JSR223变量 - 即它们可以直接在脚本中使用。
-
log- (Logger) - 可用于写入日志文件 -
Label- 标签字符串 -
FileName- 脚本文件名(如果有) -
Parameters- 参数(作为字符串) -
ARGS- 作为字符串数组的参数(在空格上拆分) -
CTX- (JMeterContext) - 允许访问上下文 -
vars- (JMeterVariables) - 提供对变量的读/写访问权限:vars.get(key); vars.put(key,val); vars.putObject("OBJ1",new Object()); vars.getObject("OBJ2");
-
props- (JMeterProperties - 类java.util.Properties) - 例如props.get("START.HMS");props.put("PROP1","1234"); -
prev- (SampleResult) - 允许访问上一个SampleResult(如果有的话) -
sampler- (取样器) - 提供对当前取样器的访问 -
OUT-System.out- 例如OUT.println("message")
有关上述每个变量的所有可用方法的详细信息,请查看Javadoc
JDBC后置处理程序
JDBC后置处理程序使您可以在样本运行后立即运行一些SQL语句。如果JDBC样本更改了某些数据,并且您希望将状态重置为JDBC样本运行之前的状态,那么这将非常有用。
另请参阅:
在链接的测试计划中,JDBC后置处理程序“JDBC PostProcessor”调用存储过程从数据库中删除由前置处理器创建的Price Cut-Off。
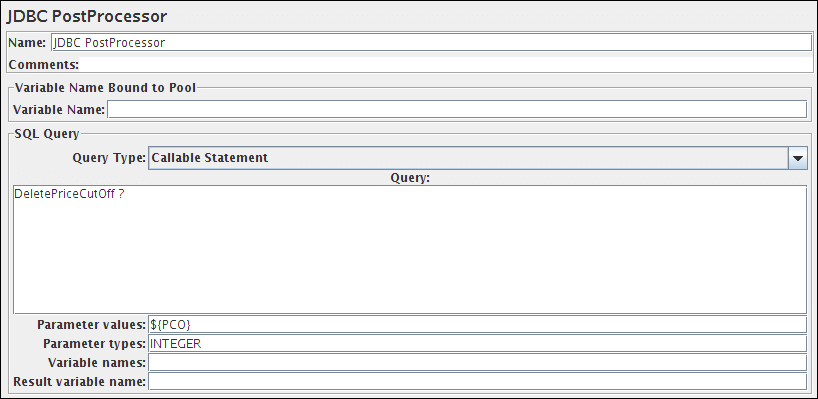
JDBC后置处理程序
JSON提取器
JSON后置处理程序使您可以使用JSON-PATH语法从JSON响应中提取数据。此后处理器与正则表达式提取器非常相似。它必须作为HTTP取样器或具有响应的其他任何取样器的子项放置。它将允许您以非常简单的方式提取文本内容,请参阅JSON Path语法。
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Names of created variables | 以分号分隔的变量名称,用于包含JSON-PATH表达式的结果(必须与JSON-PATH表达式的数量匹配) | 是 |
| JSON Path Expressions | 分号分隔的JSON-PATH表达式(必须匹配变量数量) | 是 |
| Default Values | 以分号分隔的默认值,如果JSON-PATH表达式不返回任何结果则取默认值(必须匹配变量数量) | 否 |
| Match No. (0 for Random) | 如果JSON Path查询导致许多结果,您可以选择要提取哪个(些)作为变量:
|
否 |
| Compute concatenation var | 如果找到很多结果,插件将使用','分隔符将它们连接起来并存储在名为<variable name>_ALL的变量中 |
否 |
JSON后置处理程序
边界提取器
允许用户使用左右边界从服务器响应中提取值。作为后置处理器,此元件将在其范围内的每个样本请求之后执行,测试边界,提取请求的值,生成模板字符串,并将结果存储到给定的变量名称中。
边界提取器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| Apply to: | 这适用于可以生成子样本的取样器,例如带有内嵌资源的HTTP取样器,邮件阅读者或事务控制器生成的样本。
3,仅适用于子样本,提取器将匹配第3个子样本。对于匹配数=3,匹配主样本和子样本,提取器将匹配第2个子样本(第1个匹配是主样本)。对于匹配数字=0或负数,将处理所有符合条件的样本。对于匹配数字>0,匹配将在找到足够的匹配后立即停止。 |
是 |
| 要检查的响应字段 | 可以检查以下字段:
|
是 |
| 引用名称 | 用于存储结果的JMeter变量的名称。另请注意,每个组都存储为形如[refname]_g#,其中[refname]是您输入的作为引用名称的字符串,#是组号,其中组0是整个匹配,组1是第一组括号的匹配等 |
是 |
| 左边界 | 寻找值的左边界 | 是 |
| 右边界 | 寻找值的右边界 | 是 |
| 匹配数字(0代表随机) | 指示要使用的匹配项。正则表达式可以多次匹配。
|
是 |
| 缺省值 | 如果边界没有匹配,则引用变量将设置为默认值。这对于调试测试特别有用。如果没有提供默认值,则很难判断是边界没有匹配,还是使用了错误的变量。 然而,如果您有多个设置相同变量的测试元件,如果表达式没有匹配,您可能希望保持变量不变。在这种情况下,请在调试完成后删除默认值。 |
否,但推荐 |
如果匹配号设置为非负数,并且匹配到内容,则变量设置如下:
refName- 提取的值
如果没有匹配,则将refName变量设置为默认值(除非不存在)。
如果匹配号设置为负数,则处理取样器数据中的所有可能匹配。变量设置如下:
refName_matchNr- 找到的匹配数;可能是0refName_n,其中n=0,1,2等 - 由模板生成的字符串refName_n_gm,其中m=0,1,2- 匹配n的组refName- 始终设置为默认值
注意在这种情况下,refName变量始终设置为默认值,并且未设置关联的组变量。
18.9 其他功能
测试计划
测试计划是指定测试总体设置的位置。
可以为整个测试中重复的值定义静态变量,例如服务器名称。例如,变量SERVER可以定义为www.example.com,测试计划的其余部分可以使用${SERVER}来引用它。这简化了以后改名的过程。
如果在一个或多个用户定义的变量配置元件上重用相同的变量名称 ,则该值将被测试计划中最后一个定义(从上到下读取)所设置。此类变量应用于可能在测试运行之间更改但在测试运行期间保持不变的项目。
注意测试计划不能引用它自身定义的变量。
如果需要从“测试计划”变量构造其他变量,请使用“用户定义的变量”测试元件。
选择函数测试会使JMeter将额外的样本信息(响应数据和取样器数据)保存到所有结果文件。这增加了运行测试所需的资源,并可能对JMeter性能产生负面影响。如果仅是特定取样器需要更多数据,则向其添加监听器,并根据需要配置字段。
该选项不会影响当前无法存储此类信息的CSV结果文件。
此外,此处还存在一个选项,指示JMeter以串行方式而不是并行方式运行线程组。
主线程结束后运行tearDown线程组:如果选中,则在正常结束主线程后运行tearDown线程组(如果有)。如果强制停止测试,则不会运行tearDown线程。
测试计划现在提供了一种将classpath设置添加到特定测试计划的简便方法。该功能是附加的,这意味着您可以添加jar文件或目录,但删除条目需要重新启动JMeter。
注意这不能用于添加JMeter GUI插件,因为它们是前置处理的。
但是,它对于诸如JDBC驱动程序之类的实用程序jar可能很有用。jar只会添加到JMeter加载器的搜索路径中,而不会添加到系统类加载器中。
JMeter属性还提供了一个用于加载其他classpath的条目。在jmeter.properties中,编辑“user.classpath”或“plugin_dependency_paths”以包含其他库。有关详细信息,请参阅JMeter的classpath和 配置JMeter。
测试计划控制面板的截图
线程组
线程组定义了一个用户池,它将针对您的服务器执行特定的测试用例。在线程组GUI中,您可以控制模拟的用户数(线程数),ramp-up时间(启动所有线程所需的时间),执行测试的次数以及可选的启动和停止测试的时间。
另请参见tearDown线程组和setUp线程组。
使用调度器时,JMeter会运行线程组,直到达到循环次数或达到持续时间/结束时间 - 以先发生者为准。请注意,仅在样本之间检查条件;当达到结束条件时,该线程将停止。JMeter不会中断等待响应的取样器,因此结束时间可能会被任意延迟。
线程组控制面板的截图
从JMeter 3.0开始,您可以通过选择并右键单击来运行选定的线程组。将出现一个弹出菜单:
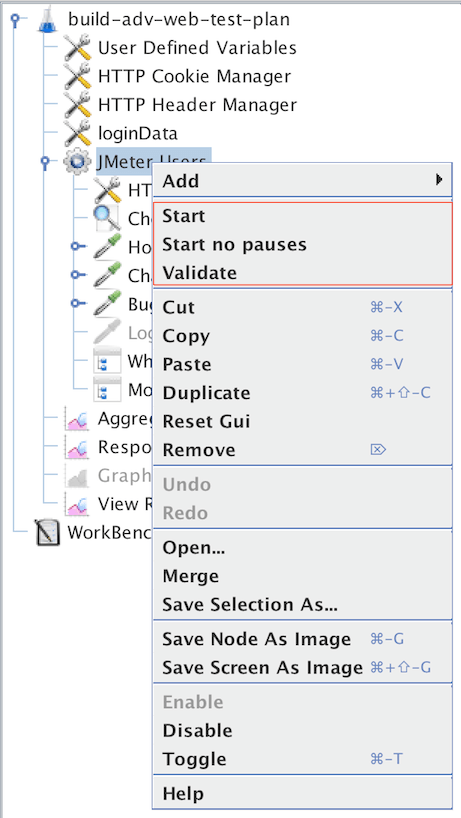
启动选定线程组的弹出菜单
注意您有3个选项来运行选定的线程组:
- 启动:仅启动选定的线程组
- 不停顿启动:仅启动选定的线程组,但不运行定时器
- 验证:仅使用验证模式启动选定的线程组。默认情况下,它以验证模式运行线程组(见下文)
验证模式:
此模式通过运行1个线程,1次迭代,不运行定时器并且启动延时设置为0来启用线程组的快速验证。此行为的某些属性可以通过在user.properties中设置来修改:
testplan_validation.nb_threads_per_thread_group:用于验证线程组的线程数,默认为1testplan_validation.ignore_timers:在验证计划的线程组时忽略定时器,默认为1testplan_validation.number_iterations:用于验证线程组的迭代次数testplan_validation.tpc_force_100_pct:是否在百分比模式下以100%强制运行吞吐量控制器。默认为false
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 在取样器错误后要执行的动作 | 决定取样器发生错误(包括样本本身失败或断言失败)时发生什么。可能的选择是:
|
否 |
| 线程数 | 要模拟的用户数。 | 是 |
| Ramp-up时间 | JMeter启动所有线程花费的时间。如果有10个线程且ramp-up时间为100秒,则每个线程将在前一个线程启动后10秒开始,总时间为100秒,以使测试完全达到速度。 | 是 |
| 循环次数 | 执行测试用例的次数。或者,可以选择“永远”,使测试运行直到手动停止。 |
是,除非选中永远 |
| 延迟创建线程直到需要 | 如果选中,则仅在ramp-up时间的适当比例已经过去时创建线程。这最适合于ramp-up时间明显长于执行单个线程的时间的测试。即新的线程开始晚于之前的线程结束。 如果未选中,则在测试开始时创建所有线程(然后它们会暂停适当的ramp-up时间比例)。这是最初的默认值,适用于大多数测试中线程处于活动状态的测试。 |
是 |
| 调度器 | 如果选中,则启用调度器 | 是 |
| 持续时间(秒) | 如果选择了调度器复选框,则可以选择相对结束时间。JMeter将使用它来计算结束时间。 | 否 |
| 启动延迟(秒) | 如果选择了调度器复选框,则可以选择相对启动延迟。JMeter将使用它来计算开始时间。 | 否 |
工作台
SSL管理器
SSL管理器是一种选择客户端证书的方法,以便您可以测试使用公钥基础结构(PKI)的应用程序。仅在尚未设置相应的系统属性时才需要它。
如果要测试客户端证书身份验证,请参阅密钥库配置
选择客户证书
您可以使用Java密钥库(JKS)格式密钥库,也可以使用公钥证书标准#12(PKCS12)文件作为客户端证书。JSSE库的一个功能是要求您的密钥至少具有六个字符的密码(至少对于JDK附带的keytool实用程序)。
要选择客户端证书,请在菜单栏中选择选项 → SSL管理器。您将看到一个文件查找器,默认情况下查找PKCS12文件。您的PKCS12文件必须具有扩展名“.p12”,以便SSL管理器将其识别为PKCS12文件。任何其他文件将被视为普通的JKS密钥库。如果正确安装了JSSE,系统将提示您输入密码。文本框不会隐藏您此时键入的字符 - 因此请确保没有人偷看。当前实现假定密钥库的密码也是要进行身份验证的客户端的私钥的密码。
或者,您可以设置适当的系统属性 - 请参阅system.properties文件。
下次运行测试时,SSL管理器将检查您的密钥库,以查看它是否至少有一个密钥可用。如果只有一个密钥,SSL管理器将为您选择它。如果有多个密钥,则目前选择第一个密钥。目前无法在密钥库中选择其他条目,因此所需的密钥必须是第一个。
值得关注的事情
如果没有JDK附带的五个CA证书之一的签名,则必须正确安装证书颁发机构(CA)的证书。安装它的一种方法是将CA证书导入JKS文件,并将JKS文件命名为“jssecacerts”。将文件放在JRE的lib/security文件夹下。此文件将在同一目录中的“cacerts”文件之前读取。请记住,只要存在“jssecacerts”文件,就不会使用“cacerts”中安装的证书。这可能会给您带来麻烦。如果您不介意将CA证书导入“cacerts“文件,您可以对安装的所有CA证书进行身份验证。
HTTP(S)测试脚本录制器 (即:HTTP代理服务器)
HTTP(S)测试脚本记录器允许JMeter在您使用普通浏览器浏览Web应用程序时拦截和记录您的操作。JMeter将创建测试样本对象并将其直接存储到您的测试计划中(因此您可以在制作样本时以交互方式查看样本)。
确保您阅读此Wiki页面以正确设置JMeter。
要使用记录器,请添加 HTTP(S)测试脚本记录器元件。右键单击测试计划元件以获取添加菜单:( 添加 → 非测试元件 → HTTP代理服务器 )。
记录器实现为HTTP(S)代理服务器。您需要设置浏览器使用代理来处理所有HTTP和HTTPS请求。
不要将JMeter用作任何其他请求类型的代理 - FTP等 - 因为JMeter无法处理它们。
理想情况下,在录制会话时使用隐私浏览模式。这将确保浏览器在没有存储cookie的情况下启动,并防止保存某些更改。例如,Firefox不允许永久保存证书覆盖。
HTTPS录制和证书
HTTPS连接使用证书来验证浏览器和Web服务器之间的连接。通过HTTPS连接时,服务器会将证书提供给浏览器。为了验证证书,浏览器检查服务器证书是否由链接到其内置根CA之一的证书颁发机构(CA)签名。
浏览器还会检查证书是否适用于正确的主机或域,并且证书有效且未过期。
如果任何浏览器检查失败,它将提示用户决定是否允许连接继续。
JMeter需要使用自己的证书来拦截来自浏览器的HTTPS连接。实际上,JMeter必须伪装成目标服务器。
JMeter将生成自己的证书。这些是通过属性proxy.cert.validity生成的,包含一个默认为7天有效期和随机密码。如果JMeter检测到它在Java 8或更高版本下运行,除非定义了以下属性:proxy.cert.dynamic_keys=false,否则它将根据需要为每个目标服务器生成证书(动态模式)。使用动态模式时,证书将使用正确的主机名,并由JMeter生成的CA证书签名。默认情况下,浏览器不会信任此CA证书,但可以将其安装为受信任的证书。完成此操作后,浏览器将接受生成的服务器证书。这样做的好处是,即使是内含的HTTPS资源也可以被拦截,并且不需要覆盖每个新服务器的浏览器检查。
浏览器不会提示内含的资源。因此,对于早期版本,只能为已经被浏览器“知道”的服务器下载内含的资源
除非提供了密钥库(并且您定义了属性proxy.cert.alias),否则 JMeter需要使用keytool应用程序来创建密钥库条目。JMeter包含通过查看各种标准位置来检查keytool是否可用的代码。如果JMeter无法找到keytool应用程序,它将报告错误。如有必要,可以使用系统属性keytool.directory告诉JMeter在哪里找到keytool。这应该在文件system.properties中定义。
按下 “启动”按钮时会生成JMeter证书(如有必要)。
证书生成可能需要一段时间,在此期间GUI将无响应。
当这种情况发生时,光标变为沙漏。证书生成完成后,GUI将显示一个弹出对话框,其中包含根CA的证书详细信息。该证书需要由浏览器安装,以便它接受JMeter生成的主机证书;详见下文。
如有必要,可以通过从JMeter目录中删除密钥库文件proxyserver.jks来强制JMeter重新生成密钥库(以及导出的证书 - ApacheJMeterTemporaryRootCA[.usr|.crt])。
此证书不是浏览器和正确的主机通常信任的证书之一。
作为结果:
-
浏览器应显示一个对话框,询问您是否要接受证书。例如:
1)服务器名称“www.example.com”与证书名称不匹配 “JMeter Proxy (DO NOT TRUST)”。有人可能会试图窃听你。 2)“JMeter Proxy (DO NOT TRUST)”的证书由未知证书颁发机构签署 “JMeter Proxy (DO NOT TRUST)”。无法验证这是否是有效证书。
您需要接受证书才能允许JMeter代理拦截SSL流量以进行录制。但是,请勿永久接受此证书;应该只是暂时接受。浏览器仅针对主URL的证书提示此对话,而不是针对页面中加载的资源,例如托管在安全的外部CDN上的图像,CSS或JavaScript文件。如果您有这样的资源(例如gmail),您必须首先手动浏览这些其他域,以便为他们接受JMeter的证书。在
jmeter.log中检查您需要注册证书的安全域。 -
如果浏览器已经为此域注册了经过验证的证书,则浏览器会将JMeter检测为安全漏洞,并拒绝加载该页面。如果是这样,您必须从浏览器的密钥库中删除可信证书。
从2.10开始的JMeter版本仍然支持此方法,如果您定义了以下属性,它将继续这样做:proxy.cert.alias。以下属性可用于更改使用的证书:
proxy.cert.directory- 查找证书的目录(默认= JMeterbin/)proxy.cert.file- 密钥库文件的名称(默认为“proxyserver.jks”)proxy.cert.keystorepass- 密钥库密码(默认为“password”)[如果使用JMeter证书则忽略]proxy.cert.keypassword- 证书密钥密码(默认为“password”)[如果使用JMeter证书则忽略]proxy.cert.type- 证书类型(默认为“JKS”)[如果使用JMeter证书则忽略]proxy.cert.factory- 工厂(默认为“SunX509”)[如果使用JMeter证书则忽略]proxy.cert.alias- 要使用的密钥的别名。如果已定义,则JMeter不会尝试生成自己的证书。proxy.ssl.protocol- 要使用的协议(默认为“SSLv3”)
如果您的浏览器当前使用代理(例如公司内部网可以通过代理路由所有外部请求),那么您需要在启动JMeter之前使用命令行选项
-H和-P告诉JMeter使用此代理。运行生成的测试计划时也需要此设置。
安装用于HTTPS录制的JMeter CA证书
如上所述,在Java 8下运行时,JMeter可以为每个服务器生成证书。为了使其顺利运行,JMeter使用的根CA签名证书需要得到浏览器的信任。第一次启动录制器时,它将在必要时生成证书。根CA证书将导出到当前启动目录中名为ApacheJMeterTemporaryRootCA的文件中。设置证书后,JMeter将显示一个包含当前证书详细信息的对话框。此时,可以按照以下说明将证书导入浏览器。
请注意,一旦将根CA证书安装为可信CA,浏览器将信任由其签名的任何证书。在证书过期或证书从浏览器中删除之前,它不会警告用户证书正在被依赖。因此,任何能够获取密钥库和密码的人都可以使用证书生成这些将被任何信任JMeter根CA证书的浏览器接受的证书。因此,随机生成密钥库和私钥的密码,并使用短的有效期。密码存储在本地首选项区域中。请确保只有受信任的用户才能访问具有密钥库的主机。
启动记录器后显示的弹窗是一个信息弹窗:
记录器安装证书弹窗
只需单击“OK”然后继续。
在Firefox中安装证书
选择以下选项:
工具/选项高级/证书查看证书证书颁发机构导入...- 浏览到JMeter启动目录,然后单击
ApacheJMeterTemporaryRootCA.crt文件,点击打开 - 单击“
查看”并检查证书详细信息是否与JMeter测试脚本记录器显示的一致 - 如果正常,请选择“
信任此CA以识别网站”,然后点击确定 - 根据需要点击“
确定”关闭对话框
在Chrome或Internet Explorer中安装证书
Chrome和Internet Explorer都使用相同的信任存储区来存储证书。
- 浏览到JMeter启动目录,然后单击
ApacheJMeterTemporaryRootCA.crt文件,并将其打开 - 单击“
详细信息”选项卡,检查证书详细信息是否与JMeter测试脚本记录器显示的一致 - 如果确定,请返回“
常规”选项卡,然后单击“安装证书...”并按照向导提示进行操作
在Opera中安装证书
工具/偏好/高级/安全管理证书...- 选择“
中级”选项卡,然后单击“导入...” - 浏览到JMeter启动目录,然后单击
ApacheJMeterTemporaryRootCA.usr文件,并将其打开
HTTP(S)测试脚本录制器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 端口 | HTTP(S)测试脚本记录器监听的端口。 默认值8888,可变更。 |
是 |
| HTTPS Domains | HTTPS的域(或主机)名称列表。使用此选项可为要记录的所有服务器预生成证书。 例如, *.example.com,*.subdomain.example.com注意通配符域仅适用于一级,即 abc.subdomain.example.com匹配*.subdomain.example.com但不匹配*.example.com |
否 |
| 目标控制器 | 控制代理存储生成样本的控制器。默认情况下,它会查找录制控制器并将其存储在控制器之下。 | 是 |
| 分组 | 是否将样本分组为来自单个“点击”的请求(收到的请求没有明显的时间间隔),以及如何在记录中表示该分组:
proxy.pause决定。默认值为5000(毫秒),即5秒。如果您在使用分组,请确保在点击之间留出所需的间隔。 |
是 |
| 记录HTTP信息头 | 是否应将信息头添加到计划中?如果指定,则会将信息头管理器添加到每个HTTP取样器。代理服务器始终从生成的信息头管理器中删除Cookie和授权信息头。默认情况下,它还会删除If-Modified-Since和If-None-Match信息头。这些用于决定浏览器缓存项是否是最新的;录制时通常要下载所有内容。要更改删除的额外信息头,请将JMeter属性proxy.headers.remove定义为以逗号分隔的信息头列表。 |
是 |
| 添加断言 | 为每个取样器添加一个空白断言? | 是 |
| Regex Matching | 使用正则表达式匹配替换变量?如果选中替换将使用单词边界,即它将仅替换变量的单词匹配值,而不是单词的一部分。字边界遵循Perl5定义,等同于\b。有关“用户定义的变量替换” 的更多信息请参阅下面段落。 |
是 |
| Prefix/Transaction name | 在录制期间为样本名称添加前缀(前缀模式)。或者用用户选择的名称替换样本名称(事务名称) | 否 |
| Create new transaction after request (ms) | 考虑将两个请求分到不同组的请求间的不活动时间。 | 否 |
| Type | 要生成的样本的类型(默认HTTPClient或Java) | 是 |
| 自动重定向 | 在生成的样本中设置自动重定向? | 是 |
| 跟随重定向 | 在生成的样本中设置跟随重定向?注意:有关重要信息,请参阅下面的“录制和重定向”部分。 |
是 |
| 使用Keep-Alive | 在生成的取样器中设置使用Keep-Alive? | 是 |
| 从HTML文件获取所有内含的资源 | 设置从HTML文件获取所有内含的资源? | 是 |
| Content Type filter | 根据content-type过滤请求- 例如“text/html [;charset=utf-8 ]”。这些字段是正则表达式,检查它们是否包含在content-type中。[不必匹配整个字段]。首先检查包含过滤,然后检查排除过滤。过滤掉的样本将不会被存储。注意:此过滤适用于响应的内容类型 |
否 |
| 包含模式 | 与取样的完整URL匹配的正则表达式。允许过滤记录的请求。所有请求都会通过,但只会记录符合“Include/Exclude”字段要求的请求。如果Include和Exclude”都为空,则记录所有内容(这将导致为每个页面记录数十个样本,因为记录了图像,样式表等)。如果“ |
否 |
| 排除模式 | 与取样的URL匹配的正则表达式。不记录与一个或多个 |
否 |
| 将过滤过的取样器通知子监听器 | 将过滤过的取样器通知子监听器任何与一个或多个 |
否 |
| 启动按钮 | 启动代理服务器。一旦代理服务器启动并准备接收请求,JMeter就会将以下消息写入控制台:“Proxy up and running!”。 |
N/A |
| 停止按钮 | 停止代理服务器。 | N/A |
| 重启按钮 | 停止并重新启动代理服务器。当您更改/添加/删除包含/排除过滤表达式时,这非常有用。 | N/A |
录制和重定向
在录制过程中,浏览器将遵循重定向响应并生成额外的请求。代理将记录原始请求和重定向请求(取决于配置的任何排除)。生成的样本默认选择“跟随重定向”,因为这通常更好。
重定向可能取决于原始请求,因此重复原始记录的样本可能并不总是有效。
现在,如果JMeter设置为在重放期间跟随重定向,它将发出原始请求,然后重播已记录的重定向请求。为了避免这种重复重放,JMeter尝试检测样本是否是之前重定向的结果。如果当前响应是重定向,JMeter将保存重定向URL。收到下一个请求时,会将其与保存的重定向URL进行比较,如果匹配,JMeter将禁用生成的样本。它还为重定向链添加了注释。这假设重定向链中的所有请求将在没有任何干预请求的情况下相互跟随。要禁用重定向检测,请设置属性proxy.redirect.disabling=false
包含和排除
包含和排除模式被视为正则表达式(使用Jakarta ORO)。它们将与每个浏览器请求的主机名,端口(实际或隐含),路径和查询(如果有)进行匹配。如果您正在浏览的URL是“http://localhost/jmeter/index.html?username=xxxx”,那么针对此字符串测试正则表达式:“localhost:80/jmeter/index.html?username=xxxx”。因此,如果要包含所有.html文件,如果你知道没有查询字符串或者你只想要不带查询字符串的html页面,正则表达式可以如下所示:".*\.html(\?.*)?"或者".*\.html"。
如果存在任何包含模式,则URL必须至少与其中一个模式匹配,否则将不会记录。如果存在任何排除模式,则URL必须与任何模式都不匹配,否则将不会记录。使用包含和排除的组合,您应该能够记录您感兴趣的内容并跳过您不感兴趣的内容。
注意,正则表达式匹配的字符串必须与整个主机+路径字符串相同。 因此“
\.html” 与localhost:80/index.html不匹配
捕获二进制POST数据
JMeter能够捕获二进制POST数据。要配置将哪些content-types视为二进制,请更新JMeter属性proxy.binary.types。默认设置如下:
#这些content-types将通过将请求保存在文件中来处理:
proxy.binary.types=application/x-amf,application/x-java-serialized-object
#文件将保存在此目录中:
proxy.binary.directory=user.dir
#将使用此文件filesuffix创建文件:
proxy.binary.filesuffix=.binary
添加定时器
也可以让代理向记录的脚本添加定时器。为此,请直接在HTTP(S)测试脚本记录器组件中创建定时器。代理会将此定时器的副本放入其记录的每个样本中,如果您正在使用分组,则将其放入每个组的第一个样本中。然后将扫描该副本以查找其属性中变量${T}的出现,并且任何此类出现将被前一个样本记录的的时间间隔(以毫秒为单位)替换。
当您准备开始时,点击“启动”。
您需要编辑浏览器的代理设置以指向相应的服务器和端口,其中服务器是运行JMeter的机器,端口#来自上面显示的代理控制面板。
样本在何处被记录?
JMeter将记录的样本放入您选择的目标控制器中。如果选择默认选项“使用录制控制器”,它们将存储在测试对象树中找到的第一个录制控制器中(因此请务必在开始录制之前添加录制控制器)。
如果代理似乎没有记录任何样本,这可能是因为浏览器实际上没有使用代理。要检查是否是这种情况,请尝试停止代理。如果浏览器仍然可以下载页面,则它没有通过代理发送请求。请再次检查浏览器选项。如果您尝试从运行在同一主机上的服务器进行录制,请检查浏览器是否没有设置为“对于本地地址不使用代理服务器”(此示例来自IE7,但其他浏览器也有类似的选项)。如果JMeter不记录浏览器URL,例如http://localhost/或http://127.0.0.1/,请尝试使用非环回主机名或IP地址,例如http://myhost/或http://192.168.0.2/。
处理HTTP请求默认值
如果HTTP(S)测试脚本记录器直接在存储样本的控制器内或任何其父控制器内找到启用的HTTP请求默认值,则记录的样本将对于您指定的默认值使用空字段。您可以通过在HTTP(S)测试脚本记录器中直接放置HTTP请求默认值元件来进一步控制此行为,其非空值将覆盖其他HTTP请求默认值中的值。有关详细信息,请参阅HTTP(S)测试脚本记录器的最佳实践。
用户定义的变量替换
类似地,如果HTTP(S)测试脚本记录器直接在存储样本的控制器内或任何其父控制器内找到用户定义的变量(UDV),则记录的样本将把任何这些变量值的出现由相应的变量替换。同样,您可以将用户定义变量直接放在HTTP(S)测试脚本记录器中,以覆盖要替换的值。有关详细信息,请参阅 测试脚本记录器的最佳实践。
请注意,匹配区分大小写。
按变量替换:默认情况下,代理服务器会查找所有出现的用户定义的变量值。例如,如果您使用值www定义变量WEB,则无论在何处找到,字符串www都将被${WEB}替换。为避免在任何地方发生这种情况,请选中“Regex Matching”复选框。这告诉代理服务器将值视为正则表达式(使用ORO提供的perl5兼容的正则表达式匹配器)。
如果选中“Regex Matching”,则每个变量将被编译为包含在\b(和)\b中的perl兼容正则表达式 。这样每个匹配将以字边界开始和结束。
需要注意的是边界字符不是匹配组的一部分,例如
n.*匹配You can call me 'name'中的name。
如果你不希望你的正则表达式被限制在那些边界匹配器中,你必须将你的正则表达式包含在括号中,例如('.*?')匹配You can call me 'name'中的'name'。
将以随机顺序检查变量。因此,请确保潜在匹配不重叠。重叠匹配器可以是
.*(匹配任何东西)和www(仅匹配www)。非重叠-匹配器可以是a+(匹配a开头的一个序列)和b+(匹配b开头的一个序列)。
如果您只想匹配整个字符串,请将其括在(^和$)中,例如(^thus$)。括号是必要的,因为通常添加的边界字符将阻止^和$匹配。
如果只想在字符串的开头匹配/images,请使用值(^/images)。Jakarta ORO也支持零宽度正预测,因此可以使用(^/images(?=/))匹配/images/…但是不包含尾部的/。
注意当前版本的Jakarta ORO不支持正回顾 - 即
(?<=…)或(?<!…)。
留意重叠的匹配器。例如,作为变量名为regex的正则表达式的值.*将部分匹配先前替换的变量,这将导致类似${{regex}的内容,这很可能不是所需的结果。
如果将任何变量解释为模式存在任何问题,则会在jmeter.log中报告这些问题,因此如果用户定义的变量未按预期工作,请务必检查此问题。
完成录制测试样本后,停止代理服务器(点击“停止”按钮)。请记住重置浏览器的代理设置。现在,您可能希望对测试脚本进行排序和重新排序,添加定时器,监听器,cookie管理器等。
我怎样才能同时记录服务器的响应?
只需将查看结果树监听器作为HTTP(S)测试脚本记录器的子项放置,就会显示响应。您还可以添加保存响应到文件后置处理器来将响应保存到文件。
将请求与响应相关联
如果定义属性proxy.number.requests=true, JMeter将为每个取样器和每个响应添加一个数字。注意如果使用了排除或包含,可能会有比取样器更多的响应。已被排除的响应将被包含在[和]标签中,例如[23 /favicon.ico]。
Cookie管理器
如果您要测试的服务器使用cookie,请记住在完成记录后将HTTP Cookie管理器添加到测试计划中。在录制期间,浏览器会处理任何cookie,但JMeter需要Cookie管理器在测试运行期间处理cookie。JMeter代理服务器在记录期间传递浏览器发送的所有cookie,但不会将它们保存到测试计划中,因为它们每次运行时通常会变化。
授权管理器
HTTP(S)测试脚本记录器抓取“Authentication”信息头,尝试计算身份验证策略。如果授权管理器手动添加到目标控制器,HTTP(S)测试脚本记录器将找到它并添加授权(匹配的将被删除)。否则,授权管理器将添加到具有授权对象的目标控制器。您可能必须在录制后修改自动计算的值。
上传文件
某些浏览器(例如Firefox和Opera)在上传文件时不包含文件的全名。这可能导致JMeter代理服务器失败。一种解决方案是确保要上传的任何文件都在JMeter工作目录中,可以将文件复制到工作目录或在包含文件的目录中启动JMeter。
记录JMeter中原生不支持的基于HTTP的非文本协议
您可能要记录JMeter默认不处理的HTTP协议(自定义二进制协议,Adobe Flex,Microsoft Silverlight,...)。虽然JMeter不提供记录这些协议的原生代理实现,但您可以通过实现自定义SamplerCreator来记录这些协议。此取样器生成器可以将二进制格式转换为可添加到JMeter测试用例的HTTPSamplerBase子类。有关更多详细信息,请参阅“扩展JMeter”。
HTTP镜像服务器
HTTP镜像服务器是一个非常简单的HTTP服务器 - 它只是镜像发送给它的数据。这对于检查HTTP请求的内容很有用。
它使用默认端口为8081。

HTTP镜像服务器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| 端口 | 镜像服务器监听的端口,默认为8081。 |
是 |
| 最大线程数 | 如果设置为值>0,服务请求的线程的数目将被限制在配置数的范围内,如果设置为值≤0一个新的线程将被创建以服务于每个传入请求。默认值为0 |
否 |
| 最大队列长度 | 用于在线程池执行任务之前保留任务的队列大小,当超出线程池时,传入的请求将保留在此队列中,并在此队列满时被丢弃。仅当最大线程数大于0时才使用此参数。默认为25 |
否 |
注意通过添加具有以下名称/值对的HTTP信息头管理器,您可以更好地控制响应:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| X-Sleep | 在发送响应之前以ms为单位休眠的时间 | 否 |
| X-SetCookie | 响应时设置Cookie | 否 |
| X-ResponseStatus | 响应状态,请参阅HTTP响应状态,例如200 OK,500内部服务器错误,.... | 否 |
| X-ResponseLength | 响应大小,如果小于总大小,则会将响应调整为所请求的大小 | 否 |
| X-SetHeaders | |分隔的信息头列表,例如:headerA=valueA|headerB=valueB将headerA设置为valueA,headerB设置为valueB。 |
否 |
您还可以使用以下查询参数:
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| redirect | 使用提供的位置生成302(临时重定向)。例如?redirect=/path |
否 |
| status | 覆盖默认返回状态。例如?status=404 Not Found |
否 |
| v | 详细标志,将一些细节写入标准输出。例如,指定第一行和重定向位置 | 否 |
属性显示
属性显示显示系统或JMeter属性的值。可以通过在“值”列中输入新文本来更改值。
属性显示控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
调试取样器
调试取样器生成一个包含所有JMeter变量和/或属性值的样本。
可以在查看结果树监听器响应数据窗格中查看这些值。
调试取样器控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| JMeter属性 | 包括JMeter属性? | 是 |
| JMeter变量 | 包括JMeter变量? | 是 |
| 系统属性 | 包括系统属性? | 是 |
调试后置处理程序
调试后置处理程序创建一个子样本,其中包含之前取样器属性,JMeter变量,属性和/或系统属性的详细信息。
可以在查看结果树监听器响应数据窗格中查看这些值。
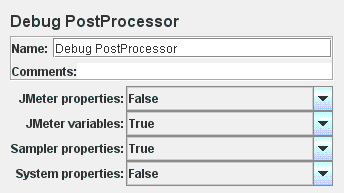
调试后置处理程序控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 否 |
| JMeter属性 | 是否显示JMeter属性(默认为false)。 |
是 |
| JMeter变量 | 是否显示JMeter变量(默认为false)。 |
是 |
| 取样器属性 | 是否显示Sampler属性(默认为true)。 |
是 |
| 系统属性 | 是否显示系统属性(默认为false)。 |
是 |
测试片段
测试片段与Include控制器和模块控制器一起使用。

测试片段控制面板的截图
参数
| 属性 | 描述 | 是否必须 |
|---|---|---|
| 名称 | 树中显示的此元件的描述性名称。 | 是 |
将测试片段与模块控制器一起使用时,请确保禁用测试片段以防止执行测试片段本身。JMeter 2.13之后默认禁用。
setUp线程组
一种特殊类型的线程组,可用于执行测试预操作。这些线程的行为与普通的线程组元件完全相同。不同之处在于这些类型的线程在测试过程中在常规线程组执行之前执行。
setUp线程组控制面板的截图
tearDown线程组
一种特殊类型的线程组,可用于执行测试后操作。这些线程的行为与普通的线程组元件完全相同。不同之处在于这些类型的线程在测试过程中在常规线程组执行后执行。
tearDown线程组控制面板的截图
注意默认情况下,测试正常结束时它是不会运行,如果要在此情况下运行它,请确保在测试计划元件上选中“
主线程结束后运行tearDown线程组”选项。如果测试计划被停止,即使选中选项,tearDown也不会运行。
图1 - 主线程结束后运行tearDown线程组
Comments